Что такое data science и как это работает?
Data science на пальцах
Data science, big data, машинное обучение – вы наверняка слышали эти громкие слова, но насколько понятным был для вас их смысл? Для кого-то они являются красивыми маркетинговыми приманками. Кто-то думает, что data science – это магия, которая бесплатно заставит машину делать, что прикажут. Другие и вовсе полагают, что это легкий способ зарабатывать огромные деньги. Никита Никитинский, глава R&D в IRELA и Полина Казакова, Data Scientist, объясняют, что это такое простым и понятным языком.
Я работаю в сфере автоматической обработки естественного языка, одного из приложений data science, и часто наблюдаю, как люди не совсем корректно употребляют эти термины, поэтому мне захотелось внести немного ясности. Эта статья для тех, кто плохо представляет себе, что такое data science и хочет разобраться в понятиях.
Определимся с терминологией
Начнем с того, что на самом деле никто точно не знает, что такое data science, и строгого определения не существует – это очень широкий и междисциплинарный концепт. Поэтому здесь я поделюсь своим видением, которое совсем не обязательно совпадает с мнением других.
Термин data science на русский переводят как «наука о данных», а в профессиональной среде часто просто транслитерируют – «дата сайенс». Формально это набор некоторых взаимосвязанных дисциплин и методов из области информатики и математики. Звучит слишком абстрактно, правда? Давайте разбираться.
Первая часть: data
Первая составляющая науки о данных, то, без чего весь дальнейший процесс невозможен, – это, собственно, сами данные: как их собирать, хранить и обрабатывать, а также как выделять из общего массива данных полезную информацию. Именно очистке данных и приведению их к нужному виду специалисты посвящают до 80% своего рабочего времени.
Важная часть этого пункта – как обращаться с данными, для которых не подходят стандартные способы хранения и обработки из-за их огромного объема и/или разнообразия – так называемые большие данные, big data. Кстати, не дайте себя запутать: big data и data science – не синонимы: скорее, первое подраздел второго. При этом не всегда специалистам по анализу данных на практике приходится работать именно с большими данными – полезными могут быть и маленькие.
Соберем данные
Чтобы не быть голословным, я приведу простой пример. Соберем какие-нибудь данные.
Представьте, что нас интересует, есть ли какая-то взаимосвязь между тем, сколько ваши коллеги по работе выпивают кофе за день, и тем, сколько они спали накануне. Запишем доступную нам информацию: допустим, ваш коллега Григорий сегодня спал 4 часа, так что ему пришлось выпить 3 чашки кофе; Эллина спала 9 часов и не пила кофе вообще; а Полина спала все 10 часов, но выпила 2,5 чашки кофе – и так далее.
Изобразим полученные данные на графике (визуализация – тоже немаловажный элемент любого data science-проекта). Отложим по оси X время в часах, а по оси Y – кофе в миллилитрах. Получим что-то вроде такого:
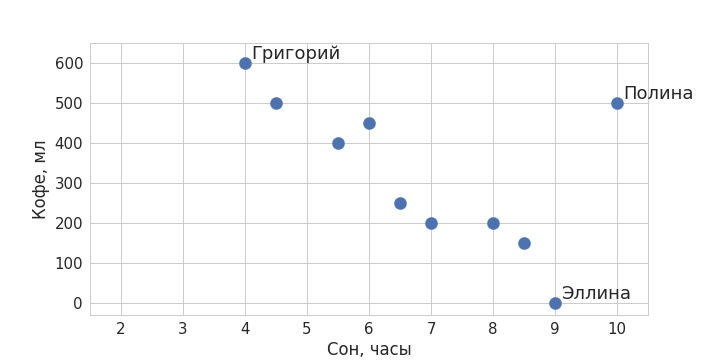
Вторая часть: science
У нас есть данные, что теперь с ними можно делать? Правильно, анализировать, извлекать полезные закономерности и как-то их использовать. Тут нам помогут такие дисциплины, как статистика, машинное обучение, оптимизация.
Они формируют следующую и, возможно, самую важную составляющую data science – анализ данных. Машинное обучение позволяет находить закономерности в существующих данных, чтобы затем предсказывать нужную информацию для новых объектов.
Проанализируем данные
Вернемся к нашему примеру. На глаз кажется, что два параметра как-то взаимосвязаны: чем меньше человек спал, тем больше он выпьет кофе на следующий день. При этом у нас есть и выбивающийся из этой тенденции пример – любительница поспать и попить кофе Полина. Тем не менее можно попытаться приблизить полученную закономерность некоторой общей прямой линией так, чтобы она максимально близко подходила ко всем точкам:
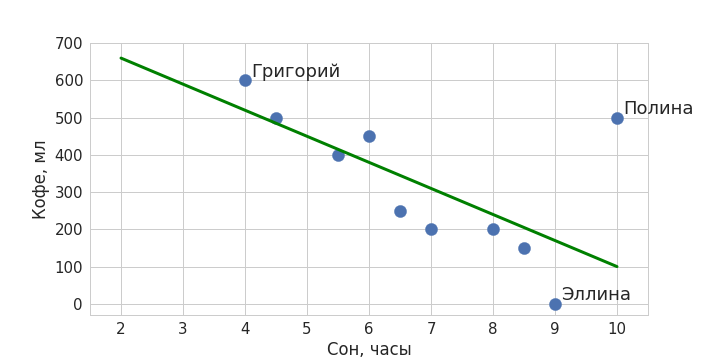
Зеленая линия – и есть наша модель машинного обучения, она обобщает данные и ее можно описать математически. Теперь с помощью нее мы можем определять значения для новых объектов: когда мы захотим предсказать, сколько кофе сегодня выпьет вошедший в кабинет Никита, мы поинтересуемся, сколько он спал. Получив в качестве ответа значение в 7,5 часов, подставим его в модель – ему соответствует количество выпитого кофе в объеме чуть менее 300 мл. Красная точка обозначает наше предсказание.
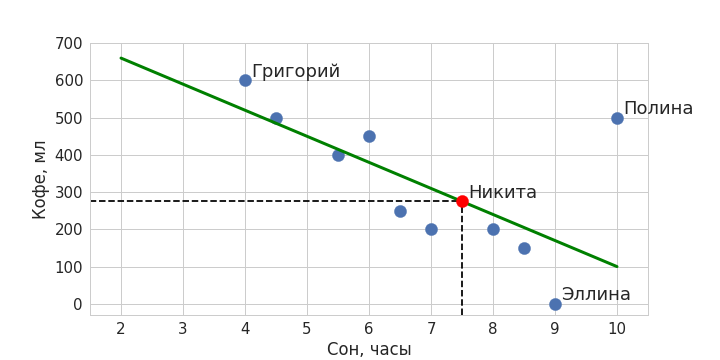
Примерно так и работает машинное обучение, идея которого очень проста: найти закономерность и распространить ее на новые данные. На самом деле, в машинном обучении выделяется еще один класс задач, когда нужно не предсказывать какие-то значения, как в нашем примере, а разбивать данные на некоторые группы. Но об этом мы подробнее поговорим в другой раз.
Применим результат
Однако на мой взгляд, data science не заканчивается на выявлении закономерностей в данных. Любой data science-проект – это прикладное исследование, где важно не забывать о таких вещах, как постановка гипотезы, планирование эксперимента и, конечно, оценка результата и его пригодности для решения конкретного кейса.
Последнее очень важно в реальных бизнес-задачах, когда необходимо понять, принесет ли найденное data science решение пользу вашему проекту или нет. Какова могла бы быть полезность построенной модели в нашем примере? Возможно, с ее помощью мы могли бы оптимизировать доставку кофе в офис. При этом нам нужно оценить риски и определить, лучше ли наша модель справлялась бы с этим, чем существующее решение – офис-менеджер Михаил, ответственный за закупку продукта.
Найдем исключения
Конечно, наш пример максимально упрощен. В реальности можно было бы построить более сложную модель, которая учитывала бы какие-то другие факторы, например, любит ли человек кофе в принципе. Или модель могла бы находить более сложные, чем представляемые прямой линией, взаимосвязи.
Можно было бы сперва найти в наших данных выбросы – объекты, которые, как Полина, сильно непохожи на большинство других. Дело в том, что при реальной работе такие примеры могут плохо повлиять на процесс построения модели и ее качество, и их имеет смысл обрабатывать как-то иначе. А иногда такие объекты представляют первостепенный интерес, например, в задаче обнаружения аномальных банковских транзакций с целью предотвращения мошенничества.
Кроме того, Полина демонстрирует нам еще одну важную идею – несовершенство алгоритмов машинного обучения. Наша модель прогнозирует всего 100 мл кофе для человека, который спал 10 часов, в то время как на самом деле Полина выпила аж целых 500. В это никогда не поверят заказчики data science-решений, но пока еще невозможно научить машину идеально предсказывать все на свете: как бы хорошо мы ни выделяли закономерности в данных, всегда найдутся непредсказуемые элементы.
Продолжим рассказ
Итак, data science – это набор методов обработки и анализа данных и применение их к практическим задачам. При этом надо понимать, что у каждого специалиста свой взгляд на эту сферу и мнения могут отличаться.
В основе data science лежат достаточно простые идеи, однако на практике часто обнаруживается много неочевидных тонкостей. Как data science окружает нас в повседневной жизни, какие существуют методы анализа данных, из кого состоит команда data science и какие сложности могут возникнуть в процессе исследования – об этом мы расскажем в следующих статьях.
Материалы по теме:
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Искусственный интеллект Компании научились собирать данные. Принимать решения — нет: почему цифры не помогают сами по себе 21 июля 2026, 16:04

-
Искусственный интеллект Нам не нужен свой OpenAI: где России искать эффект от ИИ и что для этого делать 19 мая 2026, 11:00

-
Искусственный интеллект Цифровизация начинается не с ИИ: эксперты рынка — о том, почему для трансформации бизнеса нужно изменить мышление 03 июля 2026, 11:58

-
Игры От нишевой RPG до глобальной франшизы: история Fallout пережила крах создателей и гнев фанатов 21 июля 2026, 20:30

-
Игры Миллиарды долларов на чужих играх: история Valve 21 июля 2026, 11:48

-
Игры Как техническая ошибка превратилась в бизнес на миллиарды: история GTA 20 июля 2026, 15:35

-
Бизнес Как поисковая строка превратилась в бизнес на $400 млрд: история Google 18 июля 2026, 18:00









-
Бизнес Nvidia раскрыла свою долю в Nebius Аркадия Воложа — производителю чипов принадлежит почти 10% компании 21 июля 2026, 20:30

-
Реклама Рекламная сеть Яндекса выплатила блогерам 5,3 млрд ₽ за три года — партнёрами стали 24 тыс. авторов 22 июля 2026, 11:00

-
Автомобили Jeland вошёл в топ-10 самых продаваемых марок на авторынке России — спустя всего год после запуска бренда 21 июля 2026, 18:30

-
Банки «Экономика просит снижения, но цены не разрешают»: эксперты оценили вероятность снижения ключевой ставки 24 июля 21 июля 2026, 22:00

-
Автомобили В России начали продавать праворульный кроссовер Subaru Rex — по цене от 1,08 млн ₽ 21 июля 2026, 21:00

-
Технологии Apple готовит iPhone 20 Pro Max размером с планшет — юбилейная модель выйдет в 2027 году 21 июля 2026, 18:00

-
Россия Хостинг-провайдеры просят сохранить отдельный способ верификации для иностранных клиентов — через банковский платеж 20 июля 2026, 21:00

-
Бизнес Авиакомпании Red Wings и SkyGates объединят в единый холдинг — Ростех начал упорядочивать свои активы 20 июля 2026, 14:38








