
5 ошибок при работе с большими данными

Константин Круглов, основатель и генеральный директор DCA, рассказывает, какие типичные ошибки совершают новички, используя большие данные, и можно ли этого избежать.
В последние несколько лет невероятную популярность обрела тема больших данных. Компании по всему миру выделяют бюджеты и нанимают специалистов по сбору и анализу огромных массивов информации. Интернет полон рассказов о том, как анализ данных помог той или иной компании значительно увеличить прибыль и решить другие проблемы.
Данных много, а пользы нет? Только проверенные компании, которые специализируются на Big DataКак это часто бывает, применить на себя чужой опыт не так-то просто, и руководители под влиянием всеобщей шумихи и историй успеха решаются на запуск новых технологических проектов, не понимая, как правильно работать с большими данными. Это приводит к негативным результатом и возникновению уверенности в том, что «этот инструмент нам не подходит».
Сегодня мы поговорим о том, какие типичные ошибки совершают компании при работе с Big Data и как их избежать.
1. Запуск Big Data-проектов с использованием устаревшей инфраструктуры
Эксперты компании Oracle называют среди главных ошибок бизнеса при работе с большими данными нежелание руководителей заниматься внедрением новых моделей работы с информацией и использованием устаревших технологий.
Такой подход ограничивает возможности по сбору и обработке данных, а также мешает расширению проектов с Big Data в будущем. Устаревшие технологии не позволяет бизнесу получить полную отдачу от работы в этом направлении. Современные технологии вроде Pig Latin, HiveQL, MapReduce позволяют организовать сбор больших массивов данных в режиме реального времени, сохраняя возможность работы с ними «на лету», снижая вероятность их потерь. При работе с устаревшей ИТ-инфраструктурой рассчитывать на подобную производительность не приходится.
2. Отсутствие четких критерии успешности проекта
Аналитическая компания Capgemini провела исследование, в котором приняли участие представители 226 компаний со всего мира. Одной из главных проблем бизнеса при работе с Big Data 67% респондентов назвали отсутствие четко определенных критериев успешности и неуспешности запускаемых проектов в сфере больших данных.
Обратной стороной популярности концепции больших данных является тот факт, что многие руководители бизнеса, очаровываясь трендом, запускают проекты, которые затем не могут оценить.
Мало просто собрать «очень много данных», нужно еще знать, как их использовать для решения проблем бизнеса – а значит, прежде всего нужно эти проблемы выявить.
На каждом этапе проекта необходимо анализировать результаты, которых удалось добиться – и здесь нужны не расплывчатые формулировки, а четкие и измеряемые критерии оценки вроде «роста продаж на n % за период t».
3. Использование нерелевантных данных
Данные окружают нас повсюду, они имеют разные формы и размеры. Но не вся информация одинакова полезна бизнесу. Как пишет призидент Sixth Sense Advisors Криш Кришнан в статье на IBM Big Data & Analytics Hub, важно понимать, как каждый из доступных видов данных соотносится с бизнесом. Вот какие формы может принимать информация:
- Неструктурированные данные – например, тексты, видео, аудио или изображения.
- Полуструктурированные данные – включают сообщения электронной почты, опубликованные отчеты с финансовыми результатами, всевозможные таблицы и модули программного обеспечения.
- Структурированные данные – в эту категорию попадают данные, собранные различными сенсорами, машинная информация, финансовые модели, модели риска и т.п.
Бизнесу важно понимать, от работы с информацей какого типа можно получить больше пользы. К примеру, при взгляде на классификацию выше может показаться, что аудио – не лучший тип данных. Однако если записать разговоры сотрудников колл-центра с клиентами, которые звонят для решения своих проблем, а затем перевести их в текст, то можно получить неоценимое количество информации об отношении клиентов в компании, качестве оказываемых ею услуг или продаваемых продуктов.
Не нужно собирать все доступные данные, необходимо выделять те, которые наиболее полезны.
4. Применение больших данных не по назначению
Эту проблему описывает в своей статье для издания Wired Нассим Талеб, экономист, биржевой трейдер и автор бестселлеров «Черный лебедь. Под знаком непредсказуемости» и «Одураченные случайностью». Его идея заключается в том, что сейчас многие компании, находясь под влиянием «модного» термина, начинают собирать огромные массивы данных и искать в них корреляции, не понимая, что такие объёмы информации могут наоборот быть источником возникновения ложных связей.
Талеб приводит пример:
Если взять набор из случайно выбранных 200 переменных, которые никак не связаны между собой, и присвоить им 1000 информационных параметров, то будет практически невозможно не найти при дальнейшем анализе какое-то количество статистически обоснованных корреляций. Но на самом деле эти корреляции будут ложными, поскольку никакой связи между переменными никогда не было.
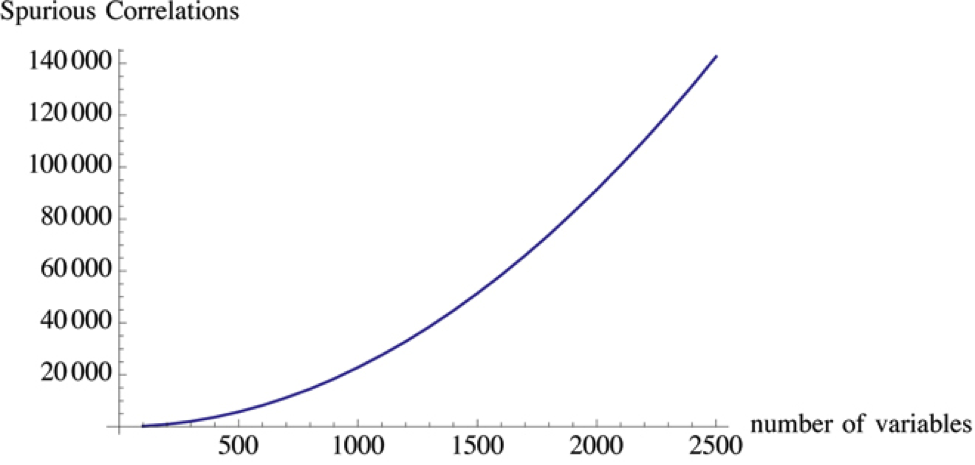
Это говорит о том, что в некоторых случаях для достижения требуемых результатов не нужно собирать огромные массивы информации, поскольку их анализ будет похож на поиск иголки в стоге сена.
5. Слепая вера в успех
Очень часто руководители компаний считают, что главное – начать работать с большими данными и внедрить необходимые для этого технологии, а дальше все получится само собой. Но на самом деле технологии и сами данные не являются «серебряной пулей», которая решит все проблемы бизнеса. Мало внедрить самые современные технологии и нанять лучших экспертов по работе с ними – само это не позволит добиться решения бизнес-задач.
Если руководители не будут участвовать в процессе работы с данными, донося до членов команды реальные проблемы компании, которые нужно решить, то велик риск получить ситуацию, при которой увлеченные своим делом эксперты работают ради самого процесса, напрочь забыв о его цели. В таких условиях надеяться на осязаемый эффект в обозримом будущем не приходится.
Что делать
- Прежде, чем начинать проекты по работе с большими данными, компании необходимо определиться с целями, которые планируется достичь, а также подумать о том, какую именно информацию нужно собирать и столь уж большой ее объём нужен для того, чтобы добиться нужного результата.
- На следующем этапе следует подумать о технологической составляющей проекта — стоит ли заниматься разработкой своего программного решения для работы с данными или воспользоваться уже существующими инструментами. Некоторые из них, как, к примеру, наши продукты, можно персонализировать и запустить под собственным брендом и на своем оборудовании.
- Определения релевантных источников информации и выбор подходящих для работы с ней инструментов — это ключевые задачи, которые необходимо решить для того, чтобы ваш Big Data-проект оказался успешным.
Материалы по теме:
Билайн запустил курс по Big Data для людей без математического образования
Microsoft запустил 5 бесплатных курсов для технарей
16 конференций по big data, которые пройдут в 2016 году
Подтяни бигдату. Курсы и полезные ссылки по теме data science
Мировому рынку Big Data предсказали рост до $1 трлн
Как большие данные вторгаются в частную жизнь
Можно ли не зависеть от больших данных?
Видео по теме:
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Популярное
Налог на прибыль организаций
Материалы по теме
-
Пройти курс «Самое важное o 115-ФЗ»

- 1 Большие данные и ИИ стали драйвером роста российской экономики По прогнозам, к 2030 году вклад ИИ и big data в ВВП страны достигнет 10,6 трлн рублей 18 апреля 14:00
- 2 Как вывести работу с данными на новый уровень: кейс по комплексному анализу данных с помощью RnD Рассказываем об уникальной методологии анализа данных 20 марта 19:52
- 3 Машинное обучение и большие данные: как они связаны? Прежде чем данные смогут «обучить» алгоритмы машинного обучения, они проходят этапы 19 марта 06:30
- 4 Топ-7 идей Data Science проектов — пет-проекты и примеры анализа данных Полезные проекты на каждый день 03 марта 18:55