
Никита Никитинский, глава R&D в IRELA, и Полина Казакова, Data Scientist, в первой колонке серии о машинном обучении подробно рассказали, что такое data science. Сегодня они объяснят, как машинное обучение используется на практике.
Привет! В прошлый раз мы обсудили, что такое Data Science и выяснили, что одна из важнейших составляющих науки о данных – это машинное обучение. Мы уже знаем, что идея машинного обучения достаточно проста: найти закономерность в имеющихся данных, чтобы затем распространить ее на новые объекты. В этой статье мы чуть подробнее расскажем о том, каким бывает машинное обучение, какие типы задач оно решает и как применяется в жизни.
Типология и терминология
Два базовых типа задач, встречающихся в машинном обучении, – это задачи обучения с учителем и обучения без учителя. Прежде чем обсуждать их подробнее, давайте введем некоторые базовые термины.
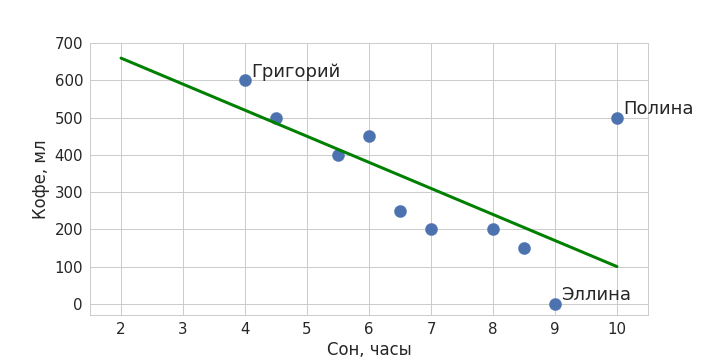
Объекты в машинном обучении описываются набором признаков. Вернемся к примеру с кофе из прошлой статьи: там объектами были люди, и мы описывали их единственным признаком – количеством сна. Признаки иначе называются независимыми переменными. Важно заметить, что признаки должны быть представлены в численном виде, потому что только так ими можно оперировать математически и обрабатывать компьютерно. Совокупность объектов, которые используются для того, чтобы построить модель, называется обучающей выборкой: десять синих точек на первом графике и были нашей обучающей выборкой.

Обучение с учителем
Методы обучения с учителем применяются тогда, когда для имеющихся объектов обучающей выборки мы знаем так называемые ответы, а для новых объектов мы хотим их предсказать. Ответы также называются зависимой переменной. В этом классе задач в свою очередь выделяется несколько типов.
В первом типе ответами являются значения некоторой численной величины, как было в нашей истории с кофе: для каждого объекта обучающей выборки мы знали количество выпитого кофе, а для нового объекта Никиты модель это значение предсказывала. Этот тип задач, когда зависимая переменная является вещественным числом (то есть может принимать любые значения на всей числовой прямой), называется задачей регрессии.
В реальной жизни к такому типу задач относится, например, предсказание температуры, прогнозирование выручки, предсказание цены квартиры по параметрам типа площади, расположения, наличия мебели.
В задачах второго типа ответы принадлежат ограниченному набору возможных категорий (или классов). Продолжим наши офисные аналогии: представьте, что офис-менеджер Михаил закупил два вида подарков для коллег к Новому году – футболки и блокноты. Чтобы не испортить сюрприз, Михаил хочет построить модель, которая предсказывала бы, какой подарок хочет получить сотрудник, на основе данных из личных профилей (внимательный читатель заметит, что в реальности для построения модели Михаилу все же пришлось бы спросить о желаемом подарке у части коллег, чтобы сформировать обучающую выборку). Такой тип задач, когда необходимо относить объекты к одной из нескольких возможных категорий, то есть когда зависимая переменная принимает конечное число значений, называется задачей классификации. Пример с подарками относится к бинарной классификации: классов всего два – «футболки» и «блокноты»; в противном случае, когда классов больше, говорят о многоклассовой классификации.
Пожалуй, самый актуальный пример классификации – задача кредитного скоринга. Принимая решение, выдать вам кредит или нет, ваш банк ориентируется на предсказание модели, натренированной по множеству признаков определять, способны ли вы вернуть запрашиваемую сумму. Такими признаками являются возраст, уровень заработной платы, различные параметры кредитной истории.
Еще один тип обучения с учителем – задача ранжирования. Она решается, когда вы ищете что-то в поисковике вроде Google: есть множество документов и необходимо отсортировать их в порядке их релевантности (смысловой близости) запросу.
Обучение без учителя
Методы обучения без учителя используются, когда никаких правильных ответов нет, есть только объекты и их признаки, а задача заключается в том, чтобы определить структуру множества этих объектов.
К таковым относится задача кластеризации: есть совокупность объектов, и необходимо разбить их на группы так, чтобы в одной группе находились объекты, похожие друг на друга. Это может быть полезно, например, когда есть большая коллекция текстов и необходимо ее как-то автоматически структурировать, разделить тексты по темам. Кластеризация может применяться для разделения пользователей сайта интернет-магазина на сегменты, к примеру, чтобы разным группам предлагать разные товары исходя из их интересов.

Другой пример обучения без учителя – задача поиска аномалий, которую мы упоминали в прошлый раз: есть множество объектов, и необходимо выделить в нем такие, которые сильно отличаются от большинства. Методы поиска аномалий используют для обнаружения нетипичных транзакций, нетипичного поведения на сайте с целью предотвращения мошенничества. Они также помогают определять поломки в различных системах на основании показателей множества датчиков.

Помимо обучения с учителем и без учителя, существуют и более изысканные типы задач. Например, в частичном обучении ответы известны только для части объектов выборки.
Алгоритмы машинного обучения
Внутри вышеописанных типов задач в машинном обучении существуют различные алгоритмы. С одним из них мы уже познакомились: это линейная регрессия – именно ее мы применяли в задаче предсказания количества кофе. Линейная регрессия является одним из самых хорошо изученных методов статистики и машинного обучения. Она подходит для описания линейных зависимостей, то есть таких, которые можно хорошо приблизить прямой линией.
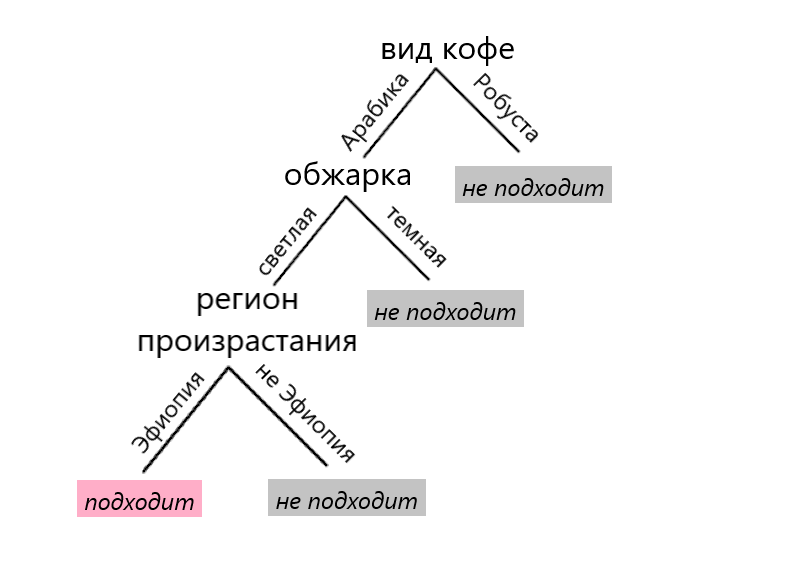
Еще один простой алгоритм машинного обучения – решающее дерево. Он напоминает набор последовательно задаваемых вопросов с (чаще всего) двумя возможными ответами. Подобный алгоритм использует офис-менеджер Михаил, когда решает, подходит ли кофе из новой поставки для приверед из отдела анализа данных. Это задача бинарной классификации, где ответы принимают значение «кофе подходит» и «кофе не подходит». Михаил последовательно отвечает на ряд вопросов, перемещаясь по веткам дерева: какой вид кофе? какая обжарка кофе? какой регион произрастания кофе? В итоге Михаил оказывается в одном из листьев (так называются «конечные» вершины) дерева, где находится предсказание.
Конечно, решающие деревья в чистом виде слишком просты и поэтому не очень подходят для решения сложных задач, однако их композиции (совокупности большого числа деревьев) оказываются неожиданно эффективными.
Глубинное обучение
Сейчас алгоритмы машинного обучения можно условно разделить на традиционные и методы глубинного обучения (это общее название для разного вида многослойных нейронных сетей). Для успешной работы традиционных алгоритмов очень важен такой этап предобработки данных, как feature engineering (для этого термина нет конвенционального перевода на русский язык; грубо его можно перевести как конструирование признаков). Это процесс формирования и отбора признаков. Как правило, работа с признаками – это трудоемкий, времязатратный процесс, который требует глубокого погружения в предметную область решаемой задачи.
Джереми Говард, один из авторов известного курса про глубинное обучение fast.ai, приводит следующий пример. Команда специалистов из Стенфорда во главе с ученым Эндрю Бэком занималась исследованием рака молочной железы. Чтобы построить модель, способную предсказывать выживет пациентка с опухолью или нет, им пришлось изучить огромное количество снимков биопсий молочной железы. Таким образом они определили, какие паттерны на снимках могут быть связаны со смертью пациентки и сформировали сотни сложных признаков, таких как связь между соседними эпителиальными клетками. Затем команда программистов разработала алгоритмы для правильного распознавания этих признаков со снимков.
На базе этих признаков была построена логистическая регрессия – достаточно простой алгоритм машинного обучения. Получившаяся модель действительно предсказывала лучше, чем живые патологи, но на ее разработку ушли годы работы целой команды экспертов из разных сфер.
Принципиальное отличие глубинного обучения в том, что оно способно взять большую часть работы по формированию признаков на себя, используя только единообразно представленные входные данные без вручную выделенных сложных признаков. В случае прогнозирования смерти от рака молочной железы медицинские снимки можно представлять просто в виде последовательности яркостей отдельных пикселей. Многослойные нейросети с каждым слоем способны объединять пиксели во все более полезные уровни абстракции. Таким образом они получают представление об изображении в целом, а также о его частях, влияющих на конечное предсказание (например, опухоль и ее размеры).
Необходимые навыки и варианты курсов
Если вам хочется глубже разобраться в теме машинного обучения и научиться решать с его помощью реальные задачи, для этого желательно иметь хотя бы базовые знания в таких областях математики как математический анализ, линейная алгебра, статистика. Пригодятся и базовые навыки программирования – в первую очередь на языке Python. Полезным будет знание английского языка, так как большинство хорошей литературы и курсов по машинному обучению – на английском.
В остальном все в ваших руках. Сейчас в интернете можно найти множество онлайн-курсов по теме, в том числе и бесплатных. Из таких для начала мы рекомендуем «Введение в машинное обучение» от НИУ ВШЭ, Machine Learning от известного ученого из Стенфорда Эндрю Ына (правда, для сдачи заданий по программированию потребуется MATLAB/Octave) и уже упомянутый нами выше fast.ai.
Материалы по теме:
Почему ваш проект по машинному обучению может потерпеть неудачу: как этого избежать
30 самых удивительных проектов по машинному обучению
Как применение метода глубокого обучения влияет на эффективность онлайн-кампаний?
Как ИИ может изменить методы оценки умственных способностей у детей
За советом к ИИ: как робот может помочь частному инвестору
Фото на обложке: Unsplash
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 Эволюция ML-сервисов в микрофинансовых организациях и советы по внедрению
- 2 Цифровые двойники: как работают, зачем нужны и как смоделировать своего
- 3 С какими сложностями может столкнуться компания при внесении данных в IT-системы и как упростить этот процесс
- 4 Помощь агробизнесу. Как Big data улучшает работу сельхозпредприятий
- 5 Как использовать Big Data & AI для увеличения потока клиентов: кейс с крупным банком
ВОЗМОЖНОСТИ
13 мая 2024
13 мая 2024
13 мая 2024
13 мая 2024
13 мая 2024