Разработка решений data science: плюсы, минусы и основные трудности
Что нужно знать бизнесу
Никита Никитинский, глава R&D в IRELA, и Полина Казакова, Data Scientist, продолжают рассказывать о машинном обучении и технологиях data science. В первом материале они объяснили, что такое data science, во втором — как машинное обучение применяется на практике. Сегодня они расскажут о стандартной методологии развертывания проектов в сфере data science и укажут на возможные проблемы, важные нюансы и узкие места.
Привет! В предыдущих статьях мы продемонстрировали, что методы data science могут быть полезны в самых разных прикладных задачах. Однако сами методы — лишь верхушка айсберга. Сейчас мы попробуем показать, как проходит процесс разработки data science-решения и почему чаще всего это происходит не идеально.
Условный стандарт
В чем заключается основная проблема data science-проектов? В отличие от «традиционной» разработки, универсальная методология их ведения еще не до конца сформировалась.
Одна из самых известных методологий такого рода называется CRISP-DM (Cross-Industry Standard Process for Data Mining, межотраслевой стандарт анализа данных). Она уже кажется несколько устаревшей, однако новые методологии, появившиеся в последние несколько лет, пока не стали столь же популярными. CRISP-DM делит процесс DS-разработки на шесть составляющих: понимание задачи, понимание данных, подготовка данных, построение модели, оценка и деплой (или развертывание) системы. Методология предусматривает почти свободный возврат к предыдущим этапам или их подпунктам.
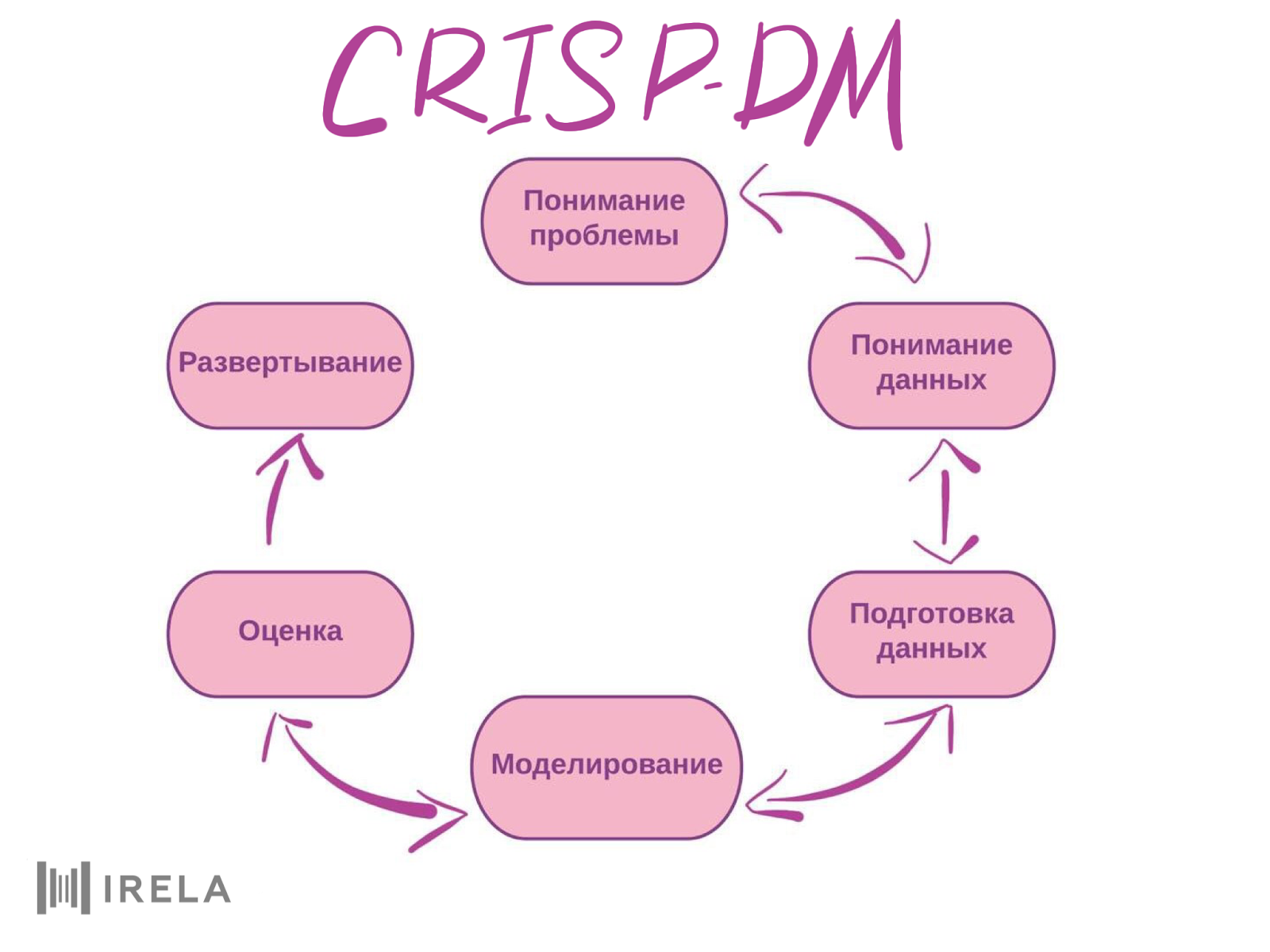
Давайте коротко рассмотрим, что включает в себя каждый блок, а также какие опасности подстерегают нас на каждом шаге.
- Понимание задачи
В первую очередь необходимо определиться с целью проекта. Причем самое важное — установить максимально строгие критерии достижения этой цели: как вы поймете, что проект принесет пользу вашей организации, какими бизнес-метриками можно эту пользу измерить.
Проектирование, разработка и внедрение DS-решений — это дорогое удовольствие. Поэтому еще до начала проекта стоит оценить, способно ли вложение окупиться. Необходимо также взвесить, а нужно ли вам вообще все это машинное обучение и прочий датасаенс. Машинное обучение хорошо подходит для автоматизации конвейерных, рутинных процессов, которые при этом ведут к накоплению значительного количества данных.
К примеру, большие компании часто вынуждены содержать большой штат службы поддержки, обрабатывающей внешние заявки. Расходы на оплату труда можно значительно сократить, если поручить это дело алгоритмам. Если у вас разовая или нерегулярная задача, скорее всего, дешевле будет обойтись без автоматизации.
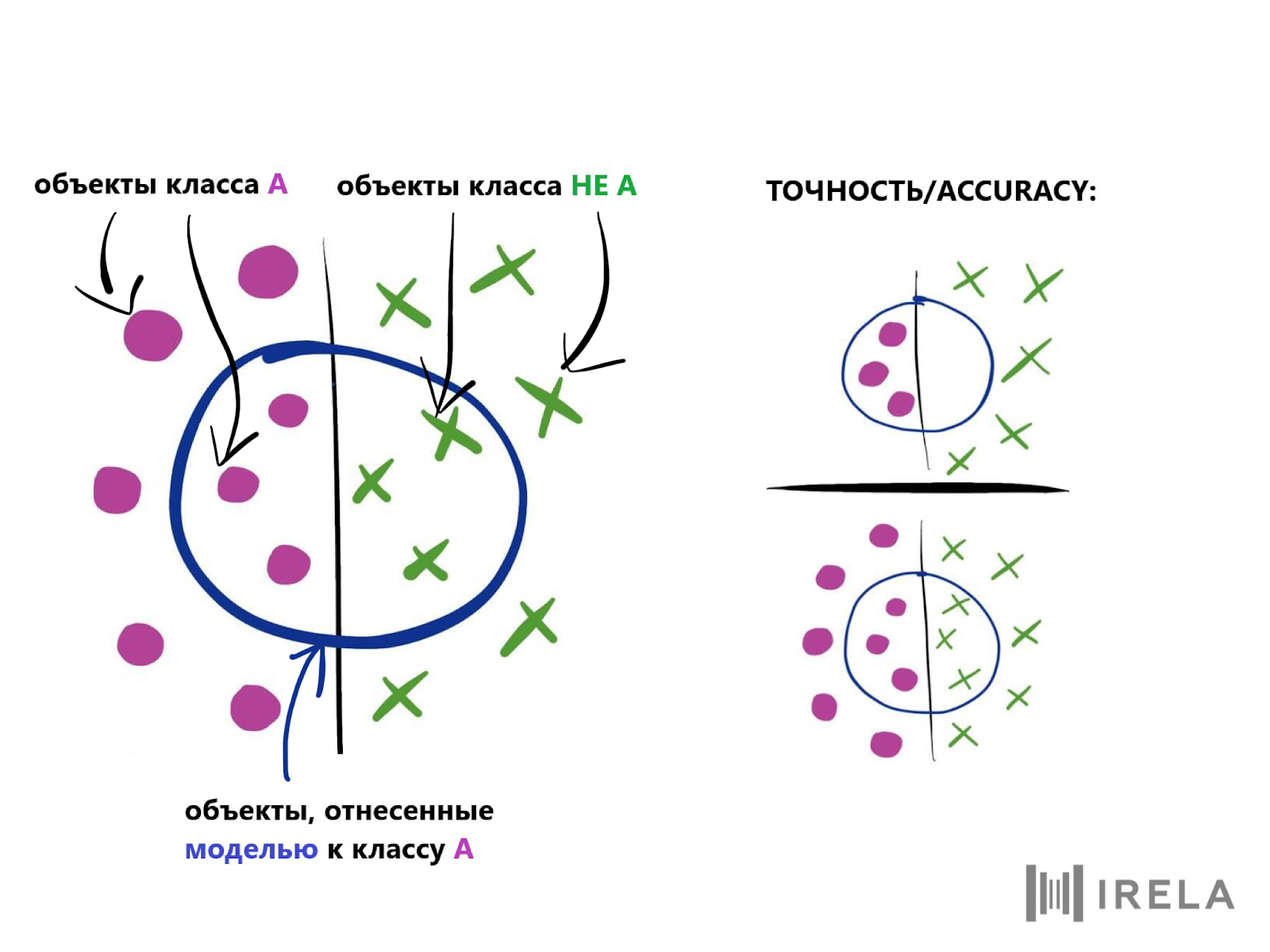
После того, как бизнес-задача поставлена, необходимо сформулировать ее в виде формальной задачи анализа данных и снова определить метрики оценки качества, на этот раз математически. Например, при классификации такой метрикой может быть точность (accuracy): доля объектов, которые модель угадывает правильно. Определитесь, какого минимального формального значения метрики качества должна достичь модель, чтобы обеспечить выполнение поставленной бизнес-цели.
На этом этапе также набрасывается первоначальный план проекта и выбирается предварительный набор инструментов анализа данных. Желательно сразу оценить ваши возможности и ограничения: нужна ли вам сложная модель, требующая большого количества ресурсов и денежных вложений (например, нейросетевая), или, возможно, будет достаточно простого, но надежного традиционного алгоритма?
Учитывайте, что вероятность непонимания между заказчиком и исполнителем в проектах data science выше, чем при разработке традиционных систем, — в силу того, что заказчики чаще всего имеют довольно слабое представление о возможностях и ограничениях DS-методов. Поэтому по ходу проекта необходимо регулярно давать друг другу обратную связь, при этом важна способность специалистов со стороны исполнителя популярно объяснять сложные вещи. Понимание задачи — важный этап, в большой степени определяющий успех проекта.
- Понимание данных
На следующем шаге исполнитель получает данные и подробно их анализирует. Можно строить модели и без понимания того, с какими данными приходится иметь дело, но тогда они становятся «черным ящиком» не только для заказчика, но и для самих аналитиков и разработчиков — это не жизнеспособно. На практике очень важно знать природу и устройство данных и то, какие закономерности они обнаруживают. Это позволяет не только корректно сформировать признаки, но и лучше понять, как работает модель, почему она может давать верный ответ в одном случае и ошибаться в другом.
Главная проблема этого этапа заключается в том, что в данных компаний чаще всего встречаются ошибки, и когда их доля во всей выборке существенная, это может стать серьезной помехой. Например, вы разрабатываете систему автоматического ответа на заявки пользователей в службу поддержки. Модель обучается на текстах ответов реальных операторов этой службы. Очевидно, здесь срабатывает человеческий фактор: все люди ошибаются, а иногда еще и халтурят. Если специальным образом не подойти к решению этой проблемы, то на этапе построения модели может случиться затык, когда не удастся никакими способами достичь желаемого качества.
Есть несколько возможных способов с этим справиться.
- Первый (и самый надежный): посадить специалистов со стороны заказчика заново размечать данные, то есть проставлять ответы. Минусов у такого подхода два. Это дорого, потому что сотрудники отвлекаются от основных обязанностей, и долго, ведь данные, которые копились годами, не разметить за один день, и хотя нередко бывает достаточно обработать лишь их часть, все равно это очень большой объем.
- Второй способ: посадить размечать внешних людей или самих аналитиков. Проблемы все те же, плюс к ним добавляется то, что качество разметки ухудшается — из-за отсутствия у людей вне компании специальных знаний, даже при наличии детальных инструкций.
- Третий вариант: использовать алгоритмы машинного обучения (помните, мы уже обсуждали поиск аномалий?). Однако этот вариант подходит только для ситуации, когда ошибок в данных не слишком много, ведь если ошибок будет большинство, алгоритм просто выкинет все правильные случаи и станет только хуже.
Еще может так случиться, что заказчик вообще даст неправильные данные (у нас такое бывало). Это еще одна причина, по которой данные нужно исследовать очень внимательно. И вероятнее всего, это звоночек, символизирующий, что заказчик и исполнитель не поняли друг друга и необходимо вернуться к первому этапу.
Наконец, у заказчика может вообще не быть никаких данных, — и делайте, как хотите. А ведь именно качество и количество данных определяет успех алгоритмов машинного обучения. Поэтому в последнее время говорят о важности аналитической культуры, подразумевающей особое отношение компаний к своим данным как к ресурсу, который необходимо накапливать и структурировать. У DS-проектов в таких компаниях шансы на успех значительно повышаются.
- Подготовка данных
Этот этап включает в себя формирование нужных выборок, очистку данных от ненужной информации, приведение их к необходимому формату и конструирование признаков.
Небольшая сложность, которая может возникнуть на этом шаге, кроется в слиянии и агрегировании данных из нескольких источников, если заказчик хранит информацию в разных базах данных (а так бывает почти всегда).
- Моделирование
Процесс моделирования происходит примерно так. Сначала выбирается потенциально подходящий алгоритм или чаще всего набор алгоритмов. Затем определяется метод оценки качества модели. Например, для классификации самый простой способ — измерение какой-либо метрики качества (например, точности) на тестовой выборке.
Тестовая выборка — это отдельная часть данных, на которой НЕ обучался алгоритм, то есть та часть, которую алгоритм «видит» впервые. Проверка на тестовой выборке не всегда возможна, как, к примеру, при кластеризации, когда правильных ответов просто нет. После проводится само обучение моделей и их настройка, то есть подбор таких параметров, которые дают самое высокое возможное качество или близкое к нему. Наконец, из всего пула моделей выбираются наилучшие.
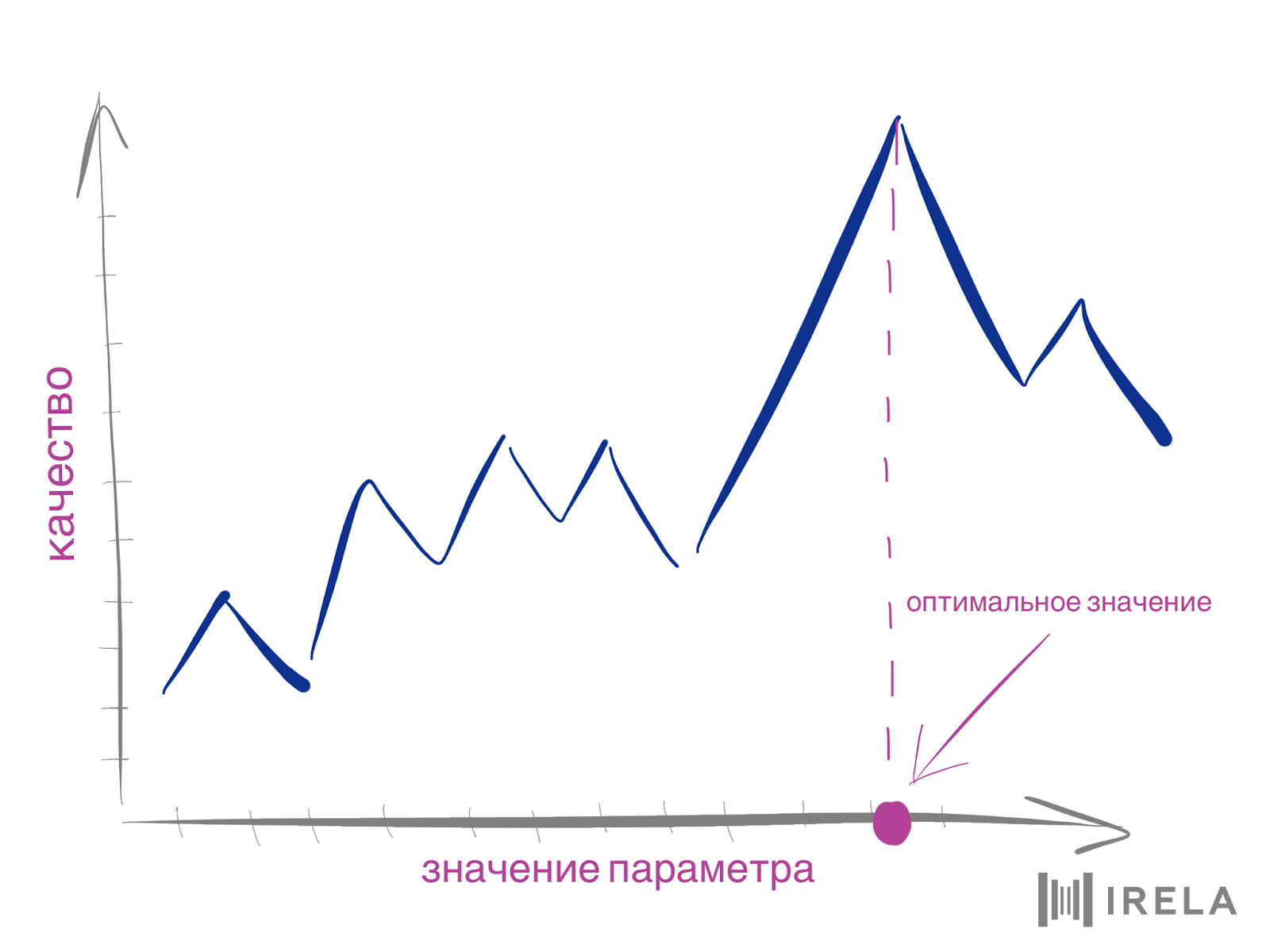
Провал, поджидающий на данном шаге, возможно, самый болезненный для исследователя, потому что в этот момент теория встречается с реальностью. Модель, которая первоначально казалась идеальной для вашего кейса, может на практике показать возмутительно низкие результаты. Оказывается, цитируемые научные статьи от признанных светил машинного обучения, где их модели бьют все рекорды на полуискусственных данных, — не гарантия успеха. Вот совет для минимизации таких рисков: всегда (!) начинайте с простых, проверенных временем техник и переходите к более сложным по мере необходимости.
- Оценка
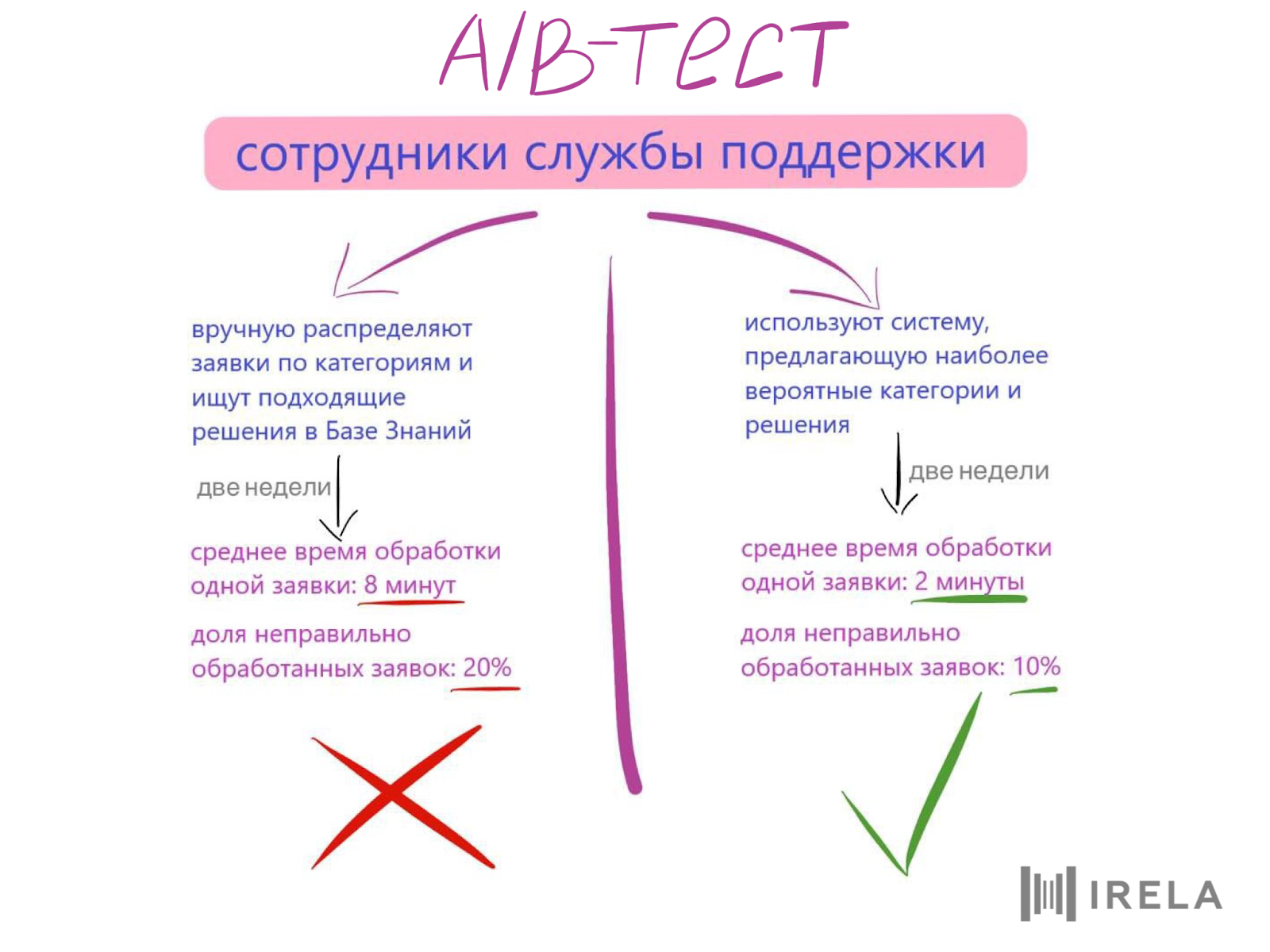
Перед тем, как пускать модель в бой, необходимо удостовериться, что она действительно эффективна в поставленной бизнес-задаче. Для этого часто используют метод A/B-тестирования: потенциальные пользователи системы (или их часть) делятся на две группы — одной дается новый инструмент, в другой все остается, как было.
Например, одна половина службы поддержки продолжает обрабатывать заявки вручную, другая — пользуется прототипом, предлагающим значения нужных полей. Через некоторое время для обеих групп измеряются бизнес-метрики (например, среднее время обработки одной заявки) и делается вывод.
Иногда разделение на две группы не подходит, и тогда можно показывать обе версии одному и тому же пользователю. Например, вы разрабатываете новую поисковую модель на замену существующей. Можно показывать оба результата выдачи пользователю и спрашивать, какой из них, на его взгляд, лучше.
Заказчик может захотеть пренебречь этим этапом, так как он стоит дополнительных денег, времени и усилий, ведь нужно все-таки создать минимально функционирующий прототип. Однако лучше потратиться на прототипирование и тестирование, чем в итоге заплатить еще больше денег за систему, которая бесполезна в достижении установленных целей.
- Развертывание
Процесс написания финального кода, построения итоговой модели и дальнейшего развертывания DS-решений в чем-то схож с обычной разработкой, но имеет дополнительные сложности.
В частности, необходимо прописывать не только стандартные тесты, проверяющие, что система в принципе функционирует, но и тесты для проверки адекватности финальной модели, которые не всегда можно реализовать стандартным способом.
Можно сравнивать значение метрики качества на тестовой выборке со значением, полученным на этапе моделирования. Если ситуация такова, что тестовой выборки нет, придется придумывать что-то специфическое в каждом конкретном случае.
Например, если вы разрабатываете поисковую систему и тестовой выборки у вас нет, можно проверить, находит ли модель в ответ на запрос «как поймать единорога» страницы, содержащие слово «единорог». Это нужно для того, чтобы если по каким-то причинам итоговая модель построилась неправильно, вы узнали об этом раньше, чем она начнет выдавать некорректные ответы пользователям или сломает всю систему.
Тестирование важно не столько чтобы проверить, что на первой итерации все работает как надо (в этом можно и глазами убедиться), но в первую очередь чтобы упростить дальнейший процесс поддержки и развития.
За рамками методологии
Описанная методология — самоочевидная, слишком верхнеуровневая, не описывает, как распределяются процессы по ролям в команде, и необоснованно разделяет этапы исследования данных и их подготовки, хотя на практике это скорее один процесс. Но основная наша претензия к ней заключается в том, что она не учитывает этапа поддержки, в то время как именно этот процесс доставляет серьезную головную боль как исполнителям, так и заказчикам. Трудности проистекают из того, что реальность постоянно меняется, и необходимо, чтобы модель подстраивалась под эти изменения. С добавлением новых данных может измениться структура признаков, могут добавиться новые признаки или новые значения зависимой переменной.
У этой проблемы нет универсального решения. Можно периодически переобучать модель, но и это ведет к некоторым сложностям. К примеру, новая модель может на старых объектах давать ответы, отличные от ответов предыдущей модели.
Помимо поддержки, после развертывания желательно продолжать мониторить полезность системы: проводить A/B-тесты, собирать отклики пользователей.
Если вы дочитали до этого абзаца, то у вас, вероятно, сформировалось ощущение, что лучше вообще не браться за эти новомодные технологии. Мы считаем, что это не так :) Наука о данных не была бы так популярна, если бы не позволяла справляться со многими проблемами более эффективно. Однако помните, что анализ данных в бизнесе — это не только модели, эксперименты и проверка гипотез. Безусловно, само моделирование очень и очень важно. Но в отрыве от всех остальных блоков при решении прикладных задач оно может оказаться бессмысленным.
Материалы по теме:
Как мы научились с математической точностью отслеживать зарождающиеся тренды
Breaking ad: как мы учили нейросеть разбираться в наркотиках
Как мы создали антифрод-систему для защиты бизнеса и его клиентов от мошенников в интернете
Как повысить продажи в три раза с помощью Big Data и машинного обучения?
Фото на обложке: Unsplash
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Искусственный интеллект Компании научились собирать данные. Принимать решения — нет: почему цифры не помогают сами по себе 21 июля 2026, 16:04

-
Игры От нишевой RPG до глобальной франшизы: история Fallout пережила крах создателей и гнев фанатов 21 июля 2026, 20:30

-
Игры Миллиарды долларов на чужих играх: история Valve 21 июля 2026, 11:48

-
Игры Как техническая ошибка превратилась в бизнес на миллиарды: история GTA 20 июля 2026, 15:35

-
Бизнес Как поисковая строка превратилась в бизнес на $400 млрд: история Google 18 июля 2026, 18:00

-
Искусственный интеллект Нам не нужен свой OpenAI: где России искать эффект от ИИ и что для этого делать 19 мая 2026, 11:00

-
Бизнес «Команде не вырасти выше лидера»: как изменить неписаные правила взаимодействия в группе 19 мая 2026, 10:00









-
Бизнес Nvidia раскрыла свою долю в Nebius Аркадия Воложа — производителю чипов принадлежит почти 10% компании 21 июля 2026, 20:30

-
Бизнес Иностранных инвесторов могут лишить права на обратный выкуп бизнеса в РФ — их опционы можно отменить через суд 21 июля 2026, 20:00

-
Автомобили Jeland вошёл в топ-10 самых продаваемых марок на авторынке России — спустя всего год после запуска бренда 21 июля 2026, 18:30

-
Банки «Экономика просит снижения, но цены не разрешают»: эксперты оценили вероятность снижения ключевой ставки 24 июля 21 июля 2026, 22:00

-
Автомобили В России начали продавать праворульный кроссовер Subaru Rex — по цене от 1,08 млн ₽ 21 июля 2026, 21:00

-
Технологии Apple готовит iPhone 20 Pro Max размером с планшет — юбилейная модель выйдет в 2027 году 21 июля 2026, 18:00

-
Россия Хостинг-провайдеры просят сохранить отдельный способ верификации для иностранных клиентов — через банковский платеж 20 июля 2026, 21:00

-
Бизнес Авиакомпании Red Wings и SkyGates объединят в единый холдинг — Ростех начал упорядочивать свои активы 20 июля 2026, 14:38








