Как работает машинное обучение в маркетинге?
Объясняет эксперт
Хотя многие до сих пор считают маркетинг отраслью на грани бизнеса и искусства, рекламный рынок давно перестал быть местом, куда стремятся попасть исключительно творческие люди. Индустрия медиа и развлечений, как известно, переживает цифровую трансформацию одной из первых, а значит, и индустрия рекламы вместе с ней – и новые технологии существенно меняют ее ландшафт.
Михаил Горкунов, руководитель отдела Data Science «АДВ Лаб», рассказывает о том, что скрывается за модным научным понятием «машинное обучение» применительно к маркетингу и какие задачи можно решать с помощью алгоритмов ML в этой сфере.
Для чего может использоваться машинное обучение?
Глобально технология чаще всего используется для решения трех основных задач:
- классификация – отнесение объекта к тому или иному классу на основании его характеристик (простейший пример – мужчины/женщины);
- регрессия – определение значения того или иного параметра объекта на основе имеющихся данных (прогнозирование спроса на определенный товар, роста или падения цен);
- кластеризация – поиск независимых групп (кластеров) и их характеристик во всем множестве анализируемых данных (например, разделение писем в электронной почте по тематикам: «работа», «учеба», «личное», «спам» и так далее).
Применительно к маркетингу рассматриваются, как правило, первые две.
Итак, чем же нам могут помочь алгоритмы классификации? Прежде всего, это незаменимый инструмент для создания сегментов look-alike.
Если каких-то десять лет назад мы знали лишь социально-демографический профиль своих потребителей, то сегодня у нас есть данные о том, как они проводят досуг, куда ходят за покупками, что покупают и сколько за это платят. И именно машинное обучение помогает нам связать эти данные и использовать для повышения эффективности рекламы.

Простой пример: допустим, у нас есть небольшой сегмент потребителей, регулярно покупающих витамины. Мы знаем также, чем эти люди занимаются в интернете: на какие сайты ходят, какие действия совершают, какие тематики предпочитают.
Исходя из имеющихся у нас данных (естественно, обезличенных), мы можем предположить, что люди, ведущие себя в сети схожим образом, также могут оказаться в числе тех, кто не прочь купить витамины.
Поиск таких людей вручную занял бы огромное количество времени, однако алгоритм способен производить эти вычисления в тысячи раз быстрее. Таким образом, мы получаем возможность расширить наш сегмент – то есть создать тот самый look-alike.
Еще один возможный вариант применения подобного рода алгоритмов – отслеживание фрода. Думаю, здесь все и так понятно: на основе определенного набора признаков алгоритм решает, была ли ваша реклама в интернете показана человеку или же боту.

Что касается алгоритмов регрессии, они оказываются незаменимы при прогнозировании охватов. Используя обширные данные о прошедших рекламных кампаниях, можно обучить модель предсказывать охват будущей кампании, учитывая такие параметры, как объем бюджета, используемые каналы, сезонность и другие.
Как происходит выбор алгоритма?
Есть ли какие-то популярные алгоритмы, которые используются именно в маркетинге?
В целом, безусловно, существуют алгоритмы, пользующиеся большей популярностью у дата-сайентистов, нежели другие, – некий must-have каждого уважающего себя специалиста по работе с данными (например, логистическая регрессия или «случайный лес»).
Но нельзя сказать, что подобные предпочтения имеются применительно к конкретной отрасли – выбор алгоритма, скорее, исходит из имеющихся задач. Помимо этого, обычно учитываются размер выборки данных и время, необходимое на разработку алгоритма.
Время – это понятный параметр: в стремлении осуществить задуманное мы, как правило, выбираем наиболее быстрый путь.
С выборкой все обстоит интереснее: вы можете построить сложную нейросеть для решения поставленной задачи, но если количество исходных данных невелико, то очень скоро произойдет переобучение, и алгоритм начнет использовать в своих расчетах признаки, не имеющие отношения к реальной задаче.
Например, вы обучаете нейросеть классифицировать изображения людей на мужчин и женщин, однако ваша выборка недостаточно велика, и так получилось, что у всех женщин в ней зеленые глаза.

Алгоритм фиксирует этот момент и начинает использовать данный признак как определяющий пол человека на изображении. Таким образом, как правило, чем меньше выборка, тем проще должен быть алгоритм.
Какие в итоге результаты мы можем получить?
Насколько использование машинного обучения повышает эффективность рекламных кампаний?
В конце 2017 года мы в АДВ поставили перед собой довольно амбициозную цель: объединить данные о том, что делают потребители во всех медиа – проще говоря, создать единую систему измерений для ТВ, интернета, радио и наружной рекламы с возможностью видеть, что делает один и тот же человек в каждом из этих каналов.
На данный момент мы уже имеем возможность создавать единые рекламные кампании для ТВ и интернета – и, конечно же, во многом мы обязаны этому алгоритмам машинного обучения.
Процесс происходит следующим образом: основным поставщиком данных об аудитории на российском рекламном рынке является компания Mediascope. Для того чтобы эффективно планировать размещение сразу в двух ключевых медиа (ТВ+интернет) и определять необходимую долю каждого из них в рекламной кампании, нужно объединить информацию из двух источников – Mediascope TV Index (данные о просмотре ТВ) и Web Index (данные об интернет-пользовании).
Для начала мы используем небольшую выборку, в которой нам уже известны характерные черты поведения одних и тех же пользователей как на ТВ, так и в интернете, и на ее основе обучаем алгоритм находить похожих пользователей в нужных нам источниках.

Мы находим в TV Index человека с максимально близкими признаками к пользователю Х, а затем проделываем то же самое и в Web Index – для этого используется довольно популярный и простой алгоритм kNN или k-ближайших соседей (как раз тот случай, когда количество исходных данных невелико).
Далее нам остается лишь «соединить» найденных пользователей в двух источниках между собой. Здесь в дело вступает Венгерский алгоритм – он не имеет отношения к машинному обучению, но помогает нам сформировать пары в новой выборке – проще говоря, найти одного и того же человека. Звучит довольно фантастично, однако точность подобного метода составляет порядка 95%.
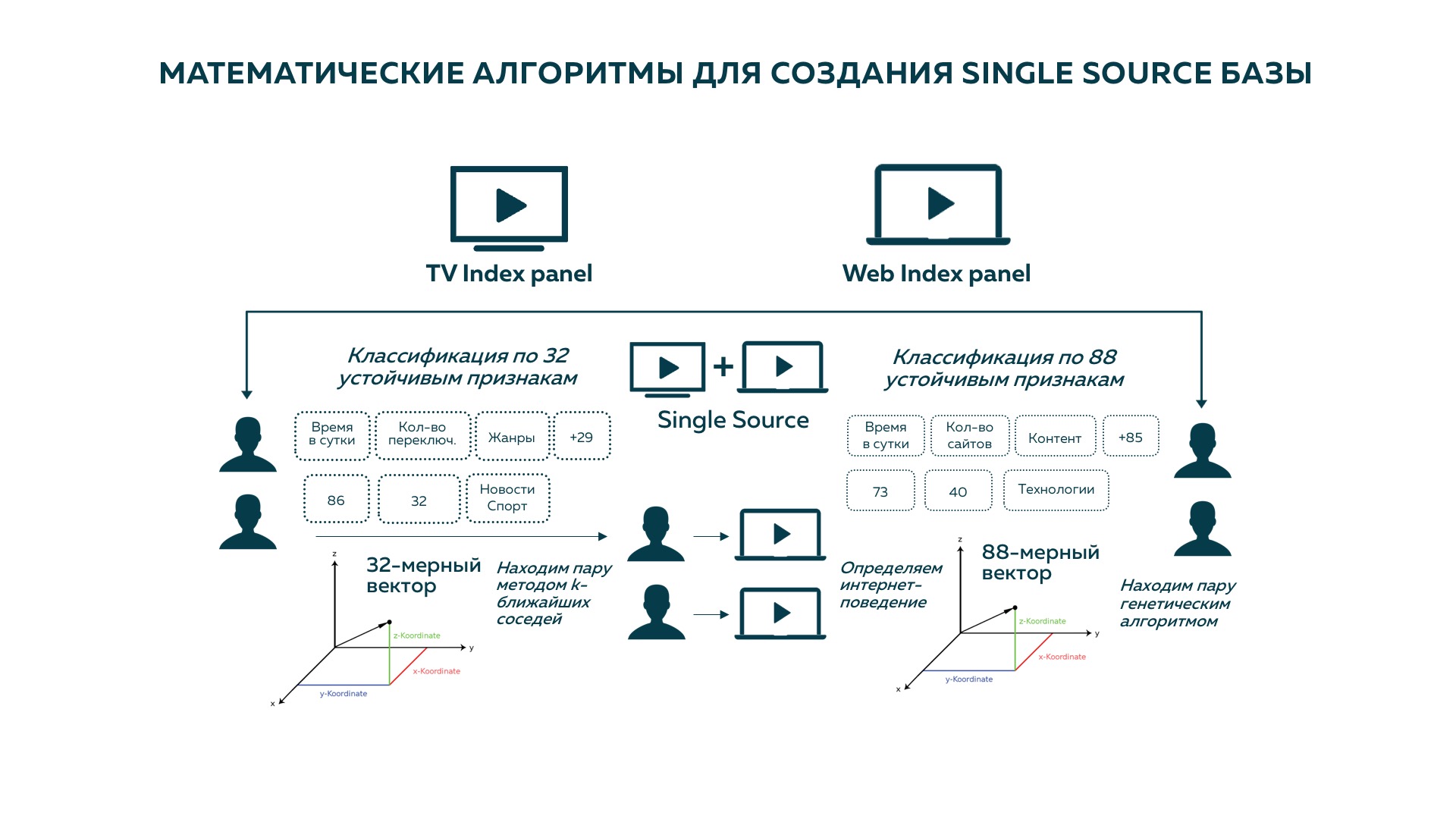
По нашим замерам, такой подход способен увеличить эффективность до 17%. Учитывая, что машинное обучение является одной из самых быстроразвивающихся областей искусственного интеллекта, нетрудно представить, какое будущее нас ждет.
Материалы по теме:
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Искусственный интеллект Компании научились собирать данные. Принимать решения — нет: почему цифры не помогают сами по себе 21 июля 2026, 16:04

-
Бизнес От спора о будущем ИИ до большого бизнеса: история Claude 25 июля 2026, 17:00

-
Автомобили От ткацкого станка до Prius: история Toyota 22 июля 2026, 15:24

-
Личное Реклама будущего — предвосхищающая: не ждет запроса, а работает на опережение 22 июля 2026, 19:00

-
Бизнес Соавтор «Смешариков» Илья Попов: «Создать анимационный проект сегодня — это лишь 5% успеха» 20 июля 2026, 10:00

-
Искусственный интеллект Нам не нужен свой OpenAI: где России искать эффект от ИИ и что для этого делать 19 мая 2026, 11:00

-
Тренды 5 форматов коллабораций брендов с инфлюенсерами на ЧМ-2026: как бизнес борется за внимание зрителей 16 июля 2026, 11:21









-
Кибербезопасность macOS не надежнее Windows: пользователи системы от Apple чаще сталкиваются с киберугрозами, чем аудитория Microsoft 25 июля 2026, 16:00

-
Бизнес Assassin’s Creed Black Flag Resynced выполнила годовой план за две недели — продано 3,5 млн копий 24 июля 2026, 16:00

-
Деньги Продажи квартир в новостройках выросли на 33%: средняя стоимость квадратного метра в 2026-м — 207 тыс. ₽ 25 июля 2026, 19:00

-
Автомобили Каждый третий россиянин готов пригнать автомобиль из-за границы — 44% хотят привезти машину из Китая 25 июля 2026, 13:00

-
Россия Уровень безработицы в России опустился до 2,1% — это самый низкий показатель с 1991 года 25 июля 2026, 10:00

-
Бизнес Спрос на новый Galaxy Z Fold оказался выше обычного на 15–40% — но итоговые продажи могут быть ниже, чем в 2025-м 24 июля 2026, 20:00

-
Маркетплейсы Бизнес просит создать единый механизм поддержки селлеров на маркетплейсах — продавцы ждут отмены штрафов 24 июля 2026, 19:00

-
IT Яндекс Карты упростили путешествия по Турции: сервис разрешил делиться геопозицией и добавил навигацию в аэропортах 24 июля 2026, 18:00








