Мы оптимизируем бизнес-процессы с помощью ML уже почти 2 года. Каких результатов удалось достичь?
Кейс Qlean
Федор Брюховецкий, аналитик данных команды Core в Qlean, рассказывает, зачем в компании внедрили машинное обучение, и называет бизнес-процессы, оптимизированные с помощью ML-моделей.
Что такое Machine Learning?
Технологии машинного обучения и предиктивного анализа стремительно ворвались в тренды последних лет. В общих словах, Machine Learning (ML) – классы алгоритмов, позволяющие компьютеру делать выводы на основании данных, не будучи явно запрограммированным. В основе моделей машинного обучения лежат такие принципы, как математическая статистика, теория вероятности, линейная алгебра, теория оптимизации и другие.
Одно из направлений ML – это обучение без учителя. В этом случае компьютер будет самостоятельно искать закономерности в данных. Такой подход может применяться, например, для выявления фрода в бизнес-процессах.
Другое направление – это обучение с учителем. В этом случае компьютер получает большой массив примеров и старается обобщить их, используя для дальнейшего прогнозирования. Работает это так: зная, как реагирует клиент или клинер в конкретной ситуации, мы можем создать алгоритм, обобщающий их поведение. По сути, данные типа «ситуация – реакция пользователя» формируют обучающую выборку для ML. Важными факторами являются как объем обучающей выборки, так и грамотная оценка способности полученной модели к обобщению.
Зачем это нам?
Основной целью внедрения решений на базе ML было поддержание гармоничного роста компании путем эффективного управления спросом со стороны клиентов и предложением со стороны клинеров.
В основе поставленной цели была простая логика – делая оценку текущих заказов и предсказывая изменения факторов на будущее, мы сможем заранее выработать наиболее оптимальные сценарии обработки заказов. Как следствие – повышение качества нашего продукта и минимизация операционных издержек.
Понимая, что алгоритмы ML не создают каких-то новых бизнес-процессов, а лишь оптимизируют существующие, мы пересмотрели часть из них. Именно выстроенные бизнес-процессы и накопленные за годы работы данные о клиентском и клинерском поведении позволили нам начать процесс внедрения предсказательной аналитики в Qlean. Прошло уже практически два года, как мы сделали первые шаги в оптимизации наших процессов с помощью ML.
Откуда брали данные?
Итак, первый шаг – это собрать воедино данные о заказе и о поведении клиентов и клинеров. Для этого мы использовали разные данные:
- логи изменений заказов
- логи клинероской активности
- логи клиентской активности
- метаданные о заказе, клинере и клиенте
- данные из нашей CRM-системы
- комментарии и отзывы клиента
- внешние данные (праздничные дни, тренды поисковых запросов и пр.)
Что мы делали с данными?
После сбора данных начинается второй шаг: их предобработка, исходя из конкретного бизнесс-процесса и цели. Очевидно, что параметры, имеющие хорошую предсказательную способность для одного процесса, могут быть полностью бесполезны для другого. Например, положение квартиры может влиять на «привлекательность» заказа для клинера, но быть полностью бесполезным при оценке вероятности отмены этого заказа клиентом. Таким образом, второй шаг обычно состоит из:
- первичного отбора факторов, основанного на бизнес-логике
- очистки и предобработки данных
- генерации новых факторов
В итоге мы получаем набор параметров, создающих для Qlean «портрет личности» с его набором предпочтений, привычек и особенностей в рамках конкретного процесса. Это важный шаг перед заключительным этапом отбора значимых параметров, построения самой предиктивной модели и началом ее эксплуатации.
Как это работает?
Мы выделили ключевой для нас бизнес-процесс – процесс создания и распределения заказов – и решили его автоматизировать при помощи ML в первую очередь. Ниже приведу несколько конкретных примером применения предиктивного анализа у нас в компании.
- Управление доступными слотами
Один из базовых процессов в Qlean – это управление доступными слотами (временным диапазоном доступным для создания заказа). Оптимальное открытие и закрытие слотов дает возможность максимизировать количество выполненных заказов, не допуская овербукинга. Cлоты во внутреннем аналитическом отчете:
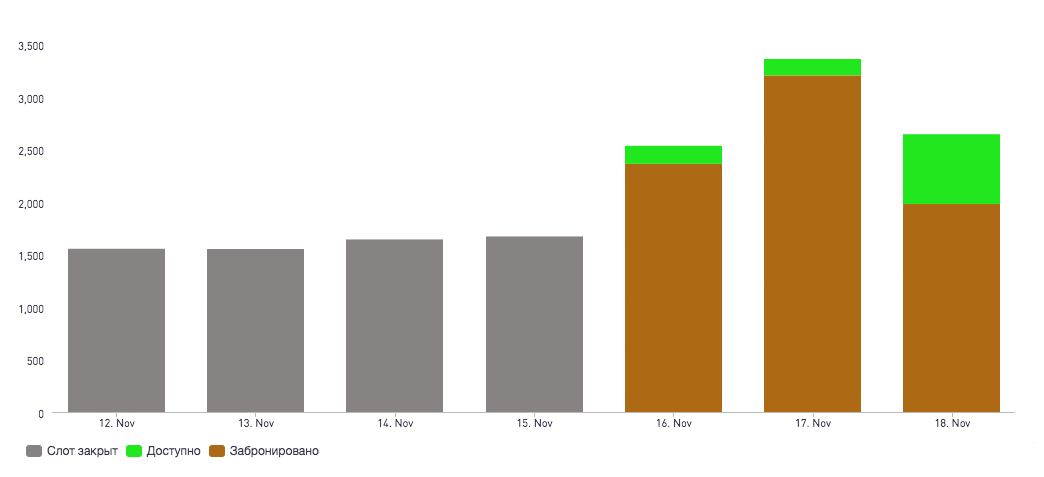
Те же слоты, но уже на главное странице Qlean:
Для прогноза доступного количество слотов на несколько дней вперед мы должны уметь точно предсказывать количество активных клинеров, что равнозначно предсказанию Supply на каждый день. Сначала задачу предсказания количества активных клинеров мы решили с помощью модели градиентного бустинга, оценивая вероятность выхода на работу конкретного клинера в конкретный день.
Этот подход хорошо работал для старых клинеров, но при большом притоке новых точность модели сильно упала, и нам пришлось пересмотреть подход. Сейчас мы перешли к оценке самого тренда изменения количества клинеров и используем модель авторегрессии и скользящего среднего, при этом относительное отклонение не превышает 5%.
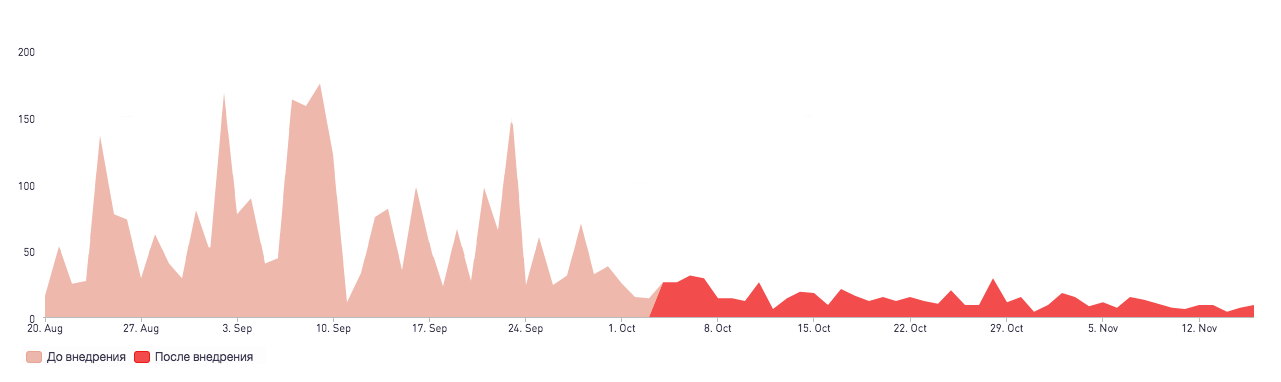
- Прогнозирование неприезда клинера
Даже при оптимальном управлении слотами какие-то заказы остаются нераспределенными между клинерами и в конечном счете не будут выполнены. На решение клинера взять заказ влияет ряд факторов: удаленность заказа, время дня, количество комнат, попадание даты старта заказа в «сезон отпусков» и другие. Как компания, в случае неприезда клинера, мы стараемся компенсировать неудобство клиенту путем выплат бонусов.
Это решало проблему в конкретном случае, но для системного подхода необходим был инструмент для прогнозирования таких заказов. Поэтому мы создали модель для оценки вероятности распределения заказа, основанную на логистической регрессии, и выделили отдельный процесс для обработки таких заказов. Как результат, снижение количества неприездов на 60% в первые две недели после внедрения относительно такого же временного промежутка до внедрения.
- Ложные заказы
Также одна из бизнес-задач, которую мы решили при помощи Machine Learning, – это борьба с ложными заказами. Ложным заказом считается тот, на который приехал клинер, но который оказался неактуальным, например, клиент оформил заказ по ошибке или забыл о нем. Это проблема для нас по нескольким причинам:
- мы компенсируем клинеру издержки, связанные с этим заказом
- фактически сокращаем наш Supply, «теряя» клинера на таком заказе
Для решения этой проблемы мы создали модель оценки вероятности отмены заказа со стороны клиента на базе алгоритма градиентного бустинга. Теперь, анализируя поведение клиента и принимаемые им решения, характеристики его заказа и подписки, мы можем с высокой вероятностью предсказывать ситуации с ложным заказами и заранее их обрабатывать.
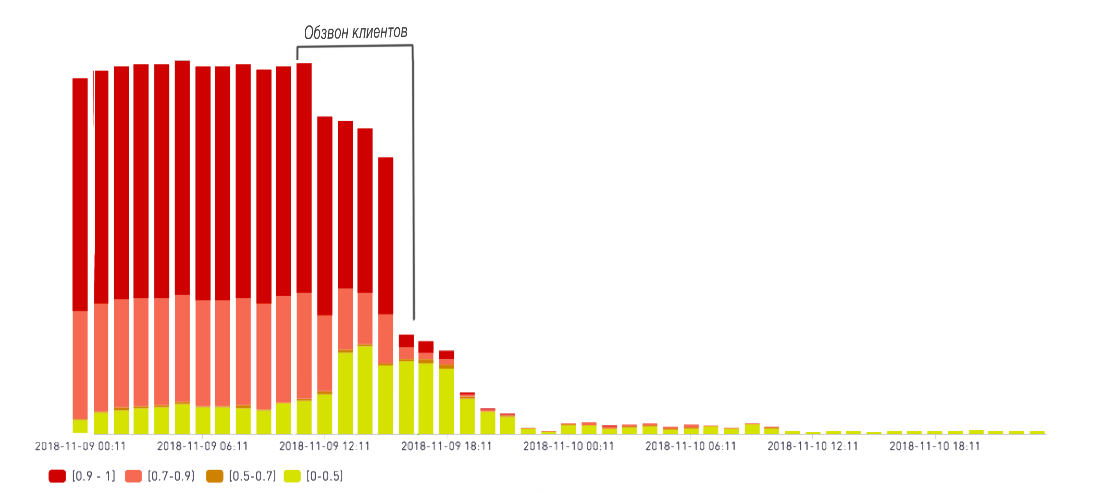
А именно, мы классифицировали заказы по вероятности их отмены и начали обзванивать пользователей для уточнения актуальности их заказов. В случае, если заказ действительно становится неактуальным, мы его закрываем. Таким образом, мы оставляем для клинеров только актуальные заказы, снижая количество «холостых» выездов к клиенту.
На графике ниже приведен пример динамики изменения количества нераспределенных между клинерами заказов на конкретный день. Как видно, наиболее стремительное снижение происходит в период обзвона клиентов среди заказов с наибольшей вероятностью отмены.
Выводы
Даже не самые сложные модели машинного обучения, действительно, способны помочь бизнесу. Это популярное и динамично развивающееся направление, которое активно внедряется во многих компаниях. Мы решили многие задачи, оптимизировав процесс обработки и распределения заказов, а также минимизировав убытки. Тем не менее не стоит гоняться за хайпом и стремиться запустить машинное обучение, чего бы это не стоило. Оцените насколько это необходимо, а именно:
- выстроены ли в компании бизнес-процессы
- есть ли четко сформированная цель
- достаточно ли исходных данных в вашей компании
В противном случае ML может стать бесполезной инновацией.
Материалы по теме:
Машинное обучение в юридической сфере: почему будущее еще не наступило
Разработка решений data science: плюсы, минусы и основные трудности
Как повысить продажи в три раза с помощью Big Data и машинного обучения?
Почему ваш проект по машинному обучению может потерпеть неудачу: как этого избежать
30 самых удивительных проектов по машинному обучению
Фото на обложке: Unsplash
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Автомобили От гоночной трассы до «Матрицы»: история Ducati 10 июля 2026, 23:39

-
Личное Оливер Блюме. Немецкий инженер, который должен снова сделать Volkswagen великим 09 июля 2026, 21:27

-
Автомобили Как машина для гонок стала символом тихих денег: история Bentley 09 июля 2026, 02:55

-
Личное Сундар Пичаи. Как эмигрант из Индии за 11 лет прошёл путь от продакт-менеджера до CEO Google 08 июля 2026, 23:19

-
Личное Криштиану Роналду. Как сын уборщицы первым в истории футбола заработал 1 млрд $ 06 июля 2026, 20:16

-
Искусственный интеллект Цифровизация начинается не с ИИ: эксперты рынка — о том, почему для трансформации бизнеса нужно изменить мышление 03 июля 2026, 11:58

-
Искусственный интеллект Нам не нужен свой OpenAI: где России искать эффект от ИИ и что для этого делать 19 мая 2026, 11:00









-
Автомобили «Яндекс» запустил роботакси в Москве — но только для сотрудников: сервис проверяют перед коммерческим запуском 10 июля 2026, 19:40

-
Бизнес Разработчик электромобиля «Атом» погасил долги по зарплате — некоторым сотрудникам не выплачивали деньги 1,5 месяца 10 июля 2026, 17:00

-
Ритейл Российский бренд одежды Present & Simple закрывает все магазины — компания готовится к перезапуску бизнеса 10 июля 2026, 13:00

-
Искусственный интеллект Китай может ограничить иностранцам доступ к передовым ИИ-моделям — российский бигтех не видит повода для паники 11 июля 2026, 08:00

-
Технологии Instagram* может изменить дизайн приложения — из него исчезнет бесконечная лента контента 10 июля 2026, 19:10

-
Автомобили Китайский ESTEO открыл предзаказы на внедорожник MX — по цене от 3,89 млн ₽ 10 июля 2026, 16:15

-
Искусственный интеллект OpenAI объявила о закрытии браузера ChatGPT Atlas — он просуществовал меньше года 10 июля 2026, 13:45

-
Реклама Альфа-Конфа соберёт лидеров HoReCa в Казани: предприниматели обсудят, что помогает ресторанам расти 07 июля 2026, 17:31








