
Большие данные и большое будущее

Big data сами по себе мертвы, говорит Михаил Свердлов, директор по стратегическому развитию ИТ в Уральском банке реконструкции и развития. Но идея больших данных осталась в прикладных кейсах и физических объектах – беспилотниках и предметах IoT. Все чаще внимание обращается на машинное обучение и безопасное хранение информации.
… Так, может, большим данным еще предстоит большое будущее?
По миру шагают саммиты, конференции и недели big data. И если последние несколько лет назад евангелисты больших данных воодушевленно рассказывали про наше светлое будущее, то сейчас это больше похоже на панихиду. После выхода очередных магических кривых Gartner гвоздь в крышку гроба big data не забил разве что ленивый.
Я предлагаю разобрать эту историю немного под другим углом, а точнее, под четырьмя углами. Рассмотрим:
- 4 основных проблемы, которые могут возникнуть при работе с большими массивами данных (специально уже не говорю big data – этот термин все похоронили);
- 3 проблемы, которые могут испортить самую правильную инициативу по использованию данных в компании;
- А также поймем, куда Gartner спрятал все осколки, на которые распалась громада больших данных;
- … и как банки могут получать доход от экспорта своих данных или монетизировать чужие данные для себя.
Одни проблемы с этими big data?
Почти месяц назад в Бостоне закончилась конференция Big Data Innovation Summit. Туда съехались ведущие Данных много, а пользы нет? Только проверенные компании, которые специализируются на Big Data эксперты, прошло больше 60 сессий, где рассматривались самые большие проблемы и пути их решения в работе с большими данными.
эксперты, прошло больше 60 сессий, где рассматривались самые большие проблемы и пути их решения в работе с большими данными.
Чтобы не было необходимости смотреть все доклады с конференции, специально для вас я собрал «самую соль». Итак, по большому счету, все жаловались, что управление большими наборами данных может быть проблематичным. Лидеры данных сейчас стоят перед вызовом работы с количеством данных, анализом, хранением, конфиденциальностью и их интерпретацией.
Теперь разберем немного подробнее.
- Где я должен хранить свои данные?
Чем больше данных есть у организации, тем, с одной стороны лучше. Но, другой стороны, тем больше проблем с хранением и управлением возникает. Merrill Lynch из Bank of America рассказывал про то, как они реализовали облачную инфраструктуру под эти нужды, а коллеги из StubHub, MapQuest дополнили это рассказом про Apache Innovation.
- Могу ли я делать это безопасно?
Пять из шести самых крупных по объему и ущербу утечек данных всех времен произошли в течение последних двух лет. В то же время несоблюдение законов о защите данных может привести к искам и существенным потерям. Политика конфиденциальности и безопасности данных уже слишком важна и ее нельзя игнорировать. Чтобы понять, о чем тут речь, можно посмотреть слайды, которые подготовил главный научный сотрудник Счетной палаты правительства США (US Government Accountability Office) Timothy Persons. В своем выступлении он рассказал, как защищает данные Америки.
- False positives
Я не смог найти релевантного аналога в русском языке термину «false positives», поэтому оставил в оригинале. Эксперты говорят, что очень трудно сделать полезные выводы из больших данных без конкретного приложения аналитической модели с хорошим базисом для гипотез. В истории с большими данными быстрые решения иногда могут привести как раз к этим самым «ложным срабатываниям». Jack Levis, директор по управлению процессами UPS, объяснил, как организациям решать проблемы и задачи с помощью аналитики.
- Неправильные выводы
Работа с большими данными может как направить нас в сторону более точного прогнозирования поведения клиентов и просто будущего, так и увести в сторону. Последнее может произойти, если принимать информацию за чистую монету, без поправки на человеческий фактор, который имеет основное влияние на участие в процессе подготовки данных, анализе и выводах.
Как вишенка – доклад Riley Newman, главного по данным в Airbnb, «A/B тестирования в реальном мире».
А тут доступны все материалы конференции.
Если вы хотите все-таки почитать тексты в первоисточнике – вот свежий Big Data Innovation Magazine.
Fail
Gartner в своем исследовании говорят, что почти все компании полагаются на большие данные при принятии более взвешенных и обоснованных решений. А всего год назад они утверждали, что 3 из 4 организаций уже инвестируют или будут инвестировать в большие данные на горизонте ближайших двух лет. Пока опустим тему, что большие данные ушли из Garter уже в сентябре, про это – в третьей части нашего «детектива».
А пока – вот 3 распространенных сценария, которые, по мнению ребят из Lavastorm Analytics, могут убить все ваши начинания в работе с данными:
- Данные ради данных – их будет невозможно применить в разрезе конкретного бизнес-процесса и бизнес-контекста;
- Традиционные ETL-системы и подходы, которые сейчас реализованы в компаниях, не потянут сложность и комплексность работы с большими массивами данных;
- Проекты превратятся в «лоскутное одеяло» и, соответственно, не смогут обеспечить комплексного решения бизнес-потребностей.
Подробно можно почитать в отчете компании.
Gartner здесь, Gartner там
Наверняка все уже видели последний Gartner 2015 Hype Cycle, который говорит о том, что big data ушла, а на ее место встало машинное обучение.
Если вы не следили за ситуацией, то вот картинки 2014 и 2015 годов.
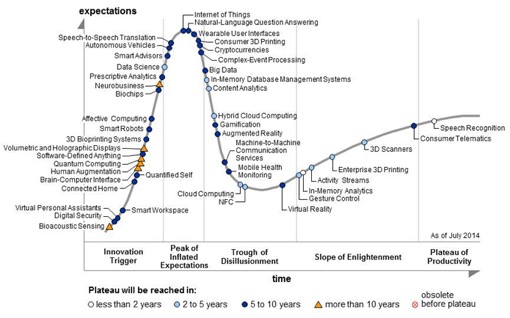
Gartner 2014 Hype Cycle
И для сравнения –

Gartner 2015 Hype Cycle
Конечно, было бы совсем обидно, если бы сначала раззадорились, а потом большие данные попросту ушли бы в небытие. Но нет: все распалось на более осязаемые и прикладные кейсы. На пике теперь нас ждут автономные автомобили, IoT, «умная пыль» и другие новые интересные технологии. Но это в следующей декаде, а пока поговорим про то, куда «приземлились» большие данные.
- Автономные транспортные средства. Успешно перескочив с пре-пика 2014 года на пик в 2015 году, беспилотные машины обосновались в краткосрочных планах крупнейших автоконцернов мира;
- Интернет вещей (сеть интеллектуальных объектов вокруг нас с координацией деятельности) неизменно остается на пике второй год подряд. Считается, что нам предстоит чуть ли не следующая индустриальная революция, и, как вы понимаете, в основе всего – данные и аналитика;
- Машинное обучение, впервые появившись на кривой Gartner, сразу же попало мимо пика завышенных ожиданий, и теперь занимает место больших данных.
По теме: Как устроены нейронные сети
- Цифровой гуманизм (digital humanism), по мнению экспертов Garner, делает лучше людей, а не технологии. Носимые гаджеты, интернет вещей и машинное обучение дали развитие человеку в цифровом мире;
- Citizen data scientist: еще одна новинка сезона. По словам Александра Линдена из Gartner, уже сейчас стоит выращивать новое поколения специалистов по данным, сitizen data scientists, компетенции которых будут лежать на стыке бизнеса, математики и социальных наук. Это позволит им более качественно накладывать аналитику на массивы данных;
- Цифровые навыки (digital dexterity) – тоже новичок списка.
Сегодняшние сотрудники обладают в большей степени цифровой ловкостью. Они сами разрабатывают и монтируют беспроводные сети дома, связывают различные устройства и управляют ими, свободно используют приложения и веб-сервисы практически в каждом аспекте своей личной жизни.
– Мэтт Кейн, вице-президент по исследованиям Gartner.
Gartner наметил несколько способов, в которых ИТ-организации должны использовать цифровые навыки своих сотрудников.
- Безопасность данных (data security) вызывает сегодня большой вопрос, как я уже упоминал ранее, и остается одним из вызовов на ближайшее время.
Что-то из этого списка опять будет раздуто евангелистами в новые прорывные вещи, а другое исчезнет, не получив развития. Я же предлагаю перейти к самой прикладной части нашего расследования по большим данным – к непосредственному применению. В банке.
Моя big data круче твоей
Сразу же за саммитом в Бостоне в России проходила конференция «Большие данные 2015», где я предложил свое видение того, как можно монетизировать данные в банке. Сейчас я хочу поделиться основными темами своего рассказа.
Всю ситуацию с big data, на мой взгляд, можно описать всего одной цитатой:
Big data – как подростковый секс. Каждый говорит об этом, никто толком не знает, как это делается, и каждый уверен, что все остальные это делают. Поэтому все говорят, что тоже этим занимаются…
– Dan Ariely.
За последние 2 года работы с проектами по клиентским данным в Дирекция стратегического развития ИТ в «УБРИР» получила десятки подтверждений. Мы рассмотрели за это время порядка 15 компаний и 28 кейсов, которые мы реализовывали для клиентской аналитики, скоринга, стратегий взыскания. В итоге пришли к тому, что big data – это красивая маркетинговая история, кейсы же реализуются на данных и с помощью машинного обучения.
По теме: Как технологии помогают коллекторам собирать долги
Слайдами с кейсами и направлениями монетизации данных в финансовых организациях я и предлагаю закончить наш разговор.
С радостью отвечу на все возникшие вопросы.
Фото на обложке: Shutterstock.
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Популярное
Налог на прибыль организаций
Материалы по теме
-
Пройти курс «Как построить личный бренд»

- 1 Недельный приток средств в акции компаний стал рекордным за последние 4 года Инвесторы вкладывались в акции, подешевевшие на фоне новостей о новом штамме коронавируса 08 декабря 21:44
- 2 Кривая Гартнера: эксперт рассказал про самые хайповые технологические тренды 2024 года Хайповые технологические тренды 2024 года от Gartner 11 октября 11:56
- 3 10 прогнозов Gartner для сферы ИТ на 2023 и последующие годы От виртуальных офисов до сокращения разрыва в зарплате 16 декабря 16:34
- 4 Нейромайнинг, гипертокенизация и синтетические данные: 10 стратегических прогнозов от Gartner На 2022 год и далее 25 октября 17:19