
«Надо по-настоящему болеть этим». Дата-сайентист – о своей работе

В каждой профессии есть своя рутина. В случае с дата-сайентистом – это работа с сырыми данными. На нее уходит около 80% времени: нужно подготовить их и привести к правильному формату. И только после этого начинается интересное – подготовка моделей, проверка гипотез, эксперименты и интеграция в продукт. Поэтому важно найти компанию, чей продукт бы того стоил – приносил драйв и осознание крутости, – чтобы не пришлось тратить драгоценные 80% на то, что никому не принесет радость. Евгений Терпиль, дата-сайентист в YouScan, рассказывает о своей работе.
Меня зовут Евгений Терпиль, я из YouScan (система мониторинга и анализа соцмедиа), работаю дата-сайентистом уже около 3 лет и за это время успел обучить не один десяток моделей.
Как проходит мой рабочий день
Свой рабочий день я начинаю с кофе и чтения англоязычных медиа. В моей профессии, если хочешь быть в курсе трендов, надо достаточно хорошо знать английский, чтобы читать о новых технологиях, ведь все самые последние интересные новости появляются в среде англоязычных разработчиков. В основном я читаю блоги на Medium и научные статьи на arxiv.org – архив электронных публикаций и препринтов Корнелльского университета, ставшего настолько популярным, что там стали публиковаться все основные новинки сферы data science и machine learning.
Также регулярно заглядываю в ODS (open data science) чат – это русскоязычное slack-коммьюнити для общения с единомышленниками, которое сейчас насчитывает более 12 тысяч пользователей. Из локальных ресурсов можно еще выделить группу в ВК Deep Learning и, конечно же, «Хабр», где всегда можно найти интересные кейсы, он вообще интересен своим прикладным контентом. Но все же первыми всегда появляются новости в англоязычных ресурсах, и за ними нужно следить.
В условиях глобализации разрыв между нашими дата-сайентистами и зарубежными уменьшается.
Большинство научных статей сейчас публикуются в открытом доступе. Тe же Google и Facebook регулярно выкладывают детальное описание работы их алгоритмов и широко анонсируют новые модели state-of-the-art на различных научных конференциях. Поэтому при наличии необходимого количества данных и вычислительных ресурсов даже небольшие компании могут позволить себе использовать такие же технологии, как и мировые гиганты.
Если же говорить про сервисы анализа соцмедиа, то тут все еще наблюдается некоторое отставание, которое в первую очередь связано с объемом рынка и развитием маркетинга. Например, функцию распознавания логотипов на фото пользователей западные коллеги запустили раньше. Зато мы в довольно короткие сроки смогли у себя построить систему, которая на многомиллионном потоке онлайн распознает и логотипы, и контекст изображения. При аналогичном качестве распознавания нам удалось сделать стоимость этой услуги в разы меньше западных аналогов.
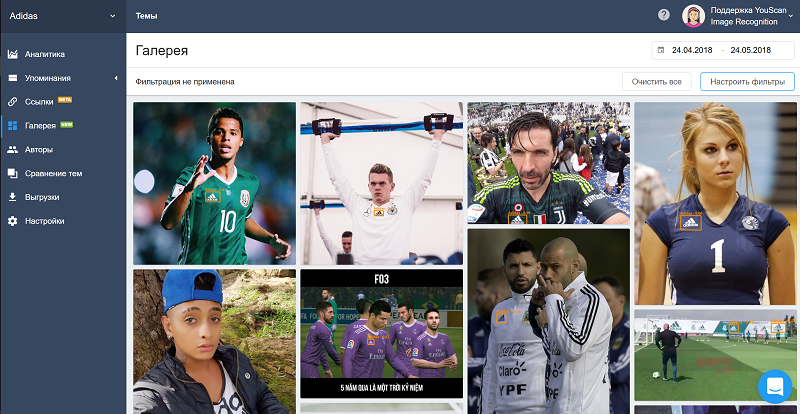
Теперь мы можем находить упоминания бренда в соцмедиа, даже если в тексте нет его названия — достаточно, чтобы на опубликованной пользователем фотографии или картинке присутствовал логотип.
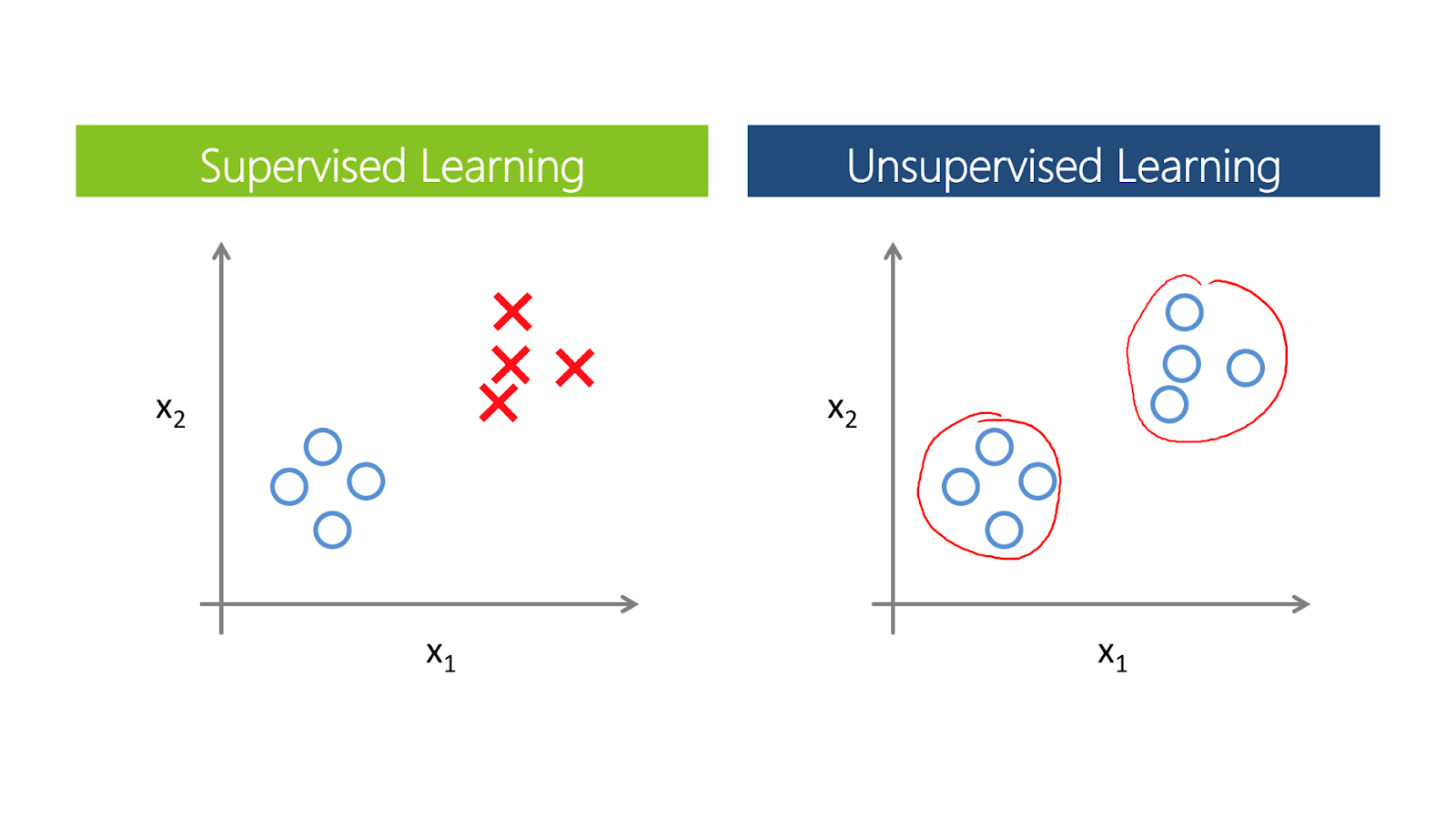
Итак, изрядно напившись кофе и начитавшись всего, что надо знать дата-сайентисту, я прихожу в офис, вместе с ребятами принимаюсь за свою работу. Это обработка и подготовка данных, проверка на них различных гипотез, составление моделей и их обучение. Само обучение происходит на основе supervised- и unsupervised-методов (по-нашему – с учителем и без учителя).
Если для части данных мы наперед знаем класс, к которому они относятся, например, тональность сообщения, то мы имеем дело с обучением с учителем. Наша задача заключается в том, чтобы по небольшой выборке обучить модель различать классы. Однако чаще готовой разметки в данных просто нет. В таком случае можно использовать методы обучение без учителя, которые помогают определить структуру данных и выделить различные кластеры.
Часто, помимо обучения модели, приходится проверять различные гипотезы на данных. Например, возникает гипотеза: «Пользователи, которые от нас уходят раньше других, не используют автоматические правила системы. Соответственно, нужно мотивировать их использовать данную функцию, чтобы они получали больше ценности от самого продукта, который у нас потребляют».
Звучит логично, но все равно нужно проверить, подтверждают ли это данные. Если корреляция между использованием автоправил с оттоком пользователей окажется действительно значимой, мы будем вносить изменения в продукт, стимулируя пользователей ее использовать. Однако в большинстве случаев лучше просто обучить модель и проанализировать, какие признаки больше всего влияют на отток пользователей. Там могут оказаться вполне неочевидные вещи, на которые никто бы никогда и не подумал и, соответственно, правильная гипотеза могла даже и не возникнуть.
В общем, рецепт простой: отдаем данные машине, которая уже знает, как обучаться, нажимаем кнопку и идем пить кофе, ожидая интересных инсайтов.

Команда YouScan на конференции #aiukraine2016
Так мы готовим и запускаем новые алгоритмы. Можем, конечно, не предугадать какие-то параметры, тогда придется переосмыслить модель и начать снова. Только путем многочисленных экспериментов и проверки альтернативных вариантов добиваешься эффекта.
Весь же процесс разработки «умной» фичи для нашей системы можно условно разбить на несколько этапов:
- исследование (например, мы изучаем, какие в мире есть технологические подходы в распознавании картинок);
- эксперимент (внедрение какой-то определенной модели на своих данных. Например, есть модель, по которой происходит распознавание котиков и собак на фото пользователей соцсетей и, возможно, позволит так же хорошо распознать колу и пепси. Но не факт – надо провести эксперимент);
- прототип (этап proof of concept, мы допиливаем модель и вместе с разработчиками на основе ее строим сервис, который представляем на внутреннем demo);
- внедрение в продукт (к процессу подключаются продуктологи, маркетологи, дизайнеры, чтобы сделать из всего, что мы наворотили, продукт, каким его будут видеть конечные пользователи).
Все! Победа! Идем праздновать или играть в настольный теннис у нас в офисе.

О профессии
В эту профессию идут люди, которые любят математику. Не стану спорить, наверное, можно из кого угодно сделать дата-сайентиста, если есть сильное желание. Но без фундаментальных знаний в математике и информатике будет довольно трудно: хотя бы на базовом уровне надо разбираться в теории алгоритмов, теорвере, матстате, численных методах, уметь программировать на Python. И надо по-настоящему болеть этим. Таких сразу видно – они постоянные участники всевозможных хакатонов, конференций, соревнований, имеют какие-то свои проекты на «Гитхабе», активно пишут на форумах и чатах.

5-ый Московский Data Fest. Data Fest — крупнейшая конференция, объединяющая исследователей, инженеров и разработчиков, связанных с data science, machine learning и artificial intelligence.
Когда меня спрашивают, что нужно делать, чтобы стать успешным дата-сайентистом, если не окончил специализированный вуз, я, конечно, советую пройти профориентационные онлайн-курсы. Coursera и другие MOOC-курсы – отличный трамплин для старта карьеры в DS. Отдельно стоит отметить платформу для соревнований Kaggle, на которой можно тестировать свои решения, обучаться, обладая доступом к множеству полезных материалов и решениям победителей различных machine learning-задач.
Сам я закончил Киевский политех и еще студентом интересовался нейронными сетями Social Network Analysis. Как многие другие, начал карьерный путь в роли фронтенд-разработчика в одном B2B-проекте. Однако при этом все время присматривался к Data Science и в YouScan решил окончательно переквалифицироваться. В основном мне как раз помогли специализированные онлайн-курсы и хороший математический бэкграунд. И моя история не уникальна, сейчас больше половины дата сайентистов – это бывшие разработчики, которые решили попробовать что-то новое. Если еще 5 лет назад количество вакансий, связанных с машинным обучением, можно было перечислить по пальцам, то сейчас их сотни, если не тысячи.
В моем отделе сейчас 5 человек. Этих пятерых мы подбирали довольно долго и единого подхода у нас не было. Кто-то нам сам писал с предложением, с кем-то познакомились на регулярных встречах комьюнити, недавно взяли интерна по результатам рейтинга курса по data science, в организации которого мы приняли участие. В итоге сложилась команда, с которой мы делаем крутые проекты в СНГ.
О слабом искусственном интеллекте
Вот сейчас, например, мы занимаемся тем, что работаем с анализом тональности. Это, пожалуй, одновременно и самая классическая, и самая сложная задача в нашей индустрии.
Тональность – это вербальное выражение отношения к тому или иному предмету. Она бывает позитивная/нейтральная/негативная. Но ведь мы работаем с «живым» контентом, который генерируют пользователи в соцсетях, оттенки их позитива/негатива иногда трудно уловимы, а самое сложное – это ирония или сарказм, которые могут быть выражены в какой угодно тональности. А от ошибки в оценке высказывания иной раз зависит маркетинговая стратегия наших клиентов.
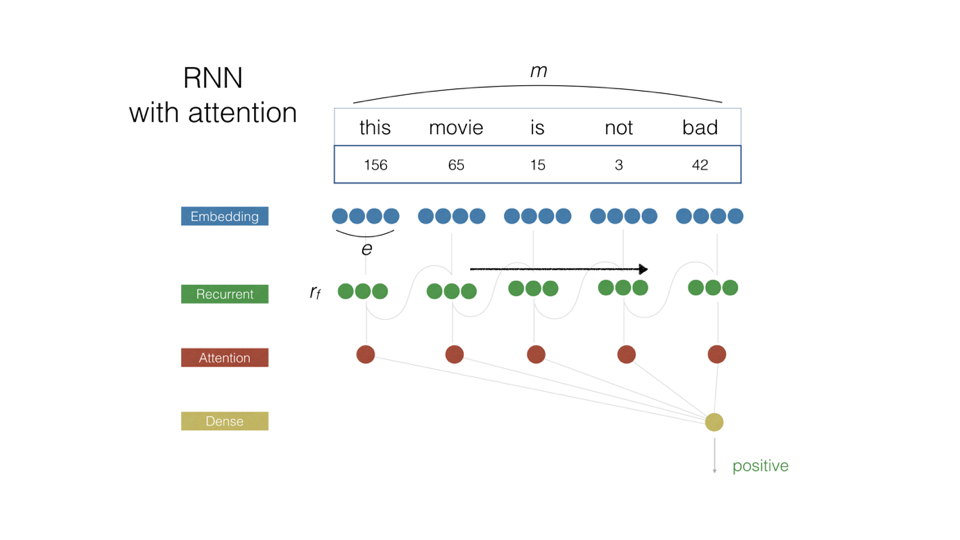
Новая модель на основе рекуррентных нейронных сетей лучше понимает специфику упоминания, за счет этого удалось уменьшить количество ошибок в несколько раз.
Еще одной сложностью при определении тональности является то, что одни и те же слова могут иметь как негативный, так и позитивный оттенок в зависимости от того, о чем именно идет речь. Например, «Фейри помог хорошо отмыть грязную кастрюлю» – позитивное упоминание, но когда кто-то пишет, что кока-кола помогла хорошо отмыть кастрюлю – то это негатив, поскольку кока-кола никак не заинтересована в том, чтобы их бренд ассоциировался с моющим средством.
Мы учим наш новый алгоритм справляться с подобными трудностями. В основе модели заложены глубокие нейронные сети с рекуррентными слоями памяти и слоями, которые выбирают на какой части сообщения концентрировать свое основное внимание в зависимости от контекста, объекта и тематики. Благодаря большой обучающей выборке мы смогли научить модель понимать, о чем и как говорят в социальных сетях, чтобы хорошо определять тональность для разных брендов с учетом их специфики. Поэтому при наличии размеченных данных, даже такие специфические кейсы, как в примере с кока-колой, не являются проблемой – алгоритм будет их «понимать».
Доклад YouScan о тональности на Data Fest 5.
Что будет дальше?
Дальше, анализ контента станет сложнее. Мы научимся анализировать и видео – от stories пользователей до каналов блогеров на YouTube. Ведь видео – это просто набор картинок, которые мы уже умеем анализировать.
В целом искусственный интеллект продолжит свое развитие. Однако не стоит забывать, что в течение всей своей истории ИИ знал много «зим». В основном они все были связаны с завышенными ожиданиями индустрии в отношении таких систем. Так, после активного старта развития в 60-х многие ученые верили в возможность построения универсальных роботов уже через несколько десятков лет.
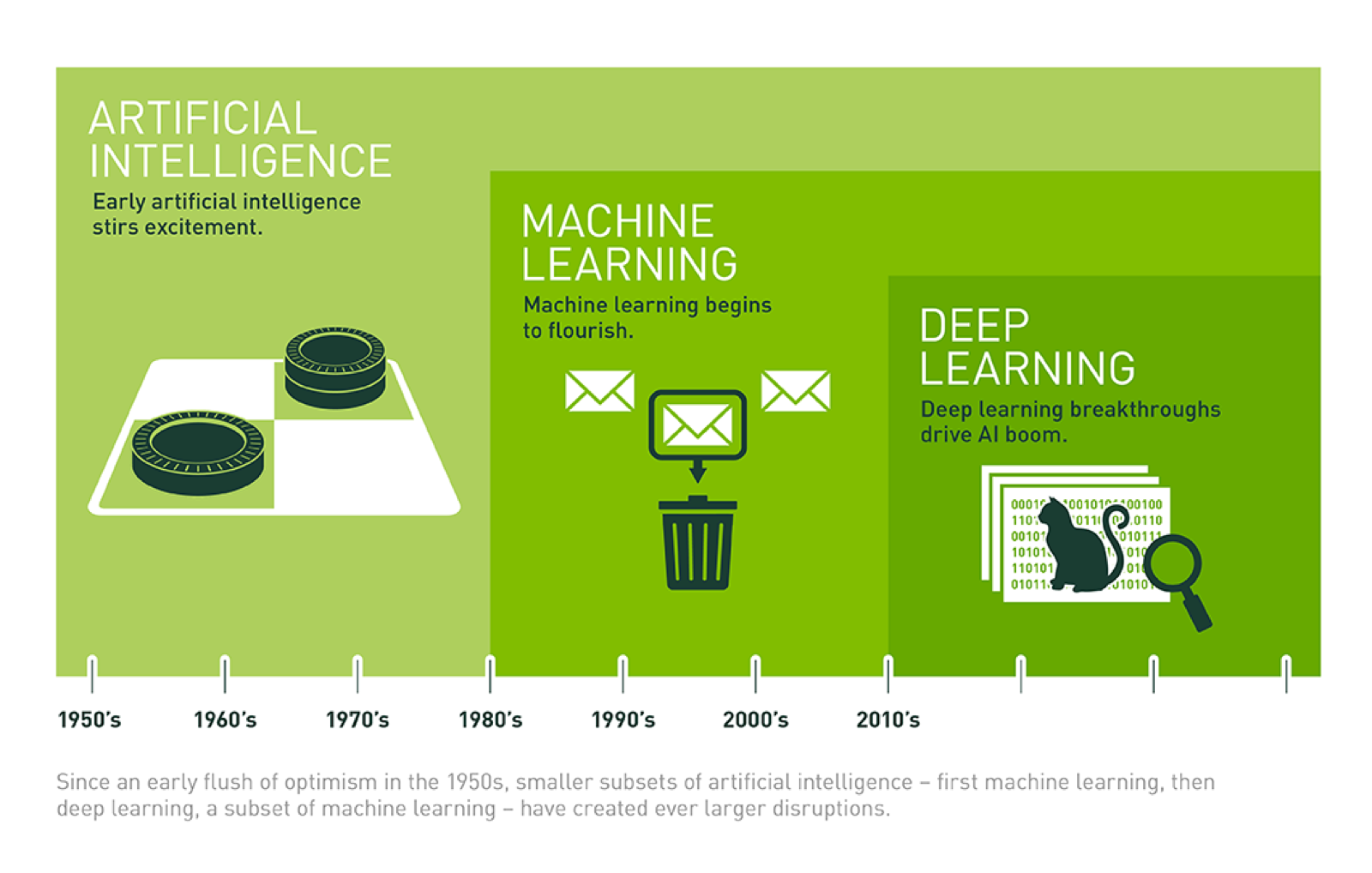
Однако на данный момент мы можем похвастаться разве что роботами пылесосами и автоматизацией только самых простых функций на предприятиях. Не смотря на то что за последние пару лет удалось разработать эффективные системы распознавания лиц, управления беспилотным автомобилем и многое другое, по сути своей, они являются слабым искусственным интеллектом, так как представляют собой лишь небольшой набор алгоритмов, заточенных под конкретную задачу (система, которая управляет автомобилем не сможет с вами сыграть в шахматы и наоборот).
Но я оптимист и верю, что рано или поздно, мы все-таки дойдем до сильного искусственного интеллекта и настоящих роботов.
Материалы по теме:
«Специалисты, которых мы будем нанимать в следующие 10 лет, должны быть сильны в математике»
Почему так много дата-сайентистов бросают свою работу
9 ошибок в работе с большими данными, которые делают руководители компаний
Что нужно знать начинающему дата-сайентисту
Вас наняли на работу с помощью больших данных (правда или миф?)
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Популярное
Налог на прибыль организаций
Материалы по теме
-
Пройти курс «Как построить личный бренд»

- 1 Большие данные и ИИ стали драйвером роста российской экономики По прогнозам, к 2030 году вклад ИИ и big data в ВВП страны достигнет 10,6 трлн рублей 18 апреля 14:00
- 2 Как вывести работу с данными на новый уровень: кейс по комплексному анализу данных с помощью RnD Рассказываем об уникальной методологии анализа данных 20 марта 19:52
- 3 Машинное обучение и большие данные: как они связаны? Прежде чем данные смогут «обучить» алгоритмы машинного обучения, они проходят этапы 19 марта 06:30
- 4 Топ-7 идей Data Science проектов — пет-проекты и примеры анализа данных Полезные проекты на каждый день 03 марта 18:55