
Задумывались ли вы когда-либо над тем, насколько хорошо работает пятизвездочная система оценивания мобильных приложений, скажем, в AppStore? До какой степени количество звезд, полученное тем или иным приложением, является показателем его качества? Почему представленный ниже явно отрицательный отзыв идет с оценкой «5», и насколько часто имеют место подобные случаи «неадекватного» оценивания приложений? 
Мы – исследовательское подразделение компании Empatika – сделали попытку ответить на эти вопросы и пришли к неутешительному выводу: пользователи AppStore демонстрируют явно выраженную склонность к более частому выставлению положительных оценок, чем отрицательных, зачастую совершенно не заботясь о соответствии текста своего отзыва выставленному вместе с ним количеству звезд. Этот результат нашего исследования не так давно был опубликован на TechCrunch.
План исследования
Базой для нашего исследования послужили англоязычные отзывы к 10 наиболее популярным бесплатным приложениям в AppStore (исключая приложения от Apple):
- YouTube
- Path
- Foursquare
- Spotify
- Chrome
- Google Earth
Количество проанализированных нами в общей сложности ревью составило около 500 000 – серьезный объем данных! С помощью такой большой выборки мы намеревались выявить наиболее активных ревьюеров в AppStore и проверить нашу гипотезу о том, что значительная их часть проявляет склонность к выставлению преимущественно положительных или отрицательных оценок. Тут, однако, нам в голову пришла идея подойти к предмету исследования немного с другой стороны и проверить еще одно не менее любопытное наше подозрение. А соответствуют ли вообще оценки пользователей тому, что они пишут в своих ревью?
Соответствие эмоциональной окраски review и его пятибалльной оценки
Вспомним пример ревью из начала статьи. Этот отзыв идет с оценкой «5», однако по эмоциональной окраске его явно следует отнести к отрицательным. Можем ли мы выявить долю таких «неадекватных» оценок среди отзывов на рассматриваемые нами приложения? Да, если
выполним сентимент-анализ (анализ эмоциональной окраски) текстов ревью. Конечно, придется мириться c тем, что сентимент-анализ, как правило, не может быть выполнен со 100%-ной точностью – однако доля ошибок при решении этой задачи обычно не превышает 20%, а значит, подсчитанная нами доля «неадекватных» ревью будет иметь незначительную погрешность в ±10%.
Для проведения анализа мы исключили из рассмотрения отзывы с оценкой «3» как такие, для которых нельзя однозначно определить положительную или отрицательную окраску текста. Из оставшихся ревью «адекватными» считались те, которые были положительно окрашены и имели оценки «4» и «5», либо те, которые были отрицательно окрашены и имели оценки «1» и «2». Так как ревью в AppStore состоит из двух частей (заголовка и тела), сентимент-анализ проводился в трех вариантах:
1. Только для тела ревью;
2. Только для заголовка ревью;
3. Для тела и заголовка в совокупности; тело при этом входило в оценку с весом 75%, заголовок – с весом 25%.
Задача определения эмоциональной окраски текста обычно решается с помощью алгоритмов классификации текстов. В нашем случае мы имеем дело всего с двумя классами: положительно и отрицательно окрашенными текстами. В основе классификаторов, как правило, лежат алгоритмы машинного обучения, и качество их работы сильно зависит от размера и содержания обучающих выборок. Именно поэтому для большей достоверности результатов сентимент-анализ был проведен дважды, сначала – на разработанном нами классификаторе, обученном на отзывах из foursquare (этот классификатор сейчас успешно применяется в нашемприложении App in the Air), затем – на классификаторе из библиотеки NLTK, обученном на стандартном для таких задач корпусе текстов «movie reviews».
Так какова же доля тех отзывов, которые по содержанию (читай – эмоциональной окраске) соответствуют идущей с ними оценке? Вот результаты, полученные на нашем классификаторе:
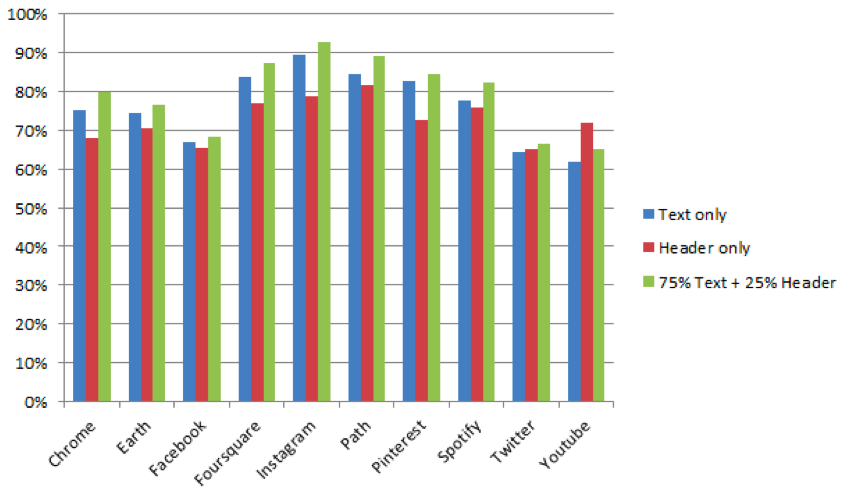
Результаты, полученные на классификаторе NLTK: 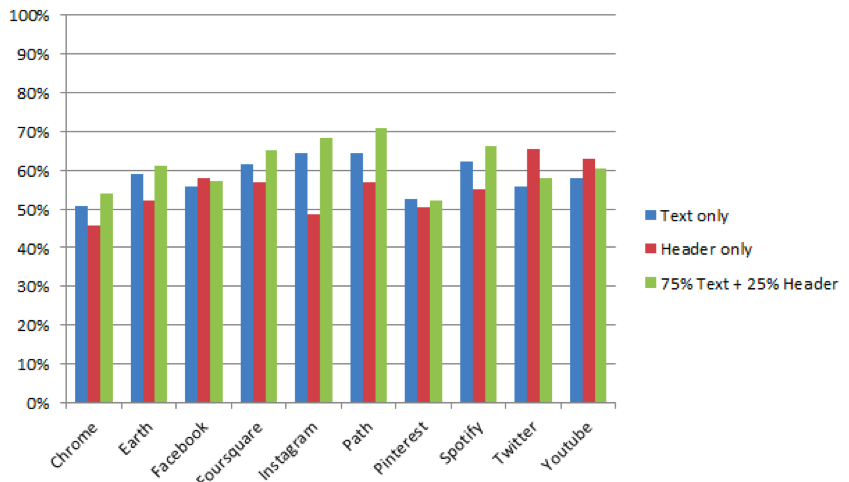
Результаты, полученные на двух разных классификаторах, во многом случаях схожи. Можно обратить внимание, например, на наибольшую среднюю «адекватность» ревью для приложений Instagram и Path (в случае расчетов по схеме «75% тело + 25% заголовок»). С другой стороны, сентимент-анализатор NLTK выдает в среднем несколько более низкие результаты, чем наш классификатор. Это отчасти можно объяснить тем, что наш классификатор более развит, чем базовый классификатор из NLTK. Он также является наивным Байесовским классификатором, но, в отличие от применяющегося в NLTK, способен анализировать отрицательные частицы в предложениях и выявлять наличие в них смайлов.
Оба результата в совокупности наглядно демонстрируют, что в среднем около трети пользователей пишут ревью, не соответствующее по эмоциональной окраске выставленной ими оценке.
Проверка гипотезы о «предвзятости» ревьюеров
Перейдем к анализу изначально поставленного нами вопроса. Можем ли мы утверждать, что пользователи AppStore имеют склонность чаще ставить высокие (или низкие) оценки?
Выборка пользователей для исследования была осуществлена следующим образом. Мы определили список пользователей, оставивших ревью к трем или более приложениям из списка top-10, и выделили из AppStore все их ревью (отметим, что теперь это совсем не обязательно отзывы к приложениям из «топа»). Затем мы отобрали только тех пользователей, которые имели в своем активе пять и более ревью. Всего таких пользователей оказалось 218 человек, а среднее число ревью на одного пользователя составило 39.
Распределение средних оценок по пользователям дало нам основание предполагать, что для нашей выборки «активных» пользователей характерны завышенные оценки:
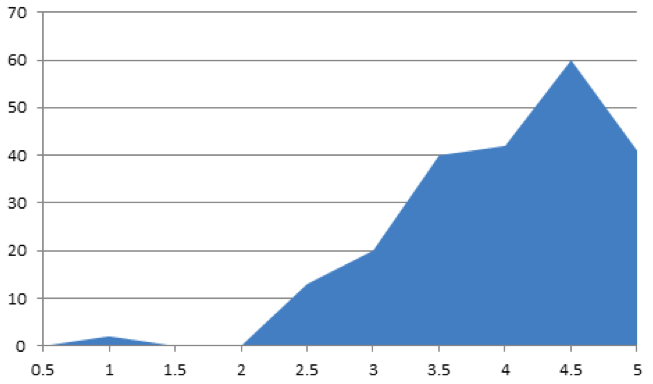
Какова же доля пользователей, у которых средняя оценка по всем их ревью сильно завышена? К ответу на этот вопрос мы подошли формально – в терминах проверки гипотез. Для формулировки и проверки соответствующих гипотез были использованы методы и критерии, широко распространенные в математической статистике; в следующих абзацах мы довольно подробно опишем применение этих методов. Если вас не интересуют детали – эти абзацы можно пропустить.
Первым шагом мы для каждого пользователя из выборки проверили гипотезу о том, что его оценки распределены равномерно, используя критерий «Хи-квадрат». Вышеприведенный график плотности распределения средних оценок пользователей давал нам все основания предположить, что для подавляющего большинства пользователей гипотеза о равномерности распределения их оценок должна быть отвергнута. Тест «Хи-квадрат» подтвердил это – гипотеза о равномерности распределения оценок была принята только для 1% пользователей из выборки (на уровне значимости 5% – этот же уровень значимости мы использовали и при проверке остальных гипотез).
Как же сформулировать в терминах проверки гипотез предположение о том, что оценки пользователя завышены? Исходя из того, что завышенными оценками мы считаем «4» и «5», мы приняли решение о проверке основной гипотезы о том, что средняя оценка пользователя равна 4.5, против альтернативной о том, что средняя оценка меньше 4.5. Напомним, что гипотезы подобного рода проверяются с помощью расчета на основе наблюдений так называемой t-статистики: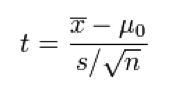
– которая затем сверяется с соответствующим размеру выборки и уровню значимости «критическому значению» t-распределения, которое можно найти в статистических таблицах.
Здесь, однако, мы встретились с одним небольшим затруднением: дело в том, что проверку гипотезы о среднем с помощью t-статистики мы можем проводить только в случае нормальной распределенности наших наблюдений. Имеем ли мы право делать предположение о нормальности для нашей дискретной выборки, каждое наблюдение в которой может принимать одно из пяти значений – большой вопрос. Чтобы обосновать это предположение, мы провели для каждого из пользователей в нашей выборке тест Харке-Бера, проверяющий наблюдения на нормальность посредством проверки их симметричности относительно выборочного среднего, а также анализа эксцесса (меры остроты пика распределения). Тест прошли 56% пользователей.
В предположении же о нормальности наблюдений посчитать для каждого из пользователей значение t-статистики и проверить гипотезу о том, что среднее по его оценкам равно 4.5 – дело техники. В случае нашей выборки эта основная гипотеза была принята в 52% случаев – результат впечатляющий, ведь он позволяет нам сделать следующий вывод: около половины пользователей проявляют большую склонность к выставлению положительных оценок, чем отрицательных. В то же время этот результат заставляет нас серьезно задуматься: а каковы же причины завышенности оценок у такой большой доли пользовательской аудитории? Означает ли это, что пользователи в принципе завышают свои оценки? Или предпочитают оценивать более качественные приложения? А может быть, это результат политики Apple, которая не пропускает на
AppStore некачественные приложения? Или результат того, что многие приложения предлагают пользователю оставить ревью только через определенное время пользования, повышая тем самым вероятность получения положительных отзывов?
Для интереса мы также проверили аналогичную гипотезу о заниженности пользовательских оценок (формально – основную гипотезу о том, что среднее по оценкам равно 1.5, против альтернативной о том, что среднее больше, чем 1.5). Эта гипотеза ожидаемо была принята лишь для 5% пользователей из нашей выборки.
Заключение
Описанные выше результаты убедительно демонстрируют, что одна лишь средняя оценка приложения в магазине, подобном AppStore, никак не может быть адекватным показателем его качества. Очень может быть, что эта оценка на самом деле завышена – ведь наши исследования показали, что пользователи гораздо чаще оставляют отзывы с положительной оценкой, чем с отрицательной. Более того, многие ревьюеры не снижают свою оценку даже в случае наличия в тексте отзыва обоснованных претензий к приложению.
Особенно важен этот результат для разработчиков мобильных приложений: для них он означает необходимость более детального анализа уровня удовлетворенности пользователей путем мониторинга ревью, отслеживания динамики изменения в этих ревью основных настроений. Один из возможных способов решения этой задачи – выделение из множества отзывов ключевых словосочетаний и анализ эмоциональной окраски отзывов, которые эти ключевые словосочетания содержат (ниже – пример подобного анализа отзывов приложения YouTube). Собственно, именно в процессе решения этой задачи мы обратили внимание на то, что между содержанием отзывов и идущими с ними оценками существует определенное несоответствие.

Не менее важной задачей для разработчиков мы видим и использование дополнительных путей получения обратной связи: например, посредством e- mail или анализа социальных сетей вроде facebook или twitter. Ведь без этих дополнительных источников довольно велик риск «недополучить» отрицательных отзывов и так и не достичь четкого понимания того, чего пользователи ждут от приложения в будущем.
В заключение очертим возможные направления будущих исследований. Интересен, например, следующий вопрос: зависит ли среднее настроение пользовательских отзывов от того, является ли приложение платным или бесплатным? Верна ли гипотеза о том, что пользователи, заплатившие деньги за приложение, чаще будут ругать его, если их что-то в нем не устраивает? А
насколько различается средний балл по разным категориям приложений? Можем ли мы утверждать, например, что игры чаще получают положительные отзывы, чем бизнес-приложения?
На все эти вопросы мы постараемся ответить в ближайшем будущем.
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 SEO для локального бизнеса: как выйти на первые позиции в поиске по регионам
- 2 «Проблема в нехватке мозгов»: почему нейросети не заменят старших разработчиков
- 3 Почему ваша программа лояльности не работает: 5 причин
- 4 Как загрузить приложения, которых нет в сторах
- 5 «Так рано?»: как просить отпуск на новой работе
ВОЗМОЖНОСТИ
25 апреля 2024
26 апреля 2024
29 апреля 2024