Почему ваш проект по машинному обучению может потерпеть неудачу: как этого избежать
Четыре фактора успеха
Александр Азаров, старший вице-президент по разработке ПО в WaveAccess, рассказывает, что нужно учитывать компаниям при создании ML-проектов, и выделяет четыре фактора, которые важны для их успеха.
Машинное обучение во всем мире перешло на этап продуктивности: об этом говорит аналитика Gartner, это многотысячными инвестициями поддерживают ИТ-директора и СЕО. Их компании десятилетиями копили данные — пришло время извлекать из них выгоду.
Но не все так просто. При доработке систем клиентов мы часто наблюдаем повторяющиеся ошибки. В проекты по машинному обучению вкладываются в надежде улучшить положение компании на рынке, а проекты десятками сходят с рельс.
Разработки на базе ML (machine learning) часто обходятся неоправданно дорого, системы работают медленно. А ведь проект нельзя воспринимать как научное изыскание, он должен приносить выгоду.
Наша команда реализовала десятки рентабельных проектов на основе технологий machine learning, среди которых — обладатели международных наград Microsoft. Обобщив свой опыт, мы сформировали базовый подход к планированию и разработке. Да, конечно, подход — это не единственное, что помогает успешно реализовать ML-решение. Нужна сильная команда, мотивация, редкие и сложные компетенции. Но практика показывает, что проекты «выстреливают» во многом благодаря грамотному планированию и корректировке ожиданий.
В статье мы подробнее расскажем о процессе и подтвердим его кейсами. Пусть это поможет бизнесу не тратить огромные ресурсы впустую.
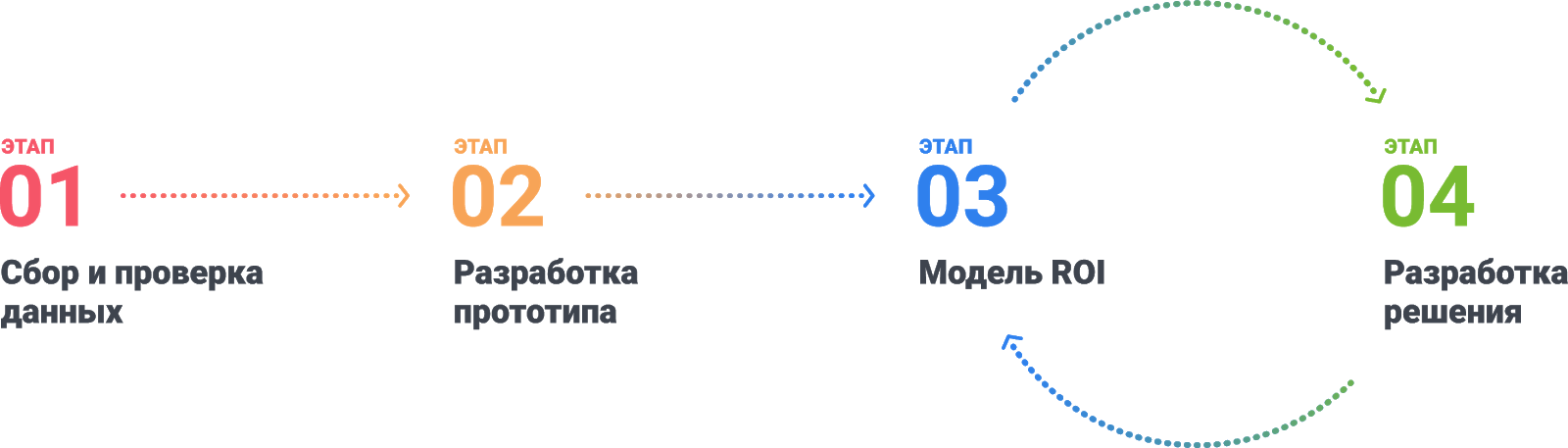
Этап 1. Сбор и подготовка данных
Рафинированные реалистичные данные в должном количестве — идеальная основа, на которой проще всего построить рабочую систему. Но не следует выдавать желаемое за действительное: данные редко бывают именно такими.
Количество имеет значение
Для ML-проектов принципиально важно количество данных. Если их мало (от 10 тысяч до 100 тысяч фактов), то предсказание сделать крайне сложно. На этом уровне средства ML будyт работать не лучше статистики, и дешевле применять последнюю. В этом случае мы помогаем выстроить процесс отбора: встроиться в системы заказчика, начать сбор фактов, которые кажутся нам перспективными. До этого момента мы ничего не обещаем и не делаем оценок по срокам.
Бизнес порой пребывает в приятном заблуждении, что данные за несколько лет работы хранятся в одной реляционной базе данных (БД). На практике данные хранятся в трех разных поколениях БД, а оставшаяся их часть — в системе 1С. Для нормальной работы их придется сводить к одному знаменателю. Это выливается в самостоятельную большую интеграцию, на которую нужно закладывать достаточно ресурсов.
Закрытая информация. Наш подход к решению проблемы
Бизнес справедливо относится к данным своей компании как к капиталу. Часто они скрыты даже от сотрудников, что уж говорить о сторонней команде разработки. На этот случай в нашей компании используется подход, который мы называем «луноход». До решающей отправки на Луну советские луноходы тестировали на земном полигоне, где были смоделированы условия, близкие к реальным. У нас аналогичная схема.
Если клиент еще не готов делиться базами, мы просим у него небольшой датасет — набор реальных, но обезличенных данных о его бизнесе. Что дальше происходит с датасетом? На его основе строится модель.
Инсталлятор, прототип, тестировщик пакуются и в виде пакета отсылаются на удаленный сервер. Происходит обучение, идет проверка, делаются выводы.
Это win-win-подход. Клиент не показывает нам закрытых данных, пока мы не ударили по рукам. А мы можем увидеть, как наша модель поведет себя в реальном проекте.
Пример: данные компаний медицинского страхования
Так, например, часто происходит с медицинскими страховыми компаниями, которые регулируются HIPAA (HIPAA compliance). Другой закон запрещает медицинским страховым фирмам отказывать клиенту в обслуживании, даже если он ведет очевидно нездоровый образ жизни, обладает хроническими заболеваниями — и очевидно невыгоден страховой.
Один наш заказчик в США решил поставлять подобным компаниям ML-систему, которая должна предсказывать повышение расходов на лечение застрахованного клиента. К тем клиентам, которые рискуют скоро заболеть в процессе страхового обслуживания, фирма приставит координатора — специалиста, который внимательно будет вести именно этого человека из группы риска: предложит вовремя сдать анализы, будет побуждать вернуться к здоровому образу жизни.
Именно здесь (в случае с медицинскими данными) наш подход хорошо себя показал. Систему мы уже строили на реальных данных, так как результат прототипа удовлетворил и нас, и клиента.
Результат — наш клиент продает систему медицинским страховым фирмам, и она значительно снижает издержки, связанные с лечением застрахованных клиентов.
В проекте удалось предсказать не только возможную цену будущего лечения, но и конкретные болезни. Например, система даже может прогнозировать возникновение и развитие опиоидной наркомании: мы нашли прямую зависимость от смены образа жизни.
Прочие опасности
Порой бизнес-процесс клиента не исключает внесения в базы ошибочной информации, и эти ошибки потом передаются в прототип. Прототип, не умея отличить ложь от истины, просто обработает то и другое. Затем покажет выводы, а бизнес получит провальные результаты предсказаний.
Ошибки в данных, полученных от клиента, мы отсекаем особенно тщательно. Иначе весь проект может оказаться под ударом.
Этап 2. Разработка прототипа
Разработка прототипа занимает две-четыре недели, на него выделяется команда. Именно этот этап помогает нам понять, достигнем ли мы в проекте нужного процента точности.
Процент точности системы
Разработав прототип, мы смотрим на процент точности, которого удалось добиться с имеющимися данными, и сравниваем его с изначальным запросом клиента. Если прототип предсказывает события на 60-80%, то есть большая вероятность на реальных данных достичь и 90-95%. Если прототип показывает 30%, а клиент ждет 95%, — мы ищем способ создать прототип с другими данными и другим подходом.
Пример: нейросеть, «читающая» медицинские сканы с точностью около 95%
Одним из наших клиентов по разработке ML-проекта стала американская компания, занимающаяся медицинскими услугами. Она предоставляет врачам частной практики устройства для УЗИ-исследований сонных артерий, а также услугу по расшифровке снятого видео. Само устройство по размеру сравнимо с кейсом, врачу удобно его возить к пациенту на дом. Чем больше пациентов врач объедет за день, тем больше его выручка. Поэтому чаще всего врач передает видеозапись для расшифровки на сторону поставщика устройства. Это экономит время и позволяет снять больше сканов за день.
В свою очередь компания-поставщик должна быстро и точно расшифровывать поток видеозаписей: измерять диаметр артерии, искать холестериновые бляшки (если они есть). Эта работа под силу только квалифицированному технику. На каждую расшифровку тратится много времени — нужно несколько раз без ускорения просмотреть запись, вручную измерить диаметр артерии. С ростом базы клиентов приходилось нанимать все больше дорогостоящих техников.
Автоматизировать «чтение» видеозаписи можно только средствами машинного обучения: статистически местонахождение бляшки вычислить нельзя, форма и размер у нее всегда разные. Для этой задачи привлекли нас. Нам передали видеозаписи УЗИ и заключения по видео, и на этом наборе тестовых данных мы обнаружили, что можно:
- детектировать некоторые бляшки с хорошей точностью;
- находить на видео участки артерии, где удобнее всего ее измерять.
Клиент предоставил нам нужное количество тестовых данных и тесно работал с нами: техники периодически просматривали результат предсказаний. Открытость клиента, качество данных и хорошие показатели прототипа позволили обещать высокую точность.
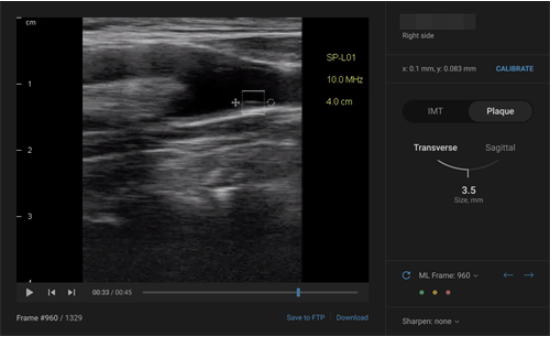
Нейросеть помогает определять области нахождения артерий и распознавать холестериновые бляшки.
В результате поиск четко отснятого участка артерии для измерения ее диаметра ведется с точностью до 95%, детектирование кадров с потенциальной бляшкой — с точностью до 80%. Средняя длительность дешифровки одного видео одним техником упала в 5 раз.
Не все алгоритмы одинаково полезны
Сейчас на слуху различные алгоритмы, платформы с броскими именами. Но далеко не для всех процессов подходят дорогостоящие «нейронки», не всем так уж необходимо покупать данные TrendForce (компания, проводящая маркетинговые исследования для технологических индустрий). Мы удерживаем заказчика от намерения применять те алгоритмы, которые не подходят для решения задач, даже если о них много написано в интернете. Ведь ML-проекты — это 90% подбора лучшего алгоритма и труда и только 10% искусства.
Этап 3. Модель ROI
Прототип и расчет ROI (Return On Investment, окупаемость инвестиций) помогают понять, стоит ли инвестировать в увеличение точности модели. Ведь каждый новый процент может обходиться в десятки раз дороже предыдущего.
Рентабельность проекта важно просчитать заранее и договориться на такой процент точности, который даст достаточно эффекта в сравнении с потраченными деньгами.
Здесь же следует договориться о балансе предсказаний false positive и false negative. Самое, пожалуй, важное, что мы извлекли из своего опыта, — это что 100%-ая точность может вообще быть нерентабельной для некоторых типов бизнеса.
Процессы разработки прототипа и подсчета ROI взаимосвязаны. После прототипа выбирается рентабельный для бизнеса реалистичный процент точности. Во время разработки тоже важно помнить об ожиданиях по прибыли.
Баланс false positive и false negative
Поскольку алгоритм непременно будет совершать ошибки — важно понять, какая ошибка обойдется бизнесу дороже. False positive — это ошибочное представление о том, что какое-то событие произойдет. False negative — о том, что его не произойдет.
Как бы цинично это ни было с общечеловеческой точки зрения, с точки зрения бизнеса порой выгоднее упустить одного пациента с реальной вероятностью болезни, чем создавать много false positive-кейсов и бросать дорогостоящих врачей на их разбор.
Причины полученных результатов
Важно отдавать себе отчет о причинах полученных предсказаний, основываясь не только на мнении системы. Если модель говорит, что некоего события не будет, — мы пытаемся понять, почему его действительно не было. Если, например, пациент страховой компании не пришел на обследование — лучше заранее понять, в чем причина. Иначе это может увеличить расходы на него в будущем. Ведь его отсутствие на обследовании не значит, что он здоров: возможно, он просто не хочет собой заниматься.
Пример: причины роста конверсии
Наш клиент продает авиабилеты первого класса онлайн. Заявки на сайте оставляют состоятельные покупатели — как правило, руководители компаний. У них нет времени подробно заполнять заявку. В то же время агенту перед звонком автору заявки нужно продумывать, что именно он может предложить, и привести этот звонок к продаже.
Задачей ML-системы было оптимизировать работу колл-центра: помочь агенту продумывать состав предложения автору заявки, а также ранжировать заявки в порядке наибольшей вероятности конверсии. Самые качественные заявки переносятся в начало очереди: это те клиенты, которые, по оценке системы, с большей вероятностью сразу поднимут трубку и примут предложение. Из-за небольшого количества данных была поставлена задача-минимум — на этапе разработки прототипа увеличить продажи хотя бы на 6%.
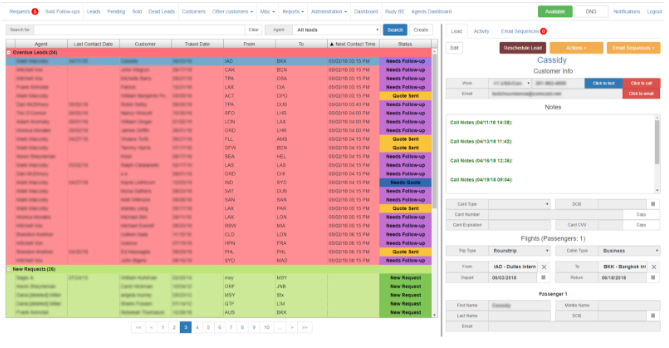
Основанием для предсказаний служит комплексный набор данных: почта клиента и его IP-адрес, геолокация, поведение пользователя на сайте, просмотренные страницы, источник трафика, содержание заявки и другое.
В реальности уже на прототипе мы увеличили конверсию на 17%. Причина оказалась в том, что все запросы поступают в очередь на обработку. Колл-центр обзванивает авторов по порядку, и ему приходится тратить много времени на обработку незаинтересованных лиц. В это время клиенты, которые действительно хотят приобрести билет, ждут и могут передумать. Результаты показали, что индустрия заказчика системы очень чувствительна к своевременности обратного звонка. Алгоритм же указывает на тех клиентов, которые готовы совершить покупку и сразу отзовутся на звонок агента. Благодаря этому ожидание клиентами звонка уменьшилось. Приоритезация заявок дала увеличение продаж на 17% на реальном проекте.
Количество подсистем в прототипе
Когда говорят о машинном обучении, часто подразумевают некую гигантскую модель, которая выдает предсказания. У нас другой подход: мы стремимся делать модели буквально на каждый тип события. В нашем случае практически в каждом проекте есть по пять, а то и по десять моделей, которые прогнозируют различные типы ситуаций в зависимости от процессов компании-клиента. Хотя и здесь не все так просто: такая разработка значительно сложнее и требует большого мастерства и глубокого понимания. Но именно такой подход обеспечивает точность предсказаний.
Например, на бекенде наше приложение по предсказанию заболеваний почти под каждый диагноз имеет свою модель. И в реальном времени может предсказывать не только цену лечения, но и сами болезни, в том числе обострения: тысяча моделей предсказывают тысячу разных диагнозов.
Этап 4. Разработка решения
При разработке систем предиктивной аналитики возникает два «лагеря»: программисты, которые уже много лет разрабатывают системы на рынке, и специалисты по машинному обучению, data scientists. Между ними начинается борьба за приоритет позиции.
У разработчиков больше знаний о технологии программирования, но недостаточно знаний о тонкостях профессии data scientist и потребностях систем. При разработке мы ищем баланс между экспертизами всех участников команды, держа в голове ключевые преимущества будущей системы.
Скорость работы и ресурсоемкость
У ML-алгоритмов разная скорость работы. Например, нейронные сети работают медленнее, чем линейная регрессия. Можно минимизировать потребление вычислительных ресурсов, заранее выбрав менее требовательный, но рабочий алгоритм. Важно следить за теми ресурсами, которых модель начнет требовать уже после внедрения.
К примеру, вы создаете модель для предиктивной аналитики большого количества объектов в реальном времени. Может ли оказаться, что затраты на ее поддержку — миллион долларов в месяц? Легко. Рентабельно ли это? Вряд ли.
Существует и иная угроза. Бизнес предоставляет рафинированную базу исторических данных без ошибок, на основе которой создается прототип. Но после выпуска система не способна делать свои предсказания в real time. Если бизнесу требуется аналитика по данным именно в онлайн-режиме, то мы заранее убеждаемся, что данные тоже приходят в систему в реальном времени.
Заключительный (разработка решения) и предыдущий (проработка модели ROI) этапы цикличны: когда решение создано, можно вернуться на шаг назад и посчитать, возможно ли улучшить модель и сколько будет стоить еще несколько процентов точности.
Вместо итога
Итак, для успеха ML-проекта мы выделяем четыре важных фактора:
- Данные. Для успеха проекта нужно собрать как можно больше данных — более 100 тысяч фактов. А если на первых порах бизнес не готов делиться ими, то деперсонализация датасета для пробного проекта — хороший выход из ситуации.
- Прототип. Лучше потратить 2-4 недели на разработку пилотного проекта, но убедиться в жизнеспособности идеи.
- Модель ROI должна быть рассчитана и зафиксирована в самом начале проекта. Она необходима для того, чтобы все убедились: при достижении требуемых характеристик клиент будет получать прибыль с разработки.
- И, наконец, важно заранее предвидеть, каких ресурсов потребует конечная модель, и соблюсти баланс между программистами и data scientists.
В заключение можно добавить: идей о том, что можно предсказать, всегда много. Для реализации стоит выбрать самые маржинальные, так как инвестировать в машинное обучение следует не из любопытства, а ради прибыли.
Материалы по теме:
30 самых удивительных проектов по машинному обучению
Что такое data science и как это работает?
Как применение метода глубокого обучения влияет на эффективность онлайн-кампаний?
Уже не black box. Новые возможности в машинном обучении (и как бизнесу их использовать)
5 примеров того, как искусственный интеллект облегчит вам работу
Фото на обложке: Unsplash
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Искусственный интеллект Компании научились собирать данные. Принимать решения — нет: почему цифры не помогают сами по себе 21 июля 2026, 16:04

-
Искусственный интеллект Нам не нужен свой OpenAI: где России искать эффект от ИИ и что для этого делать 19 мая 2026, 11:00

-
Искусственный интеллект Цифровизация начинается не с ИИ: эксперты рынка — о том, почему для трансформации бизнеса нужно изменить мышление 03 июля 2026, 11:58

-
Игры От нишевой RPG до глобальной франшизы: история Fallout пережила крах создателей и гнев фанатов 21 июля 2026, 20:30

-
Игры Миллиарды долларов на чужих играх: история Valve 21 июля 2026, 11:48

-
Игры Как техническая ошибка превратилась в бизнес на миллиарды: история GTA 20 июля 2026, 15:35

-
Бизнес Как поисковая строка превратилась в бизнес на $400 млрд: история Google 18 июля 2026, 18:00









-
Бизнес Nvidia раскрыла свою долю в Nebius Аркадия Воложа — производителю чипов принадлежит почти 10% компании 21 июля 2026, 20:30

-
Бизнес Иностранных инвесторов могут лишить права на обратный выкуп бизнеса в РФ — их опционы можно отменить через суд 21 июля 2026, 20:00

-
Автомобили Jeland вошёл в топ-10 самых продаваемых марок на авторынке России — спустя всего год после запуска бренда 21 июля 2026, 18:30

-
Банки «Экономика просит снижения, но цены не разрешают»: эксперты оценили вероятность снижения ключевой ставки 24 июля 21 июля 2026, 22:00

-
Автомобили В России начали продавать праворульный кроссовер Subaru Rex — по цене от 1,08 млн ₽ 21 июля 2026, 21:00

-
Технологии Apple готовит iPhone 20 Pro Max размером с планшет — юбилейная модель выйдет в 2027 году 21 июля 2026, 18:00

-
Россия Хостинг-провайдеры просят сохранить отдельный способ верификации для иностранных клиентов — через банковский платеж 20 июля 2026, 21:00

-
Бизнес Авиакомпании Red Wings и SkyGates объединят в единый холдинг — Ростех начал упорядочивать свои активы 20 июля 2026, 14:38








