
Десять лет назад, когда МФК «Лайм-займ» только начинала работу на рынке выдачи онлайн-займов, о применении сервисов, основанных на машинном обучении (machine learning, ML), в бизнес-процессах ещё и не шло речи. Однако сегодня внедрение передовых разработок и технологических новинок, включая ML, — это условие выживания и масштабирования микрофинансовой компании. Руководитель отдела наукоемкой разработки МФК «Лайм-займ» Дамир Якупов рассказал, как происходила эволюция ML-сервисов в секторе МФО.
Данные — основа всего
Микрофинансовые организации не существуют в вакууме. Они работают в свободном экономическом пространстве, где на них влияет огромное множество факторов: структура экономики, требования регуляторов, потребительское поведение, конкурентная среда, источники данных, социокультурные особенности, доходы населения и технологическая среда. Факторы имеют одну характерную особенность, и для последнего десятилетия её можно назвать так: они все зависят от данных.
Американский писатель Дэвид Брукс в своей колонке 2013 года для The New York Times первым использовал термин «датаизм». Это философская парадигма, которая рассматривает все объекты реального мира через призму того, какие данные они создают и как эти данные на протяжении жизненного процесса объекта сопровождают его.
На мой взгляд, данные — основной драйвер, который влияет на внешние факторы, воздействующие на МФО. То есть данные, скорость их получения, обработки, их хранение и передача имеют определяющее значение.
Скоринг клиентов в МФО
Ситуация меняется стремительно: данных всё больше. Из-за растущей конкуренции в секторе растут и требования к качеству собираемой информации, количеству источников, скорости обработки и передачи. Компании стали стремиться делать предложения более персональными, чтобы обходить конкурентов и при этом быть экономически эффективными.
При таких условиях старые модели, подходы и инструменты перестали быть эффективными. И всё, что в бизнес-процессах поддается дигитализации (оцифровке), оказалось готово для использования механизмов и сервисов, построенных в том числе на базе искусственного интеллекта. Так ML-сервисы стали внедряться в самые разные отрасли, включая МФО.
Первый процесс, в котором микрофинансовые компании стали задействовать ML-сервисы, — это скоринг клиентов. Вслед за ним сервисы на основе machine learning стали проникать и во вспомогательные процессы: коллекшн, судебное производство и др. Этот тренд характерен как для всей отрасли, так и для нашей компании в частности.
На первом этапе, когда компания была создана, у нас не было как такового машинного обучения. Были достаточно понятные, хорошо интерпретируемые, но простые и не особо селективные правила.
На втором этапе машинное обучение начало внедряться в скоринге как в одном из самых востребованных направлений с точки зрения применения прогрессивных технологий оценки. Это были базовые алгоритмы: регрессии и деревья решений.
Позже, на третьем этапе, при помощи ML мы начали анализировать антифрод и проводить детекцию аномалий.
На четвертом этапе машинное обучение начало распространяться во вспомогательные подразделения: например, коллекшн и судебное взыскание.
На пятом этапе мы начали экспериментировать с персонализацией, с применением нейронных сетей, т.е. начали использовать технологии, которые идут на некоторый компромисс с интерпретируемостью, но дают более высокую бизнес-эффективность.
По теме: Машины не восстанут, но вылететь с работы можно: разбираемся, зачем осваивать нейросети
Переход к каскадным системам
С более глубоким проникновением машинного обучения в бизнес-процессы нашей компании, с расширением контекста и усложнением логики появилась потребность трансформировать систему принятия решений, и простые линейные алгоритмы сменились каскадными системами.
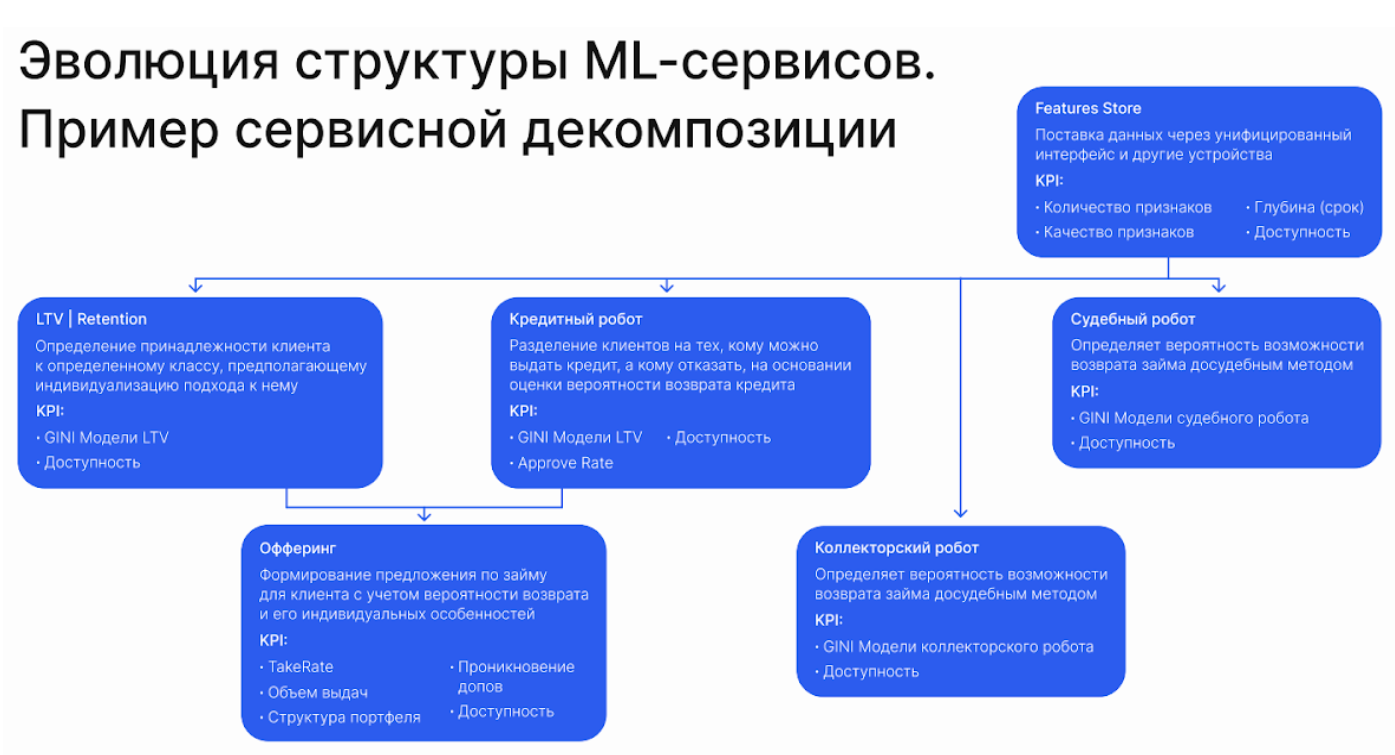
Со временем мы стали замечать у наших сервисов дублирующиеся блоки. Для эффективного управления ими мы начали объединять их в отдельные продуктовые (features store, кредитный робот, коллекторский и судебные роботы, LTV, офферинг) и технические (мониторинг и логирование, CI\CD + MLOps) логические сервисы.
Также при изменении структуры мы учли и новые требования рынка. Если раньше мы могли ждать принятия решения по несколько минут, иногда до получаса, то сейчас это время сократилось. Решение нужно принимать в течение нескольких секунд, иначе конверсия начинает резко падать.
По теме: Следующий этап развития нейросетей: что такое интерактивный ИИ и почему он «умнее» генеративного
ML-команда вместо одинокого Data scientist
Чем сложнее становится система, тем больше появляется задач, тем глубже каждая из областей обработки и подготовки решения. Один специалист перестает справляться, и тогда команда разрастается в соответствии с потребностями бизнеса.
В самом начале в R&D отделе нашей компании была только одна роль — Data scientist, который сам готовил себе данные, делал research, связанный с поиском оптимальных моделей, обучал модели, осуществлял performance различных показателей и представлял отчёты.
Сейчас команда выглядит совсем по-другому. Кто в ней есть:
- data engineer, который занимается подготовкой данных, ETL, сбором данных из источников и их приведением в машиночитаемый вид;
- feature engineer, который придумывает то, каким образом данные превратить в признаки, описывающие реальный объект или субъект (в нашем случае — заёмщика);
- software engineer, который обеспечивает реализацию сервисов на базе подготовленных моделей;
- MLOps engineer — новая и интересная роль, аналогичная DevOps engineer. Этот специалист работает в сфере Data science, обеспечивает автоматизацию пайплайнов, обучение и переобучение моделей, мониторинг, реализацию ряда автоматических расчётов и доставки сервисов машинного обучения до конечного прод-состояния.
Новая структура работы сервиса
Внедрение ML-сервисов в деятельность микрофинансовых компаний не могло не сказаться на всех последовательных бизнес-процессах. Сегодня ML-специалисты вовлекаются на всех этапах проекта: это и инициация проекта, и этап подготовки данных, и проведение эксперимента, и этап эксплуатации, и дальнейшие мониторинг и переобучение моделей.
Поскольку речь идёт о сфере финтеха, теперь одним из важных преимуществ становится то, насколько быстро система адаптируется под внешние условия и как быстро команда настраивает процессы так, чтобы модели работали эффективно.
Из-за регуляторных особенностей сектора мы постепенно пришли к выводу, что для нас наилучшим решением станет собственная инфраструктура (MLOPs-платформа), которая позволит нам более гибко работать над улучшением и автоматическим переобучением всех взаимосвязанных сервисов в нашем большом перечне: от антифрод-моделей и моделей расчёта долговой нагрузки до ряда технических сервисов. Прямо сейчас мы работаем над воплощением нашей идеи в жизнь.
По теме: Айтишники теперь гуманитарии? Как ИИ изменил агентский рынок
Как внедрить ML-сервисы в компании: практические советы
Прежде всего, необходимо понять, что каждая компания, которая хочет внедрить ML-сервисы в свою работу, может находиться в разной отправной точке: на разной стадии зрелости команды и бизнес-процессов.
Первый шаг для любой организации, которая заинтересована в ML-системах, — провести внутренний аудит и определить уровень готовности к внедрению новшеств в процессы.
Совет: для определения своего положения компания может воспользоваться шкалой зрелости MLOPs-систем, которую ранее предложил Google. Если вкратце, то существует всего пять уровней зрелости:
- Ручной — когда все модели обработки данных создаются и обучаются инженерами вручную.
- Повторяемый — когда в системе появляются репозитории.
- Воспроизводимый — действует feature store и репозиторий моделей.
- Автоматизированный — появляется A/B-тестирование действующей модели и новой модели.
- Непрерывно совершенствующийся — система обучается повторно в автоматическом режиме при появлении триггеров из системы мониторинга.
В зависимости от того, какой точке на шкале соответствует ситуация в компании, определяется дальнейшая траектория развития и, соответственно, закладываются ресурсы. Например, на поиск MLOps-инженера или создание репозитория.
Второй шаг для успешного внедрения ML-систем и сервисов рекомендуем оценить собираемые компанией данные и их состояние. Необходимо понять, какими данными располагает команда, в каком объёме, в каком состоянии они находятся на момент аудита. В зависимости от результатов такого аудита определяется дальнейшая стратегия: одной компании потребуется составить план «наведения порядка» в базах данных, другие будут готовы автоматизировать процессы и подбирать подходящие ML-модели.
Совет: существует специальный подход — Data Governance, включающий в себя несколько практик: сбора, обработки, контроля качества данных, описания метаданных и так далее. Фактически основной настольной книгой для оценки ситуации с данными может быть Data management body of knowledge — свод знаний по управлению данными. В ней есть практические рекомендации по тому, что должно быть в организации для качественной работы с данными, на основе которых будут приниматься решения.
Третий шаг — посмотреть состав команды и заложить дальнейшее её развитие так, чтобы уходить от универсальных специалистов к узконаправленным профессионалам, которые будут погружены в контекст деятельности конкретно вашей компании.
Каких специалистов нужно будет добавлять в команду, зависит, во-первых, от задач, во-вторых, от зрелости процессов. Если зрелость MLOPs-процессов невысокая, а компания настроена на разработку собственной MLOPs-платформы, то нужно делать упор на поиск DataOps-инженеров, MLOPs-инженеров и DevOps-инженеров. На период эксплуатации системы число ролевых позиций может быть сокращено.
Совет: MLOPs — молодая отрасль, поэтому на рынке существуют в основном базовые универсальные решения, которые могут подойти на этапе маленькой готовности компании к внедрению ML-сервисов. Со временем ML-системам будут требоваться более сложная инфраструктура и узкие навыки специалистов.
С учетом того, что на рынке нет и не будет единого решения, которое работает для всех одинаково качественно, поскольку у каждой отрасли своя специфика, компаниям нужно не столько обращаться к сторонним ресурсам и подрядчикам, сколько начинать растить собственную команду профессионалов. Они будут более адресно работать с моделями и налаживать систему с учётом особенностей деятельности конкретного бизнеса. Это, несомненно, положительно скажется на быстром и автоматизированном принятии решений и улучшении бизнес-показателей.
Фото на обложке: ddraw /
Подписывайтесь на наш Telegram-канал, чтобы быть в курсе последних новостей и событий!
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 AI для HR: профиль кандидата, который повысит скорость найма в два раза
- 2 Машины не восстанут, но вылететь с работы можно: разбираемся, зачем осваивать нейросети
- 3 Мнение эксперта: Игорь Пивоваров о том, что происходит с OpenAI
- 4 «Доверять нельзя бояться». Как работают нейросети в беспилотных автомобилях
- 5 От секретаря до бухгалтера: как NLP помогает сокращать издержки бизнеса
ВОЗМОЖНОСТИ
29 апреля 2024
30 апреля 2024