Данные — новая нефть. Как на них заработать?
Пять способов
Алексей Шабанов, исследователь Neuromation, рассказывает, какие данные представляют ценность для компаний, и раскрывает пять способов заработка на них.
Сегодня многие технологические компании активно используют методы машинного обучения, чтобы встраивать в свои продукты и бизнес-процессы умные алгоритмы. Так, с каждым днем рекламная выдача становится прицельнее, автоматический перевод точнее, а голосовые ассистенты понятливее. Необходимый ингредиент для создания таких систем — данные, много данных.
Следовательно, первый ответ на вопрос из заголовка будет таким: нужно найти релевантные к деятельности компании данные и использовать их, чтобы сделать выпускаемые продукты «умнее». Но подобный ответ лежит на поверхности и едва ли может считаться полным. Мы поможем открыть читателю менее очевидные способы заработка на данных, но для этого придется совершить небольшой экскурс в предметную область.
Какие данные представляют ценность?
Задачи машинного обучения подразумевают, что необходимо научить некоторый алгоритм извлекать закономерности из обучающего набора «вопросов» и «ответов», чтобы обобщить полученный опыт для ответов на новые вопросы. В качестве алгоритма могут использоваться классические статистические модели, а могут и искусственные нейронные сети — для нашего повествования это не играет роли. Например, мы желаем научить какую-то модель определять тональности рецензий на фильмы, тогда вопрос — это текст рецензии, а ответ — один из двух вариантов: положительной была рецензия или отрицательной. Еще несколько примеров:
- Вопрос — рентген-снимок пациента; ответ — локализация аномалий и диагноз.
- Вопрос — аудиозапись человеческой речи; ответ — текстовая расшифровка.
- Вопрос — видеозапись с камеры, установленной на перекрестке; ответ — обведенные контуры автомобилей на каждом кадре.
Процесс получения ответов на заданные вопросы (в приведенном узком смысле) называется разметкой или аннотированием данных, а совокупность полученных данных называется датасетом. Итак, с точки зрения машинного обучения ценность представляют не любые данные, а размеченные. Стоимость аннотирования зависит от многих факторов: требуемой компетенции разметчиков, сложности технической организации процесса, конфиденциальности данных и других.
Так, отсортировать рецензии к фильмам может любой человек, используя примитивный текстовый редактор. Чтобы выделить контуры автомобилей на изображении перекрестка, особых знаний тоже не нужно, но потребуется специализированное ПО.
Наконец, чтобы разметить серию рентген-снимков, потребуется и ПО, и специалисты с медицинским образованием — такие данные представляют особую ценность.
Растущий спрос на все большие объемы аннотированных данных привел к созданию таких площадок как Amazon Mechanical Turk и его отечественного аналога Яндекс.Толоки. Эти сервисы позволяют свести заказчиков датасетов и специалистов по разметке данных. Часто последними являются малообеспеченные граждане азиатских стран, таких как Индия, Пакистан и Бангладеш. В большинстве случаев они за целый день работы получают всего несколько долларов, в то время как владельцы площадок получают большую часть стоимости заказа. Обладатели уже размеченных данных тоже могут извлечь выгоду: либо косвенно, выкладывая их в открытый доступ для продвижения своего бренда, либо напрямую, перепродавая датасеты другим заинтересованным лицам.
Кроме стоимости, у ручного аннотирования есть еще один существенный недостаток: для некоторых задач невозможно предложить приемлемый способ ручной разметки. Скажем, в случае с перекрестком мы можем захотеть дополнительно определять скорости автомобилей на каждом кадре: точно проставить такие метки вручную крайне проблематично. Избежать названных проблем помогает использование синтетических данных.
Что такое синтетические данные?
Под словосочетанием «синтетические данные» обычно подразумеваются объекты реального мира, смоделированные с помощью компьютера. Главное преимущество такого подхода в том, что разметка к ним прилагается автоматически. Вновь обратимся к примеру с перекрестком: если смоделировать его средствами для создания компьютерных игр, мы сразу получим полную информацию о любом объекте в кадре: его скорость, цвет, массу, положение и что угодно еще! Другой пример: использование синтезатора для озвучивания текста позволяет с точностью до миллисекунд сопоставлять буквы и их фонемы, что недостижимо при использовании ручного труда.
Кроме того, синтетические датасеты отлично масштабируются: например, получив в распоряжение синтезатор речи, можно озвучить миллионы страниц текста!
Вдумчивый читатель мог догадаться, что самое сложное при работе с синтетическими данными — сделать их достаточно реалистичными. Действительно, взаимосвязи между объектами в синтетическом датасете должны иметь место в реальном мире. К счастью, сейчас активно развиваются архитектуры нейронных сетей, предназначенные для генерации контента (Generative Adversarial Networks, GAN), которые позволяют адаптировать синтетические данные под задачи реального мира. Кроме того, GAN’ы могут использоваться и для генерации контента «с нуля», получаемые таким способом сущности тоже можно назвать синтетическими. Однако, практика показывает, что качество такой генерации уступает адаптированной синтетике.
Кто работает с синтетическими данными?
Приведем пример компаний, использующих синтетические данные для создания своих продуктов:
- В 2016 году компания Avito собрала огромный датасет объявлений и организовала соревнование для специалистов по машинному обучению. Призовой фонд составил 20 тысяч долларов, а для хостинга была выбрана площадка Kaggle. Участникам предлагалось найти объявления, которые вручную были отмечены как дубликаты, при этом соответствующие им тексты и изображения могли значительно отличаться. Таким образом, были успешно апробированы алгоритмы, способные на большее, чем механическое сравнение данных.
- В 2016 году научная группа из Apple опубликовала статью «Learning from Simulated and Unsupervised Images through Adversarial Training», рассказывающую об определении направления взгляда с использованием изображений адаптированных синтетических глаз. Интересно, что авторы предложили тестовой группе попытаться отличить фотографии настоящих глаз от синтетических: оказалось, что люди не смогли показать результат, превосходящий случайное угадывание.
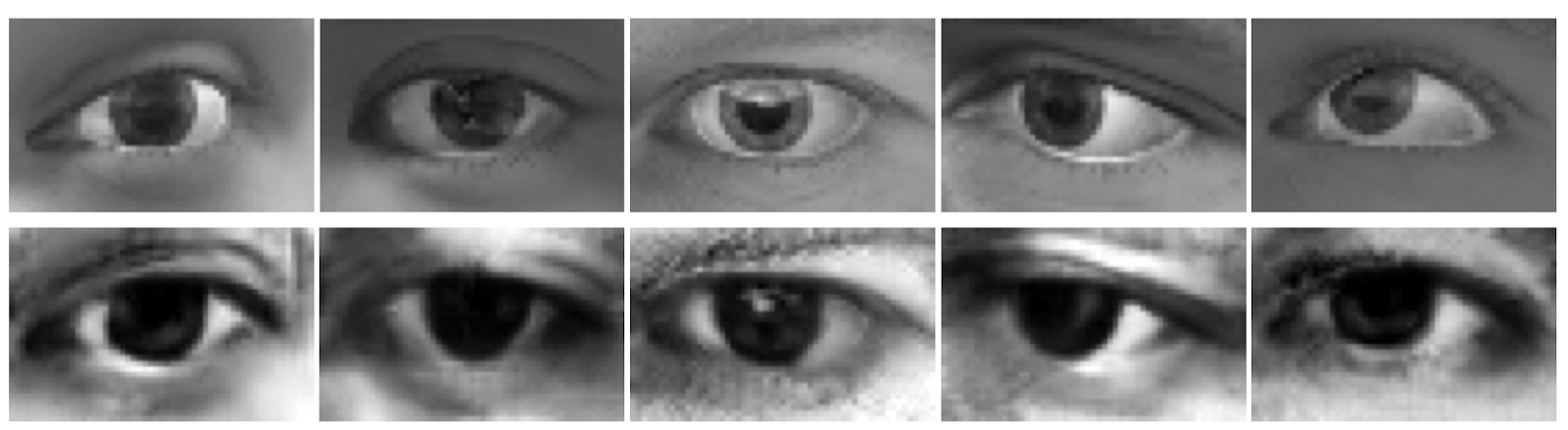
Синтетические глаза сверху, снизу их более реалистичные версии, полученные с помощью GAN’ов.
- Исследователи из Berkeley и Glidwell Dental Labs в 2018 году представили работу «Learning Beyond Human Expertise with Generative Models for Dental Restorations», посвященную использованию генерируемых данных для решения задачи стоматологической реставрации. Авторы рассказывают, как с помощью GAN’ов можно автоматизировать дорогостоящий процесс создания вручную формы зубных коронок.
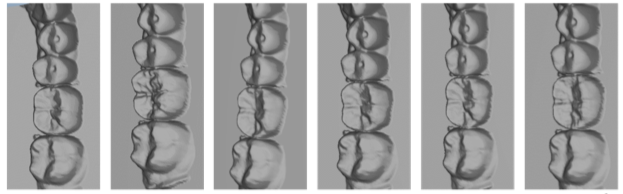
Сгенерированные формы для зубных коронок.
- Успех киностудии и по совместительству онлайн-кинотеатра Netflix во многом связан с работой рекомендательной системы Cinematch. Она позволяет индивидуально подбирать для каждого зрителя потенциально интересные фильмы, основываясь на поведении пользователей со схожими вкусами. Разумеется, создание такой системы невозможно без сбора гигантского количества записей о том, какой рейтинг пользователи поставили тем или иным фильмам.
- Мы также активно используем синтетические данные в большей части своих проектов, один из которых — создание системы для классификации товаров на продуктовых полках. Одна из возникающих проблем состоит в том, что каталог товаров огромен, при этом некоторые наименования и внешний вид товаров отличаются незначительно. Другая проблема — размечающим пришлось бы узнавать развернутые и находящиеся в дальних рядах товары. Наконец, вручную определить дополнительные параметры, такие как угол поворота упаковки или расстояние от камеры до полки почти невозможно. Выйти из затруднительного положения удалось с помощью рендеринга миллионов искусственных полок, содержащих 3D-модели оцифрованных товаров из настоящих магазинов.

Синтетическая полка с товарами.
Итак, как же заработать на данных?
Напоследок, вооружившись знаниями о предметной области, вновь ответим на вопрос, поставленный в заголовке. Условно способы заработка можно разбить на пять групп:
- Упомянутое в самом начале статьи извлечение дополнительной выгоды из продуктов, улучшенных методами машинного обучения.
- Деятельность, связанная с процессом аннотирования: вы можете предложить свой ручной труд, организовать площадку и/или поставлять специализированное ПО для разметки.
- Сбор и предоставление датасетов на коммерческой основе.
- Участие в соревнованиях по анализу данных или предоставление сервиса, позволяющие такие соревнования хостить.
- Работа с синтетическими данными: создание цифровых копий реальных объектов с использованием специальной аппаратуры; рендеринг разнообразных сцен с этими объектами; предоставление вычислительных мощностей для рендеринга.
Материалы по теме:
Кто ты в анализе данных? Десять ролей в команде дата-аналитиков
Нужно остановить big data: «темная сторона» больших данных, о которой вы, возможно, не задумывались
Руководство по конфиденциальности в интернете – как обезопасить свои данные
Как данные из социальных сетей влияют на стоимость медицинских услуг в США
Четыре ошибки в резюме, которых следует избегать аналитикам данных
Фото на обложке: Unsplash

-
Партнёрский материал Как компании из Архангельска растут на терпении, связях и самоиронии 29 мая 2026, 14:33

-
Искусственный интеллект Нам не нужен свой OpenAI: где России искать эффект от ИИ и что для этого делать 19 мая 2026, 11:00

-
Бизнес «Команде не вырасти выше лидера»: как изменить неписаные правила взаимодействия в группе 19 мая 2026, 10:00

-
Бизнес «Малый бизнес драйвит всё»: как компании из Архангельска растут на терпении, связях и самоиронии 25 мая 2026, 18:03

-
Ритейл Когда ручная отчётность мешает компании расти: как ускорить аналитику в фешен-ретейле 16 апреля 2026, 18:29

-
Деньги Персональные данные и цифровой след: кто и как на них зарабатывает 27 марта 2026, 10:11

-
Технологии Подключённые автомобили: как интернет меняет автопром 25 марта 2026, 13:17

-
Банки Владимир Скворцов: «Наша задача — снизить страховые риски клиента и быстро выплатить, если что-то случится» 19 мая 2026, 16:00









-
Бизнес В 2026 году в России не открылось ни одного иностранного магазина — компании останавливает сложная логистика 29 мая 2026, 20:30

-
Бизнес SpaceX снизила оценку до $1,8 трлн — даже с такой капитализацией корпорация войдёт в топ-10 публичных компаний 29 мая 2026, 20:00

-
Технологии Минцифры даст отсрочку по импортозамещению — участники особо значимых проектов перейдут на российское ПО к 2036-му 29 мая 2026, 19:30

-
Россия В Авито теперь можно оформить автокредит для покупки машин у частных продавцов — сервис уже доступен в 8 городах РФ 29 мая 2026, 19:00

-
Бизнес Предприниматели в России стали чаще изучать темы управления бизнесом — 70% ищет финансирование через гранты и торги 29 мая 2026, 17:46

-
Бизнес «Аэрофлот» рекомендовал выплатить дивиденды за 2025 год в размере 21 млрд ₽ — это 100% скорректированной прибыли 29 мая 2026, 16:20

-
Маркетплейсы Wildberries запустит продажи товаров из Индии и Южной Кореи — в компании видят тренд «на всё корейское» 29 мая 2026, 21:00

-
Маркетплейсы Россияне смогут жаловаться на Ozon и Wildberries через Госуслуги: доступные темы обращений — проблемы с возвратами 29 мая 2026, 18:26








