Уже не black box. Новые возможности в машинном обучении (и как бизнесу их использовать)
Как и зачем интерпретировать ML-модели
Машинное обучение (ML) все чаще применяется в самых разных сферах жизни для решения задач прогнозирования, классификации и разработки рекомендательных систем. Такие популярные ныне ML-алгоритмы как нейронные сети или градиентный бустинг способны распознать даже самые глубокие взаимосвязи в наборах данных, что часто позволяет добиться очень высокой точности предсказания.
Несмотря на это очевидное преимущество, многие компании все еще неохотно внедряют подобные модели в свои бизнес-процессы. В чем же дело? Отвечает Евгений Никитин, технический директор Fscorelab.
Препятствия для распространения машинного обучения
Одним из основных препятствий для широкого распространения машинного обучения в бизнесе является компромисс между интерпретируемостью и сложностью алгоритма. Чем сложнее внутренняя структура модели, тем более глубокие взаимосвязи между переменными она может находить, но и тем труднее она становится для понимания людьми, особенно не связанными напрямую с миром машинного обучения и статистики.
Самый банальный пример простой модели — линейная регрессия. Каждый коэффициент линейной регрессии показывает, как в среднем изменится предсказанное значение, если значение переменной вырастет на одну единицу.
К примеру, рисунок 1 демонстрирует простейшую модель для предсказания количества дней просрочки выплаты кредитного займа с одной переменной — возрастом клиента. Согласно этой модели, увеличение возраста клиента на один год в среднем снижает прогноз по просрочке на 0,36 дней.
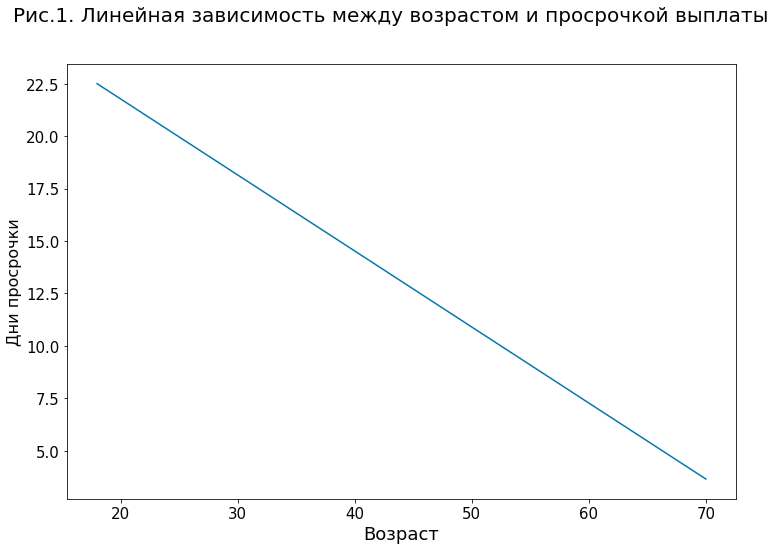
Однако, даже с линейными моделями не все так просто. Например, если в модели есть несколько сильно коррелированных переменных (например, возраст и количество закрытых кредитов в кредитной истории), прямая интерпретация коэффициентов при этих переменных может стать не такой уж банальной задачей. Еще сложнее дело обстоит с нелинейными моделями, где зависимости между переменными и предсказанием могут иметь сложную, немонотонную форму со множеством взаимозависимостей.
Такие модели в машинном обучении часто называют «черными ящиками» (black box). На вход модели подается набор переменных, на основе которых она рассчитывает свое предсказание, но то, как именно было принято это решение, какие факторы на него повлияли — ответы на эти вопросы зачастую остаются спрятаны в «черном ящике» алгоритма.
Что такое интерпретируемость?
Прежде чем перейти к описанию существующих методов интерпретации, нелишним будет обсудить, что же именно понимается под интерпретируемостью модели и зачем вообще нужно интерпретировать и объяснять предсказания ML-моделей.
Термин «интерпретируемость модели» является зонтичным, то есть он включает в себя целый набор признаков и определений.
В наиболее общем виде, интерпретируемость можно определить как степень того, насколько человек может понять причину, по которой было принято определенное решение (например, решение выдать кредит клиенту).
Это определение является хорошей стартовой точкой, но оно не дает ответа на многие важные вопросы. Например, кто именно имеется в виду под «человеком» — эксперт в данной предметной области или обычный человек «с улицы»? Какие факторы должны учитываться при оценке интерпретируемости — затраченные временные и умственные ресурсы, глубина понимания внутренних процессов моделей, доверие человека к ним?
Несмотря на отсутствие на текущий момент единого подхода к этому понятию, мы интуитивно чувствуем, что делает ML-модель более или менее интерпретируемой. Это любая информация в форме доступной для восприятия, которая улучшает наше понимание того, какие факторы и как именно повлияли на данное конкретное предсказание и на работу модели в целом. Эта информация может принимать разную форму, например, визуализации и графики или текстовые объяснения.
Зачем интерпретировать ML-модели?
Почему вообще возникла необходимость интерпретировать предсказания ML-моделей, и какая от этого польза? Ответ на этот вопрос зависит от контекста и может включать:
- Юридические причины. 25 мая 2018 года в Европейском союзе начал действовать новый регламент о защите данных — General Data Protection Regulation (GDPR). В числе прочего, статья 13 этого регламента гласит, что каждый субъект данных имеет так называемое «право на объяснение» (right to explanation), то есть на получение информации о том, почему автоматизированная система приняла то или иное решение, например, отказ в выдаче займа. В отдельных отраслях могут действовать и свои правила, регламентирующие работу автоматизированных систем принятия решений.
- Этические причины. Понимание того, как работает модель, может помочь избежать этически неприемлемых ситуаций — например, дискриминации против определенной группы клиентов. Если модель использует пол или национальность клиента как важный фактор при принятии решения, мы можем попытаться изменить модель таким образом, чтобы избежать нежелательной дискриминации.
- Доверие. Конечные пользователи моделей будут более склонны им доверять, если они смогут получить информацию о влиянии различных факторов на предсказания. В нашей практике введение методов интерпретации в системы кредитного скоринга практически всегда ведет к росту доверия к модели со стороны клиентов и, как результат, к повышению их лояльности к нашей компании.
- Тестирование и улучшение модели. Понимание того, какие переменные и каким образом влияют на работу модели, может помочь идентифицировать потенциальные проблемы в ней и дать информацию о том, какие еще переменные можно туда добавить, чтобы улучшить качество предсказания, а какие стоит из нее исключить, чтобы оптимизировать использование ресурсов.
Стоит отметить, что не стоит слепо гнаться за максимальной интерпретируемостью модели. К примеру, если стоимость ошибки в предсказании невелика (к примеру, рекомендация фильма пользователю), то и прилагать огромные усилия для того, чтобы сделать модель более интерпретируемой, возможно, не стоит. В этом случае можно ограничиться стандартной процедурой валидации качества модели.
Как интерпретировать модели?
Способы интерпретации ML-моделей в целом делятся на локальные и глобальные.
- Глобальные методы призваны показать, какие факторы в целом оказывают наибольшее влияние на структуру модели и на ее предсказания.
- Локальные способы пытаются объяснить то, как было сделано данное конкретное предсказание (например, отказ в выдаче кредита клиенту). Зачастую локальные методы могут быть использованы как основа для более глобальной интерпретации, например, путем усреднения или визуализации.
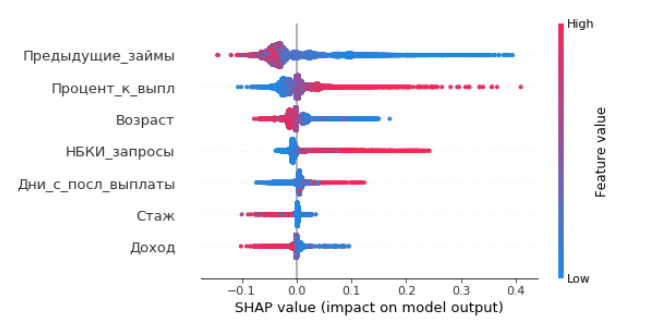
Одним из самых известных и традиционных показателей интерпретируемости моделей типа «черный ящик» является важность переменных (feature importance). Важность — это некий численный показатель, который показывает то, какое влияние в среднем оказывает данная переменная на предсказания модели, по сравнению с другими переменными. Конкретный способ расчета важности зависит от алгоритма. Например, в случае с деревьями решений мы можем посчитать сколько раз та или иная переменная была использована в дереве для разделения на «ветки» (split). Рисунок 2 демонстрирует пример диаграммы важности переменных. Как мы видим, количество предыдущих займов в этой модели играют наибольшую роль.

Этот метод имеет как минимум два очевидных недостатка.
- Во-первых, он не предоставляет никакой информации о том, как именно та или иная переменная влияет на процесс принятия решений. Например, глядя на этот график, мы не можем сказать, увеличивает или уменьшает вероятность дефолта увеличение количества предыдущих займов.
- Во-вторых, он не решает проблемы коррелированных переменных — если две переменные взаимосвязаны, но переменная 1 работает в модели немного лучше другой, то важность переменной 2, скорее всего, будет крайне низкой, что может не отражать реального положения вещей.
Для решения этих и других проблем за последние пару лет было предложено около десятка различных методов, например, LIME или treeinterpreter. Многие из этих методов основаны на идее замены сложной, плохо интерпретируемой модели на одну или несколько простых моделей, похожих по своим свойствам. Одним из самых многообещающих методов, который является одной из стандартных практик в нашей компании, является метод расчета SHAP values.
Основную идею этого метода можно продемонстрировать на примере, который весьма соответствует моменту. Представьте, что вам нужно набрать футбольную команду из 11 человек из большого списка кандидатов. Без команды ваша вероятность победить равняется 0%.
- Вы случайным образом выбираете первого игрока по имени Артем Д. Это хороший футболист, известный бомбардир, но в одиночку он не способен успешно противостоять сопернику, и вероятность победы вырастает всего лишь до 2%.
- Затем, вы добавляете в команду Александра К. В одиночку он бы мог увеличить вероятность победы команды на 3%, но он очень хорошо взаимодействует в связке с уже выбранным Артемом Д., поэтому общая вероятность победы растет с 2% до 8%.
- Следующий игрок в вашем списке — вратарь Игорь А. Вратарь — один из самых важных элементов команды, и вероятность победы резко увеличивается — с 8% до 18%.
- Следующим игроком вновь оказывается вратарь, Юрий Л. Если бы он был добавлен в команду до Игоря А., то он бы мог увеличить вероятность добиться победы на те же 10%. Однако, иметь двух вратарей на поле не имеет никакого смысла — и вероятность выигрыша остается на уровне 18%.
Аналогия с машинным обучением здесь легко угадывается, команда — это модель, а игроки — переменные. Как можно заметить, влияние каждой переменной на результат (вероятность победы) зависит в том числе от присутствия и отсутствия других переменных в модели.
Основная идея метода SHAP как раз и состоит в расчете вклада каждой переменной для всех возможных комбинаций других переменных в модели. Финальный вклад каждой переменной рассчитывается как средневзвешенное всех возможных вкладов.
Например, если это значение для Артема А. равно 7%, это значит, что среди всех возможных комбинаций составов команды, он в среднем увеличивает вероятность победы на 7%.
Еще одно преимущество этого метода заключается в том, что его авторы предложили очень эффективную реализацию алгоритма для ансамблей деревьев, которые демонстрируют отличное качество предсказаний во многих практических задачах.
На следующем рисунке показан пример объяснения предсказания дефолта для конкретного клиента с помощью одной из моделей градиентного бустинга. Средняя вероятность дефолта по всему набору данных (base value) равна 0,06 или 6%. Предсказанная вероятность дефолта для этого клиента — 0,19 (19%, выделено жирным шрифтом).
Какие же факторы привели к относительно высокой предсказанной вероятности дефолта для этого клиента? Переменные, выделенные красным (например, доход и количество предыдущих займов), увеличивают эту вероятность. Переменные, выделенные синим (возраст и количество недавних запросов к НБКИ), ее уменьшают. С помощью этой диаграммы кредитный специалист может оценить, насколько он доверяет прогнозу модели в данном конкретном случае.

Индивидуальные объяснения также могут быть агрегированы на уровне всего набора данных. На следующей диаграмме каждая точка — это один клиент, синим цветом обозначены клиенты с низким значением соответствующей переменной, а красным — с высоким. Горизонтальная ось показывает влияние каждой переменной на предсказанную вероятность дефолта для каждого клиента.
Глядя на эту диаграмму, мы можем быстро оценить, насколько логика модели соответствует нашим ожиданиям или здравому смыслу. В данном случае маленькое количество предыдущих займов увеличивает предсказанную вероятность дефолта для большинства клиентов. Аналогично, высокий стаж и доход ведут к уменьшению предсказанной вероятности дефолта.
Заключение
Итак, как мы видим, интерпретация даже самых сложных ML-моделей — отнюдь не невозможное дело. Недавно разработанные методы позволяют лучше понимать внутреннюю логику, которая стоит за автоматизированным принятием важных решений, таких как выдача займов клиенту или определение диагноза пациента, при этом не жертвуя качеством модели.
Конечно же, большое количество способов интерпретации и визуализации осталось за рамками данной статьи. Например, широко используемые Partial Dependence Plots (PDP) и Individual Conditional Expectation (ICE) plots, а также вышеупомянутый LIME (Local Interpretable Model-agnostic Explanations). Предлагаем читателю самостоятельно с ними ознакомиться. Ниже вы найдете список полезных статей, которые можно почитать на эту тему.
Что еще можно почитать на тему
- Miller, T. (2017). Explanation in Artificial Intelligence: Insights from the Social Sciences.
- Lundberg, S., & Lee, S.I. (2017). A Unified Approach to Interpreting Model Predictions.
- Lipton, Z. C. (2016). The Mythos of Model Interpretability.
- Ribeiro, M. T., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier.
- Goodman, B., & Flaxman, S. (2016). European Union regulations on algorithmic decision-making and a “right to explanation.
Полезные ссылки
- Библиотека LIME - https://github.com/marcotcr/lime
- Библиотека SHAP - https://github.com/slundberg/shap
- Ideas on interpreting machine learning - https://www.oreilly.com/ideas/ideas-on-interpreting-machine-learning
Материалы по теме:
5 примеров того, как искусственный интеллект облегчит вам работу
Как фотографии кошек и собак обучают ИИ Facebook
Как ускорить работу маркетологов и повысить продажи? Поможет машинное обучение!
5 примеров использования машинного обучения в бизнесе
В России катастрофически не хватает инженеров данных – кому и зачем они нужны
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Искусственный интеллект Компании научились собирать данные. Принимать решения — нет: почему цифры не помогают сами по себе 21 июля 2026, 16:04

-
Личное Реклама будущего — предвосхищающая: не ждет запроса, а работает на опережение 22 июля 2026, 19:00

-
Автомобили От аккумуляторов для телефонов до победы над Tesla: история BYD 31 июля 2026, 23:02

-
Автомобили Как из чужих технологий сделать собственный бизнес: история Changan 31 июля 2026, 16:40

-
Личное Льюис Хэмилтон. Как гонщик превратил себя в главный бренд «Формулы‑1» 31 июля 2026, 13:38

-
Бизнес Как вафельница и Майкл Джордан помогли построить спортивную империю: история Nike 29 июля 2026, 20:14
-
Автомобили От «народного автомобиля» до гаража с Bentley и Lamborghini: история Volkswagen 28 июля 2026, 21:46








-
Бизнес Татьяна Ким анонсировала новые меры поддержки продавцов Wildberries — их представят уже в ближайшие дни 31 июля 2026, 20:30

-
Бизнес «Аэрофлот» отчитался за I полугодие 2026 года: компания получила убыток 0,6 млрд ₽ — против прибыли годом ранее 31 июля 2026, 20:00

-
Россия В России могут усилить контроль за производителями радиоэлектроники — Минпромторг изменит правила выдачи льгот 31 июля 2026, 22:00

-
Кибербезопасность ЦБ предложил подключить маркетплейсы к борьбе с мошенниками: платформы хотят включить в систему антифрод-контроля 31 июля 2026, 21:00

-
Банки Россияне стали чаще жаловаться на МФО — число обращений выросло на 63% из-за недобросовестных посредников 31 июля 2026, 19:00

-
Россия В России разработали единые правила эксплуатации и ПДД для роботов-доставщиков — скорость роверов ограничат 31 июля 2026, 18:30

-
Технологии В России стартовали продажи флагманских смартфонов серии Huawei Pura 90s — по цене от 75 тыс. ₽ 31 июля 2026, 17:20

-
Автомобили Lada стала лидером российского авторынка за последние 20 лет — компания продала 7,4 млн автомобилей 31 июля 2026, 17:00








