
CEO стартапа NativeOS Виталий Сотников рассказал о том, как работают алгоритмы создания нативной видеорекламы и как его команда обучала нейросеть различать контент, с которым не захочет размещаться порядочный рекламодатель.
За приключениями NativeOS можно следить в их Telegram-канале и в нашей серии статей.
Рецепт идеального brand safety
Если вы читали наши предыдущие статьи и/или знакомы с деятельностью NativeOS, то уже в курсе нашего подхода к автоматизированному созданию по-настоящему нативной рекламы — Real Native Ads.
Суть в следующем: мы используем компьютерное зрение для анализа объектов внутри контента (например, видео, картинки или текста статьи) и, используя разработанные наборы формул и алгоритмов, выводим степень схожести между креативом и контентом.
Если же контент не отвечает требованиям безопасности для рекламируемого бренда, то реклама в контенте никогда не появится. На лепестках нашего brand safety-цветка вы можете увидеть все небезопасные категории для размещения рекламы. Поэтому, получив зеленый свет от нашего ИИ, бренд может быть спокоен относительно своего размещения, выбрав категории контента, где он размещаться не желает.
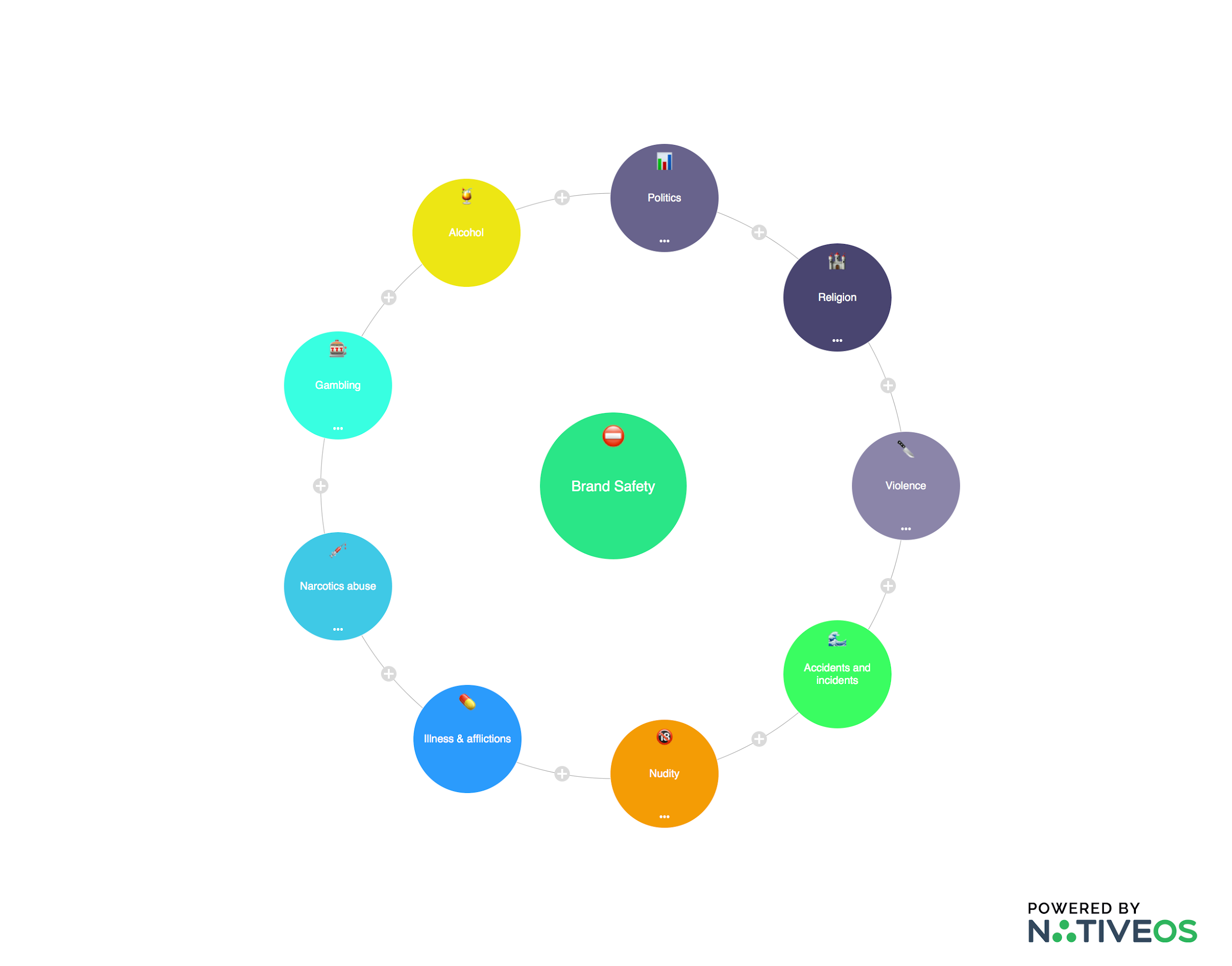
Внутри каждой из категорий находится около 200-300 объектов, которые позволяют нейросетям идентифицировать контент с низким уровнем brand safety.
Подобным образом мы легко создаем связи, обеспечивая наибольшую релевантность, не разрывая нарратив и учитывая контекстуальность. Например, в фильме в сценах драк можем показать рекламу мази от ушибов, так как категория «драка» является семантической частью Violence («насилие» — прим. ред.) — одной из выведенной нами веток brand safety.

И все бы хорошо, и логично, но год назад мы вместе с командой разработчиков NativeOS обратили внимание на невероятное количество медиаскандалов, связанных с небезопасным размещением рекламы, следствием которых стало как сворачивание рекламных бюджетов, так и уход рекламодателей с площадок.
Только за первый квартал 2018 года, например, Facebook удалил миллионы постов с «неблагоприятным» контентом:
- 3,5 млн постов с контентом о насилии.
- 21 млн постов с контентом ХХХ.
Или чего только стоит высказывание представителя компании Google о невозможности обеспечения 100% brand safety на YouTube!
А учитывая контекст повышения стоимости размещения рекламы на YouTube, наш ИИ выглядит совсем уж недорогим решением существующей проблемы brand safety.

Дистрибутивная семантика как средство против наркотрафика
Получив первого клиента (прим. вследствие NDA пока мы не можем разглашать название данного бренда, но можем сказать, что это один из крупнейших рекламодателей России), одной из наших первых категорий работы стали «наркотики». Таким образом мы и стали негласными борцами с наркотрафиком.
В первую очередь мы выделили основные подкатегории, с которыми придется иметь дело нашему свежесозданному digital-отделу по борьбе с наркотиками.
Не найдя готовых решений через поисковики, мы с головой ушли в семантический трип, выйдя из которого выявили следующий список категорий:
- «Клубные» наркотики (MDMA, GHB и так далее).
- Стимуляторы (амфетамин, мет, кокаин).
- Опиоиды (опиум, героин).
- Каннабиноиды (гашиш и марихуана).
- Анаболики (анадрол, дураболин и так далее).
- Галлюциногены (ЛСД, мескалин, псилоцибин).
- Диссоциативные (кетамин, сальвия и так далее).
- Наркокартели и известные личности (Los Zetas, «Тамплиеры», Пабло Эскобар и так далее).
Мы привели лишь часть примеров из нашей семантической основы, внутри каждой из которой также присутствует огромное количество взаимосвязей, включая сорта, разновидности, форм-фактор (куст, порошок), прозвища («Марьиванна»), культурный контекст («Раста») и даже связи из нескольких объектов: «ложка + зажигалка», «жгут+шприц» и так далее.

Классы наркотиков категории Narcotics Abuse
Также мы выяснили, что существуют довольно тесные ассоциативные связи между кокаином и известными людьми, которые в какой-то момент решили «вдохнуть на дорожку» собственного успеха: Диего Марадона, Чарли Шин или Гордон Рамзи. На скриншоте ниже можно увидеть наиболее релевантные с точки зрения контекста связи по запросам пользователей в поисковике.
У гугла есть свой расчет индекса цитируемости и релевантности по пересечению контента, поэтому высокий шанс прямого контекстуального мэтча будет иметь метку «сверхпопулярность». Поэтому Кэтрин Зета-Джонс в глазах нашего отдела чиста.
Вот, что выдает Google Trends при вводе «cocaine».
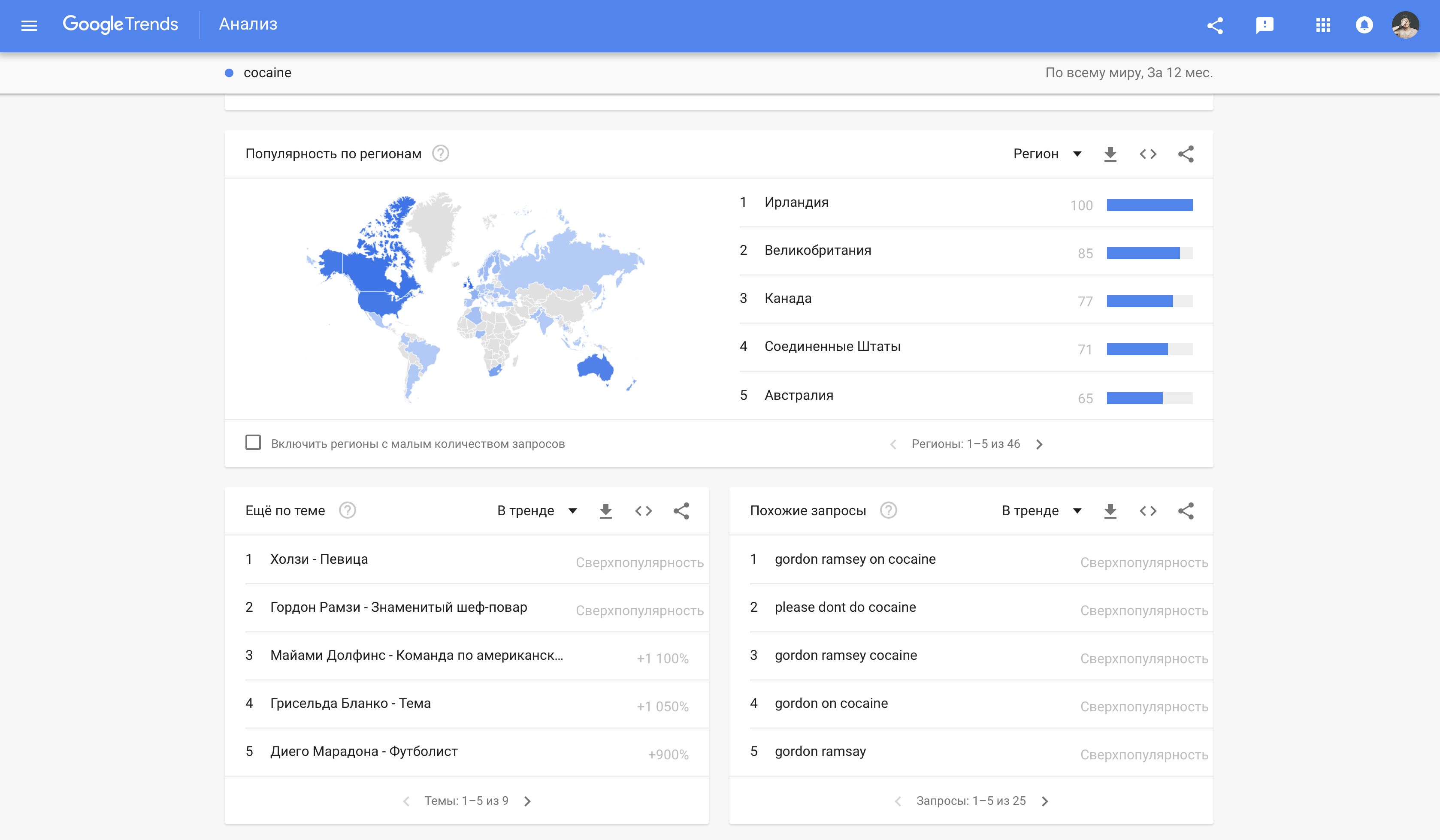
Фактически недостаточно смотреть на ситуацию brand safety лишь исключительно с точки зрения объектов. Не менее важно учитывать текущие тренды, контекстуальность которых позволит прийти к ещё более точным результатам распознавания, например, в новостном контенте.
Breaking ad
И вот, собрав таким образом семантический набор связей, начинается отходняк или самое интересное: скрупулезная проверка всех семантических структур будущего товара нашими датасаентистами.
На этом этапе мы отсеиваем часть объектов, взяв в расчет отношение между низкой популярностью и высокой сложностью распознавания.
Например, Декстрометорфан (DXM — сироп от кашля, входящий в список наркотических веществ) мы исключили из финального списка по причине того, что получим крайне высокую вероятность находить наркотики там, где их нет, так как DXM поставляется в таких же флаконах, как и многие разрешенные препараты.

Затем получившийся список мы отдаем нашим датамайнерам, которые уже исследуют безграничные просторы интернета, собирая датасеты по заданным параметрам и критериям.
На каждый объект нам требуется от 1000 до 5000 картинок — цифры зависят от количества заданных критериев и возможных состояний объекта.
Учитывая, что готовых решений для наших задач не существует (мы проверяли!), то первым делом мы собираем данные из открытых источников: это поисковые системы Google, Yandex & Bing. Специально для этого мы написали парсер, позволяющий грэббить картинки по запросам (ссылка на него в конце статьи). Стоит учесть, что Google, в отличие от остальных поисковиков, не позволяет вытянуть больше, чем первую сотню пикч по запросу.
Здесь-то нам на помощь и приходит синонимизация, другими словами — прозвища и сокращения названий. Учитывая поиск на двух языках, этот способ помогает нам дополнительно найти еще несколько сотен картинок.
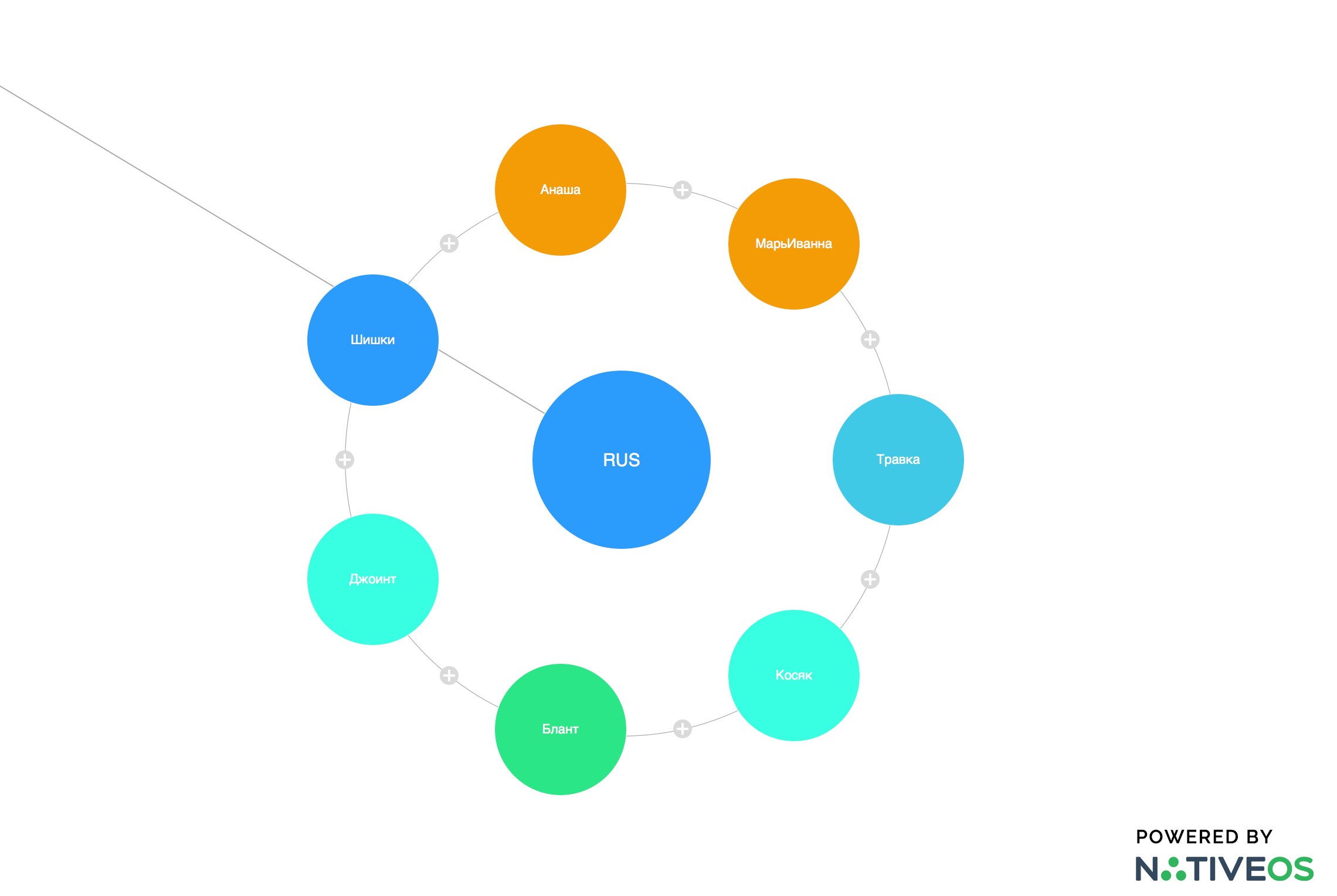
Судя по подобным скриншотам сложно сказать, что это вообще работа. Русские прозвища марихуаны.
Возможно, следующее заявление покажется чересчур громким, но думаю, мы единственный стартап, официально заявляющий, что пользуется даркнетом для поиска наркотиков. Точнее, их фотографий. Ведь нет лучшего места для сбора нарко-датасетов, чем темная сторона интернета.
Дополнительно стоит отметить ценность подобных ресурсов не только в качестве датабанка, но и также для формирования знаний. Телеграм-каналы, посвященные этой теме, содержат не только мануалы по использованию, но и достаточно серьезные исследования и целые лонгриды, посвященные отдельным темам: от проблем восприятия наркотиков в мире вплоть до рассказа про один из самых могущественных наркокартелей в мире — Los Zetas. Узнав, что у данного картеля существует логотип и целый брендбук, мы, разумеется, добавили его в датасет.
Следующим шагом мы начинаем разметку датасетов.
Наш выбор пал в пользу bounding box, а не object detection, так как он быстрее и проще, а учитывая контекст стоящей перед нами задачи, нам не требуется молекулярная точность распознавания, как, например, в случае, если бы нам требовалось идентифицировать раковые клетки крови, которые не имеют идентичного форм-фактора и находятся в постоянном контакте с объектами похожей формы.
Разницу между методами разметки вы можете увидеть на примере Чарли Шина. На первый взгляд, разница незаметна, так как выделение одного объекта не занимает много времени при использовании обоих методов, но когда речь идет об объемах в несколько миллионов картинок только лишь на одну из категорий brand safety, то экономия и времени, и ресурсов достаточно сильно заметна.
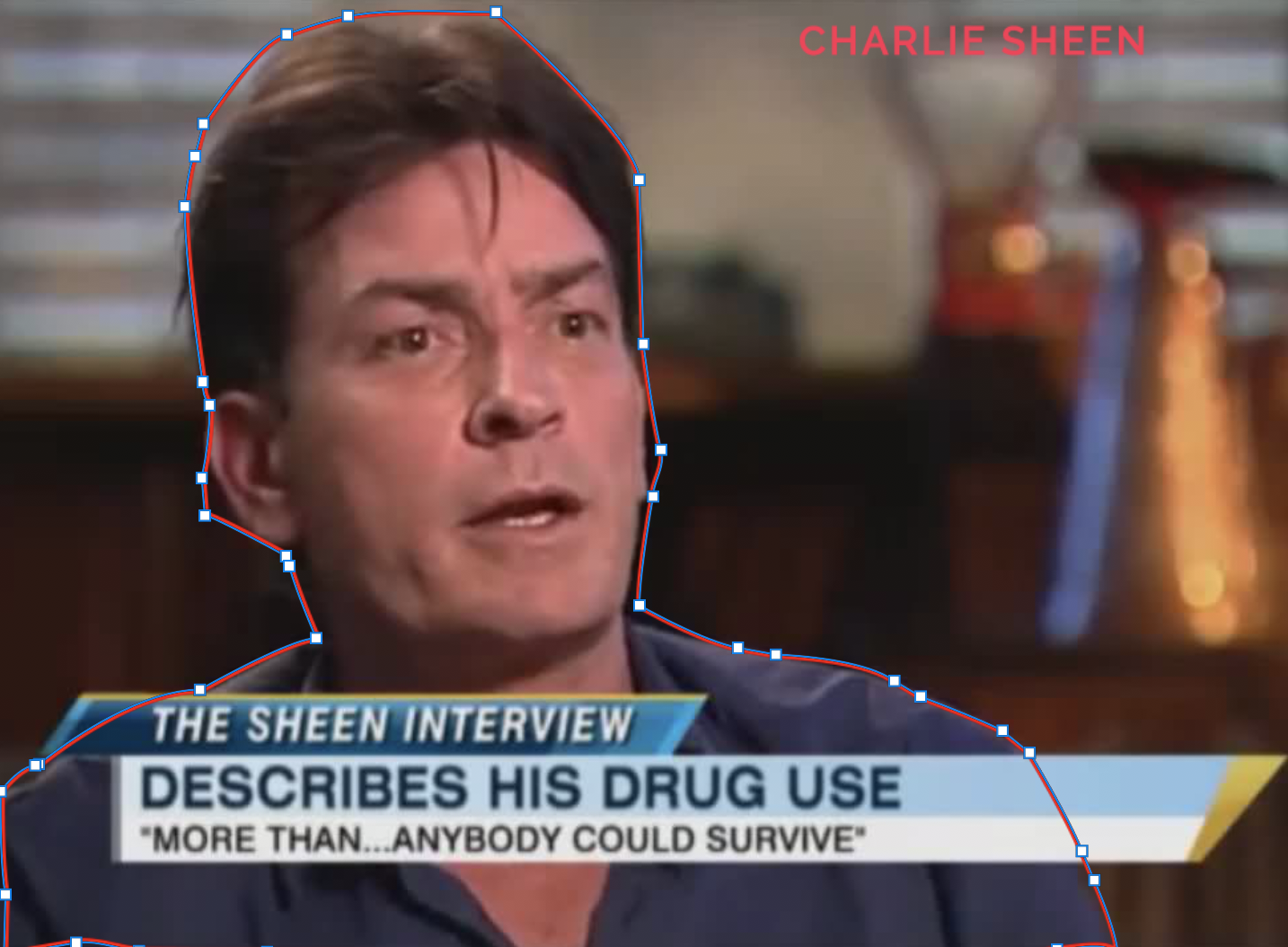
Далее подготовленные датасеты вновь возвращаются в наш департамент Data Science, где и происходят магические процессы обучения и дообучения наших сетей.
В этой статье мы рассказали об одной из наиболее простых категорий, так как, например, в категориях religion или violence существует заметно большее количество высокоабстрактных подкатегорий контекстуальных взаимосвязей.
Материалы по теме:
«Я вечером хочу спать и тупить, но уже привык». Как NativeOS работает в четырех часовых поясах
Уже не black box. Новые возможности в машинном обучении (и как бизнесу их использовать)
Как мы научили нейронку распознавать пол и возраст
Петербургский стартап разработал «счётчик Гейгера» для нативной рекламы
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Материалы по теме
- 1 AI для HR: профиль кандидата, который повысит скорость найма в два раза
- 2 Эволюция ML-сервисов в микрофинансовых организациях и советы по внедрению
- 3 Машины не восстанут, но вылететь с работы можно: разбираемся, зачем осваивать нейросети
- 4 Мнение эксперта: Игорь Пивоваров о том, что происходит с OpenAI
- 5 «Доверять нельзя бояться». Как работают нейросети в беспилотных автомобилях
ВОЗМОЖНОСТИ
23 апреля 2024
23 апреля 2024