Как работает современный Data Scientist. Почему 80% работы улетает в корзину?
Как от «колхозных» решений перейти к промышленному подходу
AI Community в рамках проекта AI Heroes регулярно проводит вебинары с ведущими экспертами в области Data Science.
18 февраля прошел вебинар с консультантом по работе с данными Алексеем Чернобрововым на тему «Можно ли перестать делать “колхозные решения” в Data Science?».
Алексей помогает бизнесу настроить аналитику, оптимизировать работу и повысить прибыль. Он учит топ-менеджеров понимать Data Science и Machine Learning, Data Scientist’ов — понимать бизнес, а Data-аналитиков — любить математику.
На вебинаре мы узнали, как работает Data Scientist, почему возникает «колхоз» и как перейти к промышленному подходу. Ниже делимся этой информацией с вами.
Смотреть все материалы серии
Как работает Data Scientist?
Работа специалиста по Data Science строится по общей схеме:
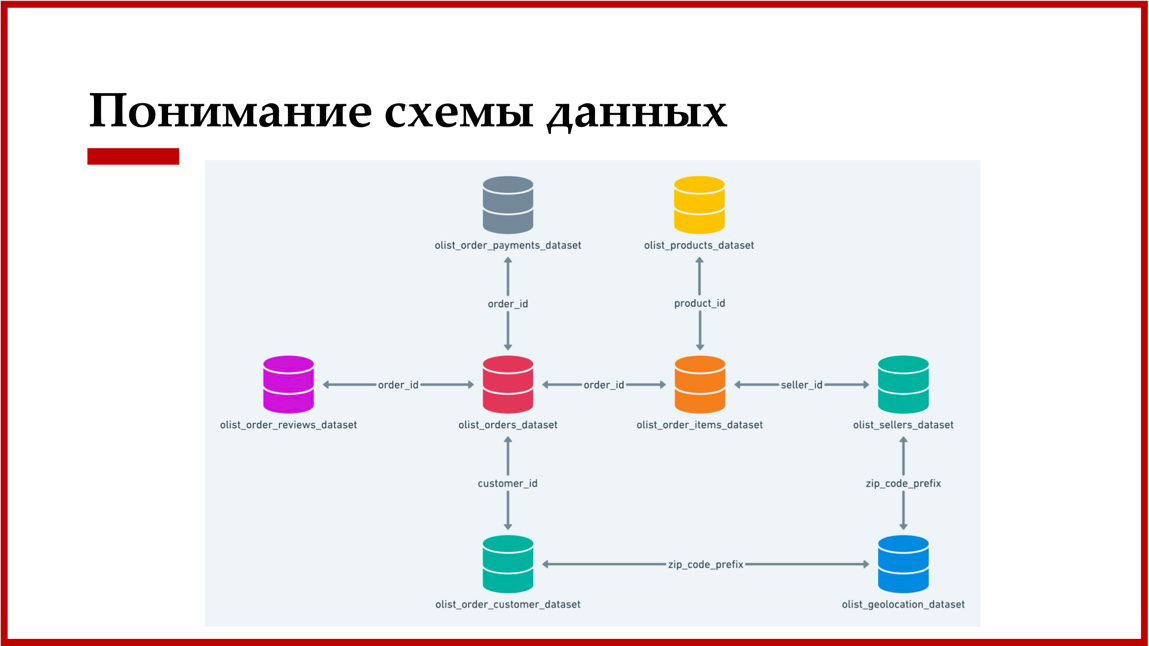
- Понимание задачи и данных (схемы данных).
- Визуальный анализ данных.
- Работа с данными.
- Выбор метрики (функции потерь).
- Применение разных алгоритмов.
- Валидация, интерпретация, продакшн.
Разберемся в этих пунктах более подробно.
Понимание задачи и данных
Работа начинается с понимания бизнес-задачи и построения схемы данных. Например, для прогнозирования роста продаж в сфере e-commerce — это таблицы с информацией о заказах, содержимом корзины, геопозиции продавцов и др. Необходимо собрать схему минимум из восьми таблиц.
Что было до Data Science?
До появления Data Science никто не готовил данные специально для работы. Данные готовили для собственных нужд, чтобы сервис и продукт работали быстрее, удобнее было хранить данные. Поэтому раскопать данные очень трудно — можно потратить на это месяц.
Визуальный анализ данных
Далее специалист строит зависимости и смотрит аномалии.
Какая проблема может возникнуть?
Data Scientist — не всегда профессионал в нужной предметной области и нише, несмотря на то, что разбирается в данных. Следовательно, он может тратить дополнительное время на понимание аномалий.
Работа с данными
Работа с данными — это четыре шага:
- Исправление пропусков в данных.
- Поиск аномалий (выбросов) в данных.
- Отбор признаков.
- Работа с дисбалансом классов.
Это масштабная работа, требующая интеллектуальных усилий и временны́х ресурсов.
Исправить пропуски в данных можно следующим образом:
- заполнить новым значением,
- заполнить средним значением,
- восстановить значение по остальным признакам.
Далее работаем с объектами с пропусками:
- исключаем из выборки,
- уменьшаем их вес в оценке,
- обучаем отдельные модели.
Аномалии выделяют по смыслу и по статистике. Поиск аномалий можно разделить на две составляющие: визуальная (смысловая) и алгоритмическая (по правилам).
Устраняем аномалии двумя путями: замена значений или удаление объектов.
Нюанс: выделить аномалию по смыслу возможно только при хорошем понимании предметной области.
В конечном итоге работа с данными сводится к работе с признаками (feature engineering).
Выбор метрики
Проводится выбор функции для максимизирования/минимизирования модели в зависимости от задачи.
После этого идет применение различных алгоритмов и валидация, интерпретация, продакшн.
Итого: 80% времени Data Scientist тратит на работу с данными!
Задачи Data Scientist’а
Перед таким специалистом стоят две задачи:
- писать быстро,
- писать хороший код.
Мир Data Science сейчас — это про ускорение. Культура стартапов: делай быстро, ошибайся быстро. Время специалиста стоит дорого.
В лучшем случае срабатывает каждая пятая гипотеза. В худшем — каждая двадцатая. Значит, минимум 80% времени тратится впустую.
Data Scientist параллельно сталкивается с большим числом одноразовых задач. Кроме того, состав команды непрерывно меняется. В среднем работа специалиста в одной компании составляет 2,5–4 года.
Как перейти к промышленному подходу
Промышленный подход — это переход к автоматизации процессов.
Шаги приближения к промышленному подходу:
- Continuous delivery & continuous integration — частые автоматизированные сборки проекта и частая доставка обновлений на «боевую» систему.
- Автотесты.
- Автопереобучение моделей.
- Быстрое подключение и использование новых источников данных.
- Подключение библиотек.
- Автовалидация.
- Автозапуск А/В-теста, если метрики просаживаются.
Масштабирование автоматизации процессов
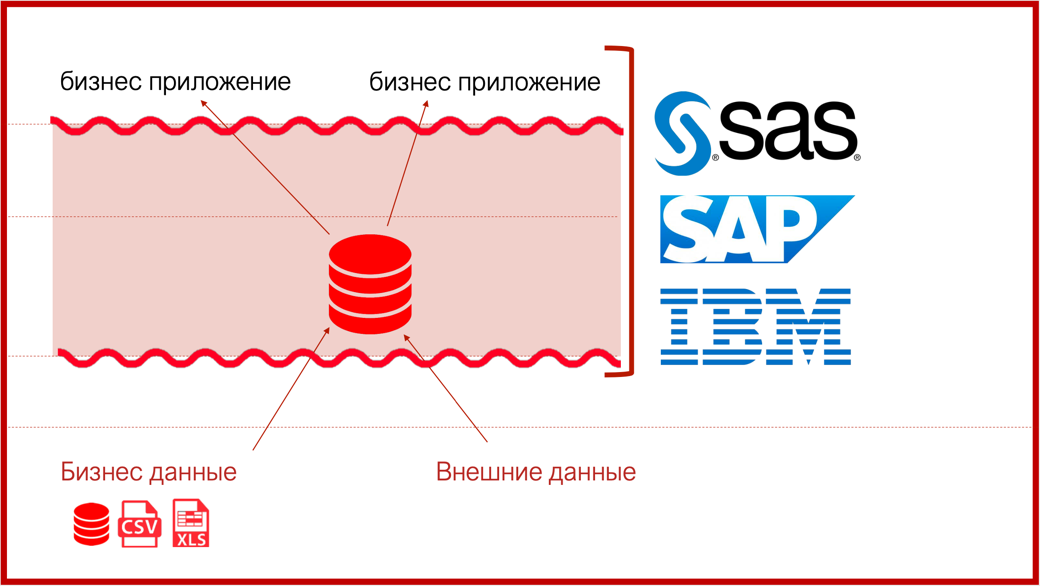
Использование enterprise-решений
Существуют готовые enterprise-решения от крупных компаний. Они работают с внешними источниками и обеспечивают транспортировку данных.
Например, SAP обеспечивает:
- автоматическую подготовку данных,
- прогнозное моделирование,
- анализ связей и ссылок,
- управление прогнозным моделированием,
- встраивание прогнозных сведений.
Промышленные решения уже представлены на рынке для вашего использования.
Использование SaaS
SaaS (Software as a Service) — сервисы, предоставляемые поставщиками облачных услуг и предназначенные для конечных пользователей. Например, Google, Amazon и др.
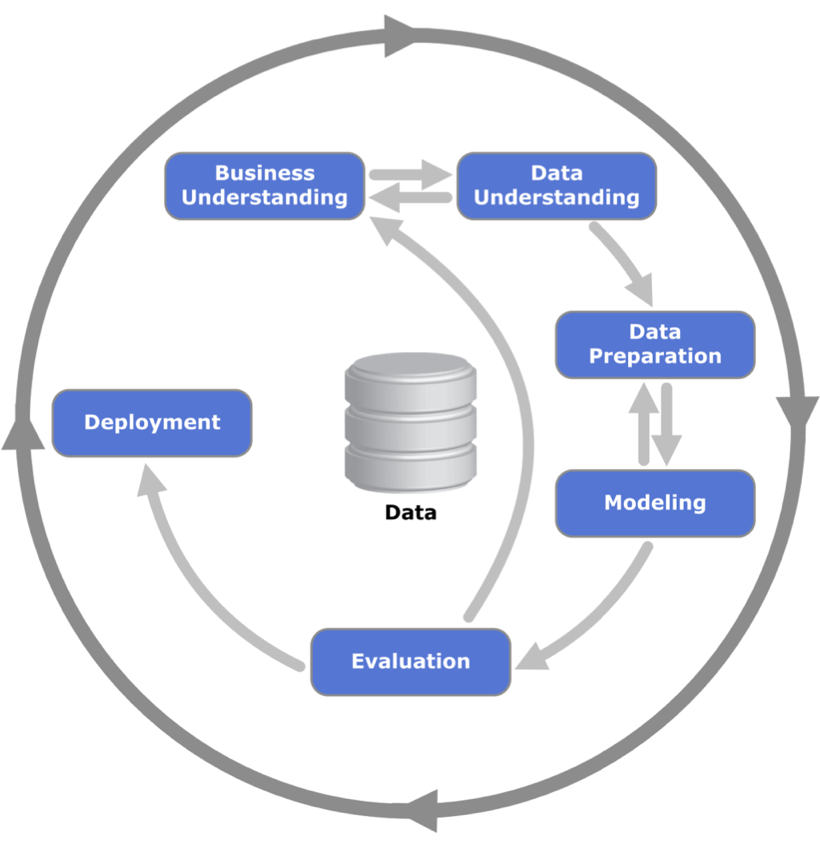
Создание CRISP DM
CRISP DM — межотраслевой стандартный процесс для исследования данных.
Чтобы Data Scientist’у решить задачу, следует:
- понять бизнес-цели,
- проанализировать данные,
- обработать данные,
- построить модель,
- протестировать на реальных данных,
- если приносит пользу — заниматься внедрением.
И так по кругу.
Почему предприниматели остаются на том же уровне?
Построить CRISP DM — долго и дорого. И не всегда целесообразно.
Вывод
- Естественный путь эволюции. Не стройте CRISP DM — делайте эволюционные шаги. Начните хотя бы с Git’а.
- Результаты важнее инструментов. Data Science стоит дорого. Важно не как он делает, а какой результат и пользу приносит бизнесу.
- Data Science находится на этапе, который PHP проходил 20 лет назад.
Как получить максимум?
- Помните: 80% времени Data Scientist тратит на работу с данными. В лучшем случае взлетает каждая пятая гипотеза, в худшем — двадцатая.
- Цените время DS. Оно стоит дорого. Если можно что-то поручить разработчику — поручите.
- Переход к промышленному подходу следует начать с Git’а. И далее по шагу добавлять автоматизацию следующих процессов.
Изображение на обложке: Shutterstock / whiteMocca
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
IT Как выстроить Data Science отдел в корпорации 18 февраля 2020, 11:57

-
Бизнес Разработка решений data science: плюсы, минусы и основные трудности 09 ноября 2018, 15:35

-
HR Кто такой дата-сайентист и как им стать 02 марта 2017, 14:07
-
Бизнес Как поисковая строка превратилась в бизнес на $400 млрд: история Google 18 июля 2026, 18:00






-
Технологии Gigabyte открыла предзаказ на видеокарту AORUS GeForce RTX 5070 INFINITY: цена в России — от 105 тыс. ₽ 20 июля 2026, 18:30

-
Россия Россияне тратят на медиаконтент почти 9 часов в день — половину всего времени занимает просмотр ТВ 20 июля 2026, 17:30

-
Россия Хостинг-провайдеры просят сохранить отдельный способ верификации для иностранных клиентов — через банковский платеж 20 июля 2026, 21:00

-
Бизнес Малый и средний бизнес стал чаще получать господдержку — при этом самозанятым выдают средства на 20% реже 20 июля 2026, 20:00

-
Автомобили АвтоВАЗ отмечает 60 лет со дня основания — в свой юбилей компания запустила в производство новую Lada Niva Legend 20 июля 2026, 19:30

-
Автомобили Каршеринг BelkaCar получил 39 исков на 1 млрд ₽ за полгода — большая часть претензий исходит от лизинговых компаний 20 июля 2026, 19:00

-
Россия В ЕГЭ по гуманитарным предметам появится устная часть — экзамены по физике и химии дополнят практическими заданиями 20 июля 2026, 18:00

-
Бизнес Авиакомпании Red Wings и SkyGates объединят в единый холдинг — Ростех начал упорядочивать свои активы 20 июля 2026, 14:38








