
Некоторые данные, вроде нашего местоположения и лайков в Facebook, кажутся нам незначительными. Но на самом деле на их основе можно получить уникальную информацию.
В работе с большими объемами данных слабо изучен один необычный вопрос — что можно сделать с информацией, на которую обычно не обращают внимания и зачастую считают лишней? Такой тип информации называют «побочной». К нему относятся данные, возникающие во время других процессов.
Большая часть данных финансового рынка представляет собой результаты договора двух сторон о стоимости продажи того или иного имущества. Запись цены на тот момент является побочной информацией. Не так давно данные подобного типа интересовали только историков экономики и законодательные органы.
Но теперь многие крупные банки и хедж-фонды используют эти огромные исторические архивы в качестве «испытательного полигона» для алгоритмов машинного обучения. Их торговые механизмы «обучаются» по этой истории. Большая часть мировой торговли работает именно благодаря полученным ими знаниям.
История традиционных транзакций, таких как изменение стоимости продажи дома или акций, относится к одной из форм временных данных. Но алгоритмы учитывают не только ее, но и другую нетрадиционную информацию, которая никак не связана с хронологией.
Например, механизмы отслеживают информацию об отношениях из социальных сетей, используют геолокационные данные для составления карт и пользуются результатами различных опросов, чтобы определить мнение людей. Но временные или продольные данные, пожалуй, самый распространенный и простой вид информации.
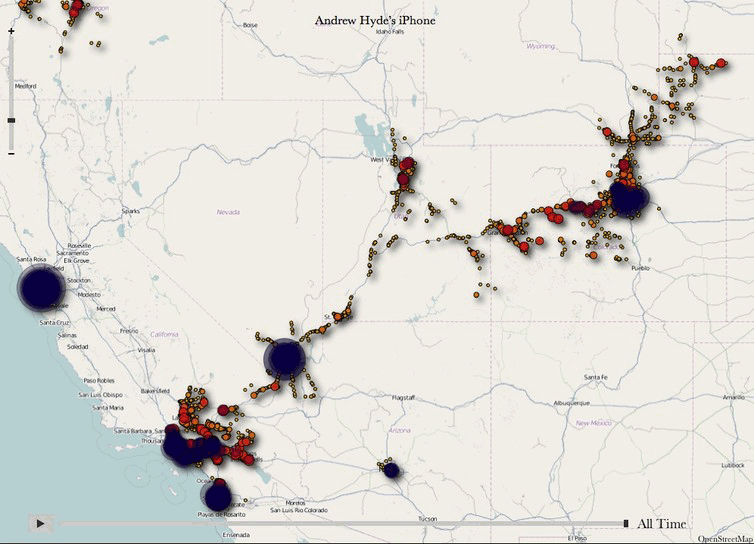
Многие компании используют данные о местоположении с мобильных телефонов. Фото: The Conversation, пользователь Flickr .
К последовательным продольным нетрадиционным побочным данным (сокращенно с английского CLUE) относится следующее:
- Данные о посещаемости
- Информация о тратах потребителя
- Данные со снимков спутника
- Биометрические характеристики
- Данные о пересылке товаров, приобретенных через интернет
- Информация об использовании технологии
- Данные об удовлетворенности сотрудников
Представьте, что вы хотите узнать, какую прибыль приносят супермаркеты в разное время года. Большая посещаемость не всегда приводит к высокой прибыли, ведь если в магазине много людей, не факт, что они вообще что-то купят. Тем не менее данные о посещаемости статистически связаны с объемами продаж и могут служить хорошим признаком для составления общей картины, подобно тому как температура тела свидетельствует о здоровье человека в целом. Если с помощью технологий анализа данных объединить эту информацию с большим количеством других данных, можно получить ценную информацию.
Появление «количественных» инвестиционных фондов
Один из лидирующих хедж-фондов BlackRock использует снимки Китая со спутника, которые создаются каждые пять минут. С их помощью он анализирует промышленную активность.
По традиции, в финансовом мире все разделяются на две роли — трейдеры, которые хотят заработать на больших объемах мелких транзакций, и инвесторы, которые хотят заработать на небольшом количестве крупных долгосрочных ставок. Инвесторов обычно больше заботит базовый актив. Когда речь идет об акциях компании, это обычно значит, что они пытаются понять базовую или основную стоимость компании и ее дальнейшие перспективы, основываясь на продажах, расходах, активах, денежных обязательствах и прочем.

Схема посещаемости арт-центра Трамвэй в Глазго за последние девять лет. Фото: The Conversation, пользователь Flickr Кайл Макквэри.
Сейчас начинают появляться фонды нового типа, которые используют вычислительные ресурсы компьютерной статистики и фундаментальный анализ. Такие фонды можно назвать количественными. С помощью продвинутого машинного обучения и разнообразных источников традиционных и нетрадиционных данных они могут предсказывать основную стоимость активов и несоответствия на рынке.
Некоторые из этих фондов нового типа уже добились значительных успехов, например Two Sigma из Нью-Йорка и лондонский Winton Capital. Фонд Winton был основан Дэвидом Хардингом, который окончил факультет физики Кембриджского университета в 1997 году. Спустя два десятка лет его фонд входит в десятку лучших хедж-фондов мира. В активах Winton Capital $33 миллиарда, в фонде работает более 400 человек, большинство из которых является специалистами в области физики, математики и компьютерных наук. Two Sigma не отстает — его доля в активах составляет $30 миллиардов, и в нем также работает множество технических талантов.
Появляются и новые фонды такого типа, например, Taaffeite Capital Management под руководством Десмонда Лана, профессора вычислительной биологии из Мельбурнского университета. Понимание динамики сложных данных в разных областях естественной науки (включая биологию и экологию) позволяет составлять общую картину динамики финансового рынка.

Фотографии с дронов и новых недорогих спутников — новый основной источник нетрадиционных данных. Фото: пользователь Flickr BxHxTxCx]
Нетрадиционные данные для всех
Но нетрадиционными данными могут пользоваться не только лучшие хедж-фонды мира. Некоторые стартапы решили сделать так, чтобы источники такой информации были доступны для всех. Майкл Бабино, соучредитель и генеральный директор стартапа Second Measure, хочет создать нечто вроде информационной системы Bloomberg, которая предоставит доступ к данным о потребительских покупках. Система сможет структурировать все непонятные данные из выписок по банковским картам. Полученной информацией смогут легко воспользоваться предприниматели и инвесторы.
Другие компании, такие как Mattermark в Сан-Франциско и CB Insights в Нью-Йорке, создали специальные разведывательные службы, с помощью которых можно узнать много всего интересного и полезного «из-за кулис» различных организаций. Благодаря им можно предугадать дальнейший успех компании, особенно это полезно для рискованных случаев венчурных инвестиций.
Десять лет назад разработчик Адриан Головатый создал онлайн-карту Чикаго, где отметил места всех произошедших криминальных случаев и прочую полезную статистику. Сиднейский проект Microburbs позаимствовал его идею и составил точную карту с важной информацией о городских районах Австралии. На этой карте потенциальные новые жители и инвесторы могут увидеть и сравнить данные о школах, ресторанах и прочих элементах инфраструктуры в конкретных районах.
Проект We Feel, созданный Сесиль Пэрис, исследовательницей из Государственного объединения научных и прикладных исследований, изучает эмоциональное состояние мира по данным различных социальных сетей (в особенности Twitter).
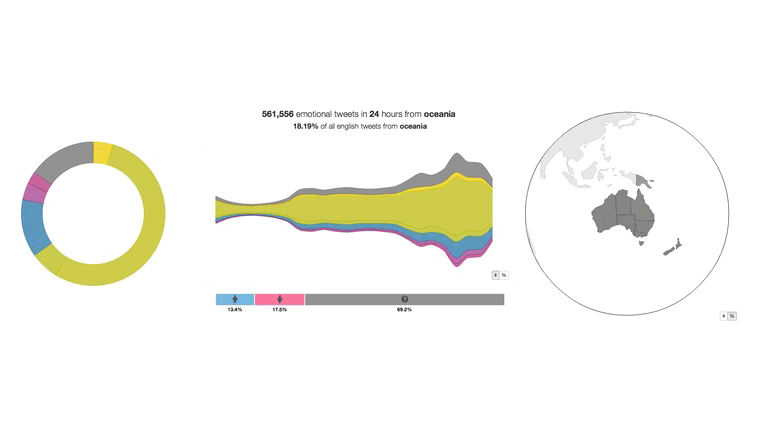
We Feel — исследовательский проект, который отслеживает по твитам эмоциональное состояние людей по всему миру. Фото: The Conversation, CSIRO
Плюсы и риски нетрадиционной информации
Проект Freakonomics (2005) показал, как нетрадиционные, но качественные источники данных могут помочь в получении инсайдерской информации. Так, одно исследование показало, что во время определенных праздников люди берут больше печенья из открытой коробки в офисе (возможно, из-за того, что это трудное финансовое время). Благодаря анализу счетов наркоманов выяснилось, почему большинство из них живет со своими бабушками или дедушками (им не хватает денег на самостоятельное проживание). А записи из школ Чикаго показали, что оценки учеников напрямую зависят от количества внимания, которое уделяют родители своим детям.
Большая часть таких результатов проекта Freakonomics была основана на небольших образцах нетрадиционных данных. Однако многие ученые считают, что исследования мелких образцов данных показывают лишь некоторые проблемы. До конца неясно, какие образцы используются — большие или абсолютно случайные.
Кроме того, существует проблема возможных ошибок. Некоторые полагают, что в малом образце данных можно допустить меньше ошибок, но, как показал недавний анализ академических работ по психологии, почти в половине случаев наблюдается значительное несоответствие информации и ошибки. Иногда причиной ошибок было небрежное отношение авторов, а иногда неточности возникали из-за неправильного перевода и прочих простых ошибок.
Нетрадиционную информацию становится все легче найти
Сейчас появляется все больше и больше сборщиков масштабных нетрадиционных данных. Вот три фактора, влияющих на их развитие:
- Увеличение количества взаимодействий в сети (покупки онлайн, электронная почта, социальные сети и т.д.).
- Увеличение количества записей об электронных транзакциях в сети
- Развитие интернета вещей
Несмотря на то что в больших подборках данных может оказаться и сфабрикованная информация, такие архивы позволяют определить размер выборки и вид презентации такой информации. Если использовать машинное обучение, то алгоритмы смогут:
- Найти точную инсайдерскую информацию среди запутанных и частично ошибочных данных.
- Предоставить различные ассоциации, образцы и связи — без каких-либо собственных предположений.
- Дать объективную информацию, на которую можно взглянуть с разных точек зрения.

Фото: пользователь Flickr Кен Хокинс
Что нам это даст?
В будущем нас ждут неожиданные результаты. Мы удивимся, насколько легко можно угадать личную информацию с помощью незначительных факторов. В 2013 году Майкл Козински опубликовал в научном журнале PNAS результаты анализа данных из социальных сетей. Только на основе лайков в Facebook ученым удалось определить такие личные данные, как религиозные и политические убеждения, и даже узнать, не развелись ли родители человека, когда ему был 21 год.
Появится множество приложений, работающих на основе источников нетрадиционных данных. Одним из таких источников являются биометрические показатели. Австралийский технологический стартап Brain Gauge уже смог выяснить, что по голосу человека можно определить, есть ли у него стресс. С помощью этих знаний компания научилась отслеживать уровень стресса в режиме реального времени. Благодаря исследованиям можно, например, снизить количество прогулов среди сотрудников.
Теперь можно проводить самые амбициозные исследования, которые объединят самые разнообразные данные и откроют нам что-то эксклюзивное об экономике, законотворчестве, здравоохранении и других областях. Например, недавно в Журнале американской медицинской ассоциации было опубликовано обширное исследование, которое совмещало в себе результаты девяти других анализов. Согласно этому исследованию, скорость ходьбы в престарелом возрасте указывает на продолжительность жизни человека.
Множество данных плюс машинное обучение откроют нам новые знания о том, как мы работаем, живем и развлекаемся. Частные лица и предприятия могут оценивать полученную информацию и сравнивать ее с уже имеющейся, чтобы принимать более выгодные решения.
Большинство представителей традиционного бизнеса — банки, авиакомпании и супермаркеты — уже знают привычки и среднестатистические предпочтения своих клиентов. Но с приходом простых и недорогих методов анализа данных организации и частные лица, наконец, смогут сами все это узнать. Собрав вместе публичные, персональные, исторические и свои собственные статистические данные, мы сможем получить уникальную информацию, которая раньше была доступна только правительству и некоторым крупным компаниям.
Материалы по теме:
«Яндекс» протестировал машинное обучение в «Пятерочке»
Большие данные должны приносить практическую пользу бизнесу – или умереть
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 12 лучших стартапов 2017 года из акселератора Y Combinator
- 2 90% стартапов умирают – причиной может быть одна из этих ошибок
- 3 Не просто лампочка – как освещение меняет жизнь офисного сотрудника
- 4 8 примеров использования компьютерного зрения
- 5 Какую выгоду для бизнеса можно извлечь из совместного применения AR и VR
ВОЗМОЖНОСТИ
25 апреля 2024
26 апреля 2024
29 апреля 2024