Как устроен рынок big data в России
К кому идти за железом, алгоритмами и консультациейК кому идти за железом, алгоритмами, консультацией и готовыми решениями
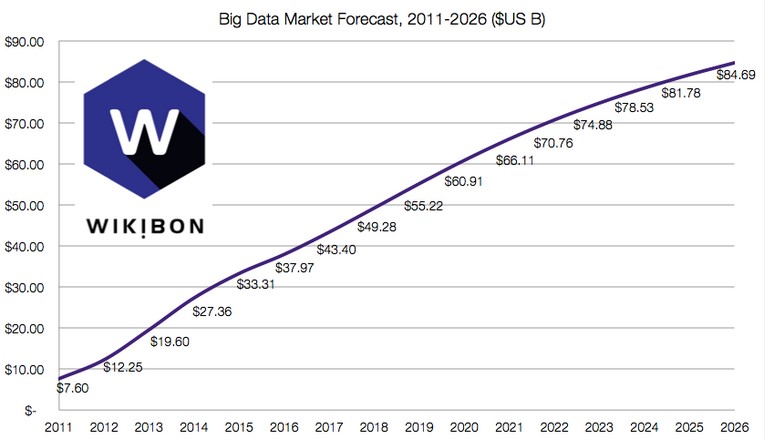
В 2015 году мировой рынок продуктов и услуг для работы с big data составит $33,3 млрд. Такая цифра приводится в мартовском исследовании американского агентства Wikibon. По их прогнозу, к 2020 году объем индустрии больших данных вырастет до $61 млрд, в 2026 году — до $85 млрд. Каждый год этот рынок прибавляет примерно на 17%.
Данных много, а пользы нет? Только проверенные компании, которые специализируются на Big Data
В мировом масштабе российский рынок услуг и технологий big data исчезающе мал. В 2014 году американская компания IDC оценивала его в $340 млн. Зато растет он значительно быстрее глобального — как минимум на 40% в год. По некоторым данным, по итогам 2015 года он увеличится до $500 млн (возможно, эту цифру придется корректировать из-за девальвации рубля).
Известно, что большие данные существовали задолго до появления самого термина. Поисковики и соцсети изначально строили свои сервисы на технологиях обработки big data. Сегодня к большим данным обратился и традиционный бизнес. Прежде всего, в датамайнинге заинтересованы представители зрелых и высококонкурентных рынков — им очень нужны новые инструменты повышения эффективности. Из 108 компаний, опрошенных в феврале агентством СNews Analytics, 40 уже приступили к работе с большими данными. Главными покупателями таких решений остаются банки (24 из 43 респондентов) и телеком-операторы (8 из 12 собеседников СNews). Также технологии обработки больших данных активно используются в онлайн-рекламе и ритейле.
Судя по открытым источникам, решения по анализу больших данных внедрены в Сбербанке, Газпромбанке, ВТБ24, «Альфа-Банке», ФК «Открытие», «Райффайзенбанке», «Ситибанке», «Нордеа-Банке», банке «Уралсиб», «ОТП Банке», компании «Тройка Диалог», «Всероссийском банке развития регионов» и «Уральском банке реконструкции и развития», а также у главных телеком-операторов. Из крупных ритейлеров этими технологиями пользуются X5 Retail Group, «Глория Джинс», «Юлмарт», сеть гипермаркетов «Лента», «М.Видео», Wikimart, Ozon, «Азбука вкуса», из нефтяных компаний — «Транснефть», «Роснефть» и «Сургутнефтегаз».
По теме: Мир big data в 8 терминах
А вот в госсекторе, где технологии big data могут дать взрывной прирост эффективности, они используются относительно слабо. По словам экспертов, среди госструктур обработку big data внедрили Федеральная налоговая служба, аналитический центр правительства России, Пенсионный фонд, правительство Москвы, Фонд обязательного медицинского страхования, Федеральная служба безопасности, Следственный комитет и Служба внешней разведки. С применением анализа больших данных в отечественной медицине все печально — о реальных внедрениях речь пока не идет, несмотря на высочайший потенциал.
В преддверии нашей конференции о больших данных ICBDA 2015 рассказываем о том, как устроена индустрия big data в России. Наш обзор призван дать общее представление о рынке, а не исчерпывающий список игроков (как обычно, дополняйте в комментариях).
Для удобства читателя мы разделили участников рынка big data на несколько категорий (на деле границы между ними не так уж и четки):
● поставщики инфраструктуры, которые решают задачи хранения и предобработки данных (Sap, Oracle, IBM, EMC, Microsoft и др.);
● датамайнеры — разработчики алгоритмов, которые помогают клиентам извлекать ценность из больших данных (Yandex Data Factory, «Алгомост», Glowbyte Consulting, CleverData и др.);
● системные интеграторы, которые разворачивают системы анализа больших данных на стороне клиента («Форс», «Крок» и др.);
● потребители, которые покупают программно-аппаратные комплексы и заказывают алгоритмы у консультантов (телеком, банки, ритейл и др.);
● разработчики готовых сервисов на базе больших данных (в основном цифровой маркетинг), которые открывают возможности big data для широкого круга пользователей, в том числе для малого и среднего бизнеса.
Что касается рынка данных, он в России только зарождается. Внутри экосистемы RTB поставщиками данных выступают владельцы программатик-платформ управления данными (DMP) и бирж данных (data exchange). Телеком-операторы в пилотном режиме делятся с банками потребительской информацией о потенциальных заемщиках.
Обычно большие данные поступают из трех источников:
- интернет (соцсети, форумы, блоги, СМИ и другие сайты);
- корпоративные архивы документов;
- показания датчиков, приборов и других устройств.
Конечно, экспертные классификации игроков рынка технологий для больших данных куда сложнее и выглядят примерно так:
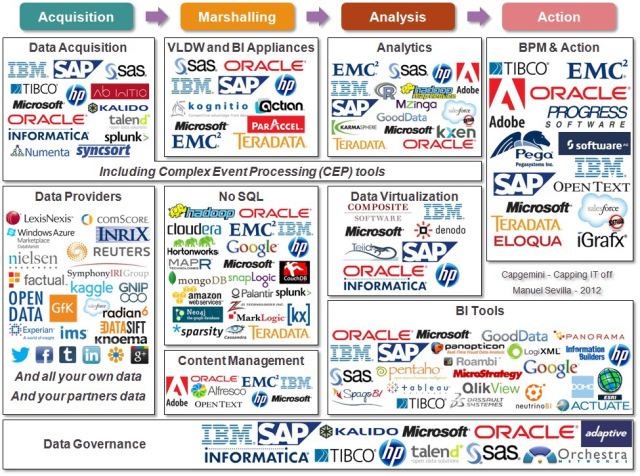
Основные поставщики инфраструктуры
Они продают специализированные системы управления базами данных, программно-аппаратные комплексы и сопутствующий аналитический софт — напрямую или через официальных дистрибьюторов. Разбираться в этих продуктах нужно компаниям с собственной экспертизой в сфере анализа больших данных. Поэтому многие предпочитают доверяться системным интеграторам и IT-консультантам, которые подбирают железо и софт под задачи клиента.
SAP
На рынок бизнес-аналитики немецкая SAP вышла в 2007 году, купив фирму Business Objects. Сегодня в ее портфель решений для работы с big data входят аналитические системы управления базами данных SAP Hana и SAP IQ, СУБД в оперативной памяти SAP Hana, SAP Event Stream Processing на базе Hadoop, инструмент визуализации Lumira и софт для прогнозной аналитики от KXEN (SAP купила ее в 2013 году). По части оборудования вендор сотрудничает с Dell, Cisco, Fujitsu, Hitachi, HP и IBM.
В России продуктами SAP для работы с большими данными пользуются, например, Федеральная налоговая служба, Пенсионный фонд, банковская группа «Открытие» и энергетический холдинг «Сибирская генерирующая компания». В октябре 2014 года SAP запустила 9-месячный акселератор для стартапов в сфере big data, четыре из них дошли до уровня прототипов.
Oracle
Американская корпорация продает широкий спектр технологий для больших данных — специализированные устройства, системы управления базами данных, различные аналитические приложения. В 2014 году Oracle купила облачную платформу управления большими данными BlueKai, получив ее массивы неструктурированной информации (самые большие на американском рынке).
В линейке вендора — аналитические СУБД Oracle Database, Oracle MySQL и Oracle Essbase, СУБД в оперативной памяти Oracle TimesTen, Oracle Event Processing на базе Hadoop, программно-аппаратные решения Oracle Big Data Appliance, Exadata и Exalytics. В России продуктами Oracle пользуются, например, Федеральная налоговая служба и «Альфа-Банк».
IBM
По расчетам Wikibon, в прошлом году американская компания стала лидером по заработку на big data ($1,4 млрд). IBM продает оборудование для работы с большими данными IBM PureData и Watson, СУБД DB2, систему для Hadoop BigInsights, систему интеграции данных InfoSphere, инструменты бизнес-аналитики Cognos, SPSS и другие продукты. Крупнейшие потребители решений IBM для больших данных в России — Пенсионный фонд и компания «Вымпелком».
Microsoft
Компания предлагает технологии big data для любого масштаба бизнеса. Небольшим компаниям адресован инструмент Power BI, который входит в Office 365 и встроен в приложение Excel. Сервис включает публичный и корпоративный каталоги данных, новые инструменты поиска информации, интерактивную визуализацию и широкие возможности для совместной работы.
Ряд решений для работы с большими данными доступен пользователям облачной платформы Microsoft Azure. Так, обрабатывать информацию в режиме реального времени помогает Azure Stream Analytics, извлекать сведения из различных источников и управлять потоками данных — Azure Data Factory, а составлять бизнес-прогнозы — инструмент машинного обучения Azure Machine Learning.
Другая платформа Microsoft — SQL Server — позволяет управлять любыми объемами информации в облаке или в собственной инфраструктуре. В SQL Server 2014 реализована технология in-memory OLTP, которая в среднем в 100 раз повышает производительность обработки транзакций за счет выборочного переноса высоконагруженных таблиц в оперативную память.
Teradata
Американская компания специализируется на программно-аппаратных комплексах для обработки и анализа данных. В линейку продуктов для big data входят устройство Teradata Data Warehouse Appliance, платформа Teradata Aster Discovery и аналитическое ПО. Также компания оказывает услуги по анализу больших данных. В России решения Teradata внедрены у Федеральной налоговой службы, банка «ВТБ24», «Сбербанка» и «Ситибанка».
Pivotal (EMC)
В 2013 году корпорация EMC открыла подразделение Pivotal. Оно занимается обработкой больших данных и поставляет решения PaaS (платформа как услуга) и IТaaS (ИТ как услуга). Для big data компания предлагает базу данных Greenplum, SQL-механизм обработки HAWQ для Hadoop и in-memory СУБД GemFire. В марте корпорация представила озеро данных Federation Business Data Lake. В России решения EMC используют «Тинькофф-банк» и компания «Тройка Диалог» (ныне Sberbank CIB).
SAS
SAS считается одним из пионеров business intelligence. Компания продает решения для бизнес-аналитики, управления данными и их анализа. Заказчикам SAS предлагает консалтинг, внедрение, обучение и техническую поддержку. Продукты компании для работы с большими данными используют «Сбербанк», «Тинькофф-банк», «ЮниКредит Банк», ВТБ24, РЖД и Теле2.
Продукты SAS для big data решают различные типы задач. В линейку входят технологии управления распределенными вычислениями SAS Grid Computing, продукты на базе in-database вычислений и продукты на базе технологии in-memory. К последней группе относятся платформа для интерактивного исследования и визуализации данных SAS Visual Analytics, интерактивная среда для анализа данных SAS In-Memory Statistics, инструмент для создания аналитических моделей SAS Visual Statistics, средство для ускоренного аналитического моделирования SAS Factory Miner, SAS Event Stream Processing Engine для анализа потока событий в режиме реального времени, механизм анализа текста SAS High-Performance Text Mining и другие инструменты.
HP Vertica
Для больших данных компания поставляет облачную платформу HP Haven, базу данных HP Vertica Community Edition для бюджетного создания продуктов на основе обработки больших данных, HP Vertica Enterprise Edition — для более масштабных проектов, софт HP Autonomy — для анализа разноформатной информации (видео, аудио, соцсетей).
Технологии НР для big data используются для анализа текстов объявлений Avito, таргетирования рекламы в онлайн-кинотеатре Ivi.ru, анализа поведения клиентов и расчетов в реальном времени в банке «Открытие», автоматизации отчетности в сети «Глория Джинс», ускорения тестирования продуктов в «Связь-банке». Первым российским покупателем аналитической системы HP Vertica стала Yota Networks. Кстати, решения HP Vertica для хранения и анализа больших данных использует Facebook.
Cloudera
Компания из Калифорнии продает наиболее популярный дистрибутив свободно распространяемого фреймворка Hadoop. Полная версия продукта Cloudera Distribution Hadoop включает программные инструменты Cloudera Impala, Cloudera Search, Apache HBase, Accumulo, Spark и Kafka. Аппаратных решений у компании нет. В прошлом году корпорация Intel инвестировала в Cloudera $740 млн. В России решениями Cloudera пользуются «Сбербанк» и «Тинькофф-банк».
Google
На рынок бизнес-аналитики корпорация вышла в 2012 году, запустив облачный сервис анализа больших данных в режиме реального времени Google BigQuery. Через год его интегрировали в платную версию счетчика Google Analytics Premium. Обновленная версия BigQuery способна анализировать до 100 тысяч строк данных в секунду. Недавно Google представила новую специализированную базу данных Cloud Bigtable, которая подходит для big data лучше предшественницы Cloud Dataflow.
В России решения Google для больших данных можно купить у официальных реселлеров — российского представительства украинской компании OWOX и отечественных агентств iConText, Adventum, «Кокос», AdLabs и i-Media. Судя по открытым источникам, сервисом BigQuery пользуются «М.Видео», «Юлмарт», «Связной», Ozon.Travel, «Эльдорадо», Onlinetours, Anywayanyday и «Вымпелком».
Amazon Web Services
Компания создана в 2006 году как облачный сервис хранения данных. В последние годы AWS расширяет линейку решений для больших данных. Это NoSQL-база данных Amazon DynamoDB, реляционная СУБД Amazon RDS, сервис анализа потоковых данных в режиме реального времени Amazon Kinesis, петабайтное хранилище данных Amazon Redshift, архив Amazon Glacier. Также AWS предоставляет Hadoop через облачный сервис Amazon Elastic MapReduce.
В рамках специальной программы поддержки AWS дает молодым предпринимателям бесплатный доступ к своим облачным ресурсам. Так что услугами компании пользуются многие российские и зарубежные стартапы. В прошлом году к программе AWS Activate присоединился фонд «Сколково», обеспечив своим резидентам доступ к продуктам Amazon. Из более крупных отечественных пользователей AWS известен отраслевой портал «Банки.ру».
Датамайнеры
Датамайнеры извлекают знания из накопленных клиентами больших данных. По некоторым оценкам, мировой рынок анализа данных ежегодно растет на 40% в год и к 2016 году превысит $50 млрд.
Некоторые сервисы обработки данных работают по модели big data as a service (BDaaS), позволяя загрузить данные в облако и получить результат. Они избавляют предпринимателя от необходимости нанимать дорогие кадры и налаживать собственную инфраструктуру. А если клиенту нужен функционал шире стандартного — можно заказать апгрейд.
Малому и среднему бизнесу датамайнинговые сервисы доступней, чем дорогое оборудование. «Вне зависимости от специализации компании-заказчика, готовый сервис анализа данных позволяет быстро получить конкурентные преимущества и адаптироваться к изменяющимся условиям рынка», — писал в своей колонке big data архитектор компании AT Consulting Алексей Беднов.
Yandex Data Factory
На анализе больших массивов данных построено большинство продуктов «Яндекса» — поиск, машинный перевод, фильтрация спама, рекламный таргетинг, рекомендации, распознавание образов и речи, предсказание пробок. Использовать свои технологии для внешних заказчиков IT-компания начала с 2012 года. С тех пор отечественный IT-гигант делал проекты для нефтяных компаний («Роснефти» и норвежской Statoil), прогнозировал отток абонентов для неназванного телеком-оператора, просчитывал экономичные маршруты для самолетов, снижал процент отказов европейских банкоматов.
В декабре IT-компания объявила о создании международного подразделения Yandex Data Factory. Оно специализируется на обработке больших данных для крупного бизнеса. Основными клиентами Yandex Data Factory стали телеком, банки, ритейл и промышленные предприятия. Для Росавтодора YDF разработал систему прогнозирования пробок и ДТП, для разработчика онлайн-игр Wargaming предсказал отток игроков, а с британской биофармацевтической компанией AstraZeneca сотрудничает в области здравоохранения. В июле YDF стал консультантом Сбербанка по big data, а в августе договорился с Магнитогорским металлургическим комбинатом о создании проекта по оптимизации плавки стали. Для анализа больших данных «Яндекс» применяет решения собственной разработки.
«Алгомост»
Алгоритмы датамайнинга для решения бизнес-задач компания разрабатывает с 2012 года. Ее аналитические решения адресованы ритейлу, банкам, транспорту, телекому, здравоохранению, страхованию и государству. «Алгомост» консультирует, создает алгоритмы и поддерживает их дальнейшее развитие. Клиент только ставит задачу — например, увеличить прибыль, сократить издержки, оптимизировать бизнес-процессы, опередить конкурентов, привлечь новых клиентов и партнеров и т.д. Алгоритмы пишут как разработчики «Алгомоста», так и независимые датамайнеры, которых компания привлекает в ходе открытых конкурсов (охват более тысячи специалистов по всему миру). В 2013 году «Алгомост» стала резидентом ИТ-кластера «Сколково».
IBS
Большими данными отечественный IT-холдинг занялся в 2004 году, когда начал разрабатывать аналитическую платформу для сервиса мониторинга медиаполя «Медиалогия». Клиентам из финансового сектора IBS делала алгоритмы для расширенного скоринга, обогащения клиентского профиля, противодействия мошенничеству, а также анализировала транзакции. Для госструктур компания решала задачи текстовой аналитики и помогала выстраивать инфраструктурy big data. В кооперации с YandexDataFactory холдинг работал над системой прогнозирования ситуации на дорогах для «Росавтодора».
В портфеле IBS есть решения по обработке больших данных для телеком-операторов, банков, ритейла и госсектора. Широкий круг клиентов она консультирует в области data governance — стратегии управления корпоративными данными как источником эффективности. Компания сотрудничает с ключевыми поставщиками решений для big data: SAP, Oracle, IBM, SAS, Teradata и т.д.
«Прогноз»
Разработчик BI-систем из Перми лидирует на российском рынке заказного ПО и продает свои продукты более чем в 70 странах. Флагманская разработка компании Prognoz Platform содержит спектр инструментов от классического BI до продвинутой аналитики и возможностей data discovery. В октябре прошлого года компания выпустила обновленную версию платформы, расширив ее возможности работы с большими данными. Она интегрирована с программно-аппаратными комплексами Oracle Exadata, IBM Netezza и EMC Greenplum, поддерживает распределенное хранение и обработку big data в Hadoop Hive, язык HiveQL и работу в «облаке».
У «Прогноза» есть специализированные аналитические решения для госсектора, корпораций, финансовой сферы и других отраслей. Prognoz Platform используют российские госорганы, банки, научные организации и крупные компании — всего больше 200 внедрений внутри страны.
AT Consulting
Российская ИТ-компания реализует проекты в сфере big data c 2012 года. Среди клиентов компании, применивших эти технологии, – банки, телекоммуникационные операторы, госструктуры. AT Consulting искала возможности улучшения транспортной системы Москвы, создавала антиспам-роботов, анализировала отток абонентов и пр. Один из крупнейших клиентов компании в данной сфере — «ВымпелКом», для которого был разработан промышленный кластер big data. Например, через него в онлайн-режиме формируются таргетированные предложения для абонентов на основе данных об их местоположении, статистики потребления услуг, а также различных сетевых данных.
Data-Centric Alliance
Компания предоставляет сервисы, основанные на технологиях big data, а также решает задачи клиентов в индивидуальном порядке. Готовые решения Data-Centric Alliance лежат в плоскости цифрового маркетинга. Это programmatic-платформа Exebid DCA, платформа управления большими данными Facetz.DCA, платформа для продажи рекламного инвентаря Spicy, сервис рекомендаций для сайта Booster, разработка для вычисления портрета клиента Prizma, инструмент для привлечения интернет-аудитории SmartTDS.
Отдельные проекты компания делает для некоторых телеком-операторов, банков и ритейла. Из публичных кейсов: в июле Data-Centric Alliance вместе с провайдером Wi-Fi доступа в московском метро «Максима Телеком» запустила рекламную платформу для малого и среднего бизнеса. В начале августа компания с помощью big data составила портрет аудитории 30 ведущих интернет-СМИ.
CleverData
Дочка отечественной ГК «Ланит» (создана в 2014 году) внедряет свои и партнерские решения для обработки больших данных. CleverData анализирует клиентскую базу заказчика, конструирует платформы управления внутренними данными компании, оптимизирует процессы RTB-рекламы и строит системы управления операционной эффективностью на базе Splunk. Целевой маркетинг обеспечивают платформа управления данными 1DMP и площадка для монетизации и обогащения данных Data Marketing Cloud. Консалтинговая компания сотрудничает с IBM, Oracle, Teradata, Splunk, Aerospike и Сloudera. В октябре прошлого года CleverData объявила о создании универсальной биржи данных, которая позволит поставщикам и потребителям big data договориться об условиях обмена.
EasyData
Лаборатория больших данных строит высоконагруженные хранилища данных и системы бизнес-аналитики. EasyData известна тем, что привезла в Россию решения HP Vertica. В 2013 году они внедрили эту систему управления базами данных в банке «Открытие», а до этого — в компании Yota Networks.
Glowbyte Consulting
В 2008 году IT-консалтинг стал основной деятельностью компании. Наряду с другими услугами, она выстраивает клиентам процессы обработки и хранения больших данных. Glowbyte Consulting внедряла технологии big data в «Тинькофф-банке», банке «Уралсиб», «ОТП Банке», «Лето Банке», финансовой группе БКС и у телеком-оператора «Дом.ru». Интегратор выступает партнером ведущих вендоров — SAP, Oracle, EBM и других.
Double Data
Стартап предлагает big data решения для финансовых организаций. Путем анализа больших данных из интернета они помогают банкам привлекать новых клиентов, связываться с неконтактными должниками, верифицировать личность потенциального заемщика, оценивать кредитоспособность и выявлять мошенничество.
В 2014 году компания стала резидентом ИТ-кластера «Сколково». В марте этого года Double Data привлекла 200 млн рублей инвестиций от LETA Capital и SimileVenturePartners для выхода на новые отраслевые и географические рынки. В частности, компания видит потенциал в решении задач телекома, страховщиков, туроператоров и e-commerce. На своем сайте они заявляют о готовности создавать новые продукты под задачи заказчика.
DataMining Labs
Питерская компания занимается коммерческой разработкой, научными исследованиями и бесплатным обучением специалистов по data science. DataMining Labs помогает повысить эффективность в маркетинге, финансах, HR и производстве с помощью обработки накопленных клиентом данных. Например, компания анализировала трафик финансовых транзакций, искала аномалии в log-файлах веб-сервисов, предсказывала возврат пользователей.
MLClass
Проект занимается подготовкой кадров для отечественной индустрии big data, формирует сообщество специалистов по data science, помогает работодателям искать data scientists и выполняет крупные заказы по датамайнингу для госсектора. Например, сейчас MLClass применяет методы машинного обучения (иерархической кластеризации и text mining'а) для оценки эффективности отечественных институтов развития предпринимательства по заказу аналитического центра при правительстве РФ.
BaseGroup Labs
С 1999 года компания из Рязани сконцентрировалась на разработке ПО для анализа данных. В итоге многолетние наработки BaseGroup Labs вылились во флагманский продукт — BI-платформу Deductor. На ней базируются готовые решения компании по скорингу, поддержанию качества клиентских данных, планирования закупок. BaseGroup Labs внедряет системы анализа больших данных, оказывает техподдержку, обучает специалистов и выступает вендором платформы Deductor.
Например, компания выстраивала методику выявления аномалий для фонда «Общественное мнение», систему принятия решений по выдаче кредитов для МТС Банка, прогнозную модель распространения эпидемий для противочумного НИИ «Микроб».
Global Innovation Labs
Компания открыла лабораторию анализа данных в 2011 году. Global Innovation Labs применяет свои алгоритмы к данным крупных ритейлеров. Сервис анализирует чеки, трафикообразующие категории, эффективность маркетинговых кампаний, поведение покупателей в магазине, их лояльность и другие метрики. Выявленные закономерности помогают оптимизировать маркетинг, ассортимент и ценовую политику. Своих клиентов Global Innovation Labs не называет.
«Айкумен ИБС»
Анализом больших данных компания занимается с 2010 года. В основе продуктового портфеля «Айкумен ИБС» — аналитическая платформа IQPlatform. Она работает как со структурированной информацией, так и с сырыми данными из разнородных источников. IQPlatform решает задачи обогащения сведений о клиентах и партнерах для поддержки продаж и оптимизации маркетинга, технологической и конкурентной разведки, повышения качества клиентского сервиса, улучшения работы служб безопасности и персонала, управления рисками. «Айкумен ИБС» делала проекты для Сбербанка, Внешэкономбанка, Роскосмоса, «Ростелекома», «Вертолетов России» и «ФСК ЕЭС». Партнеры компании — Oracle и IBM.
IT-консультанты
Системные интеграторы разворачивают систему анализа больших данных на стороне клиента. Они выступают посредниками между технологиями и бизнесом. Это вариант для тех, кому не подходят готовые решения и облачные вычисления. «Преимущество интегратора в том, что он может комбинировать продукты разных вендоров, дополняющие друг друга», — говорил директор IBS по технологиям Сергей Кузнецов в интервью изданию Computeworld.
«Форс»
Направлением big data компания занялась в 2013 году. Они разрабатывают и развертывают аналитические системы для телекома, ритейла, банковского сектора, здравоохранения, госорганов и муниципальных служб. Кроме того, «Форс» предлагает готовый софт для анализа аудитории с помощью данных из соцсетей (ForSMedia) и формирования досье контрагента. Компания является официальным дистрибутором и платиновым партнером корпорации Oracle.
«Крок»
Интегратор плотно сотрудничает с EMC, HP, Oracle и Microsoft, Intel — с их решениями работает центр компетенций «Крок». Проекты в сфере больших данных компания начала реализовывать с 2013 года. Специалисты «Крок» строили модель по уменьшению оттока абонентов для крупного телеком-оператора, прогнозировали пассажиропотоки для «Центральной пригородной пассажирской компании», а сейчас реализуют проект в некой крупной страховой компании. В 2014 году объем направления big data достиг 1% в выручке «Крок».
Готовые сервисы на основе big data
На технологиях анализа больших данных построены привычные нам антиспам, антифрод, programmatic-реклама и товарные рекомендации. Для использования готовых сервисов не нужны ни дополнительные сервера, ни консультанты, ни data scientists. Данные эти системы берут из открытых источников — соцсетей, сайтов, форумов и СМИ. Это открывает клиентам широкие возможности для цифрового маркетинга без затрат на инфраструктуру.
Большие данные занимают центральное место в экосистеме RTB-рекламы. Платформы управления данными (DMP) собирают информацию о пользователях в виде сегментов аудитории, биржи данных (data exchange) — в виде обезличенных профилей. Эти данные обеспечивают максимально точное таргетирование RTB-рекламы, минимизируя затраты рекламодателя и раздражение потенциального покупателя. Такие услуги предлагают отечественные компании Auditorius, Data-Centric Alliance, RTB Media, RuTarget/Segmento, Between Digital, Hubrus DSP, Adfox, AdRiver, GetIntent, Kavanga и другие.
Большими данными из открытых источников оперируют также многочисленные сервисы товарных рекомендаций (Retail Rocket, Crosss, REES46, «1С-Битрикс Big Data»), персонализации контента (Flocktory, Usalytics) и целевого маркетинга (Opiner, SmartBox eCRM, Witget). На этом основании все они тоже являются частью российского рынка больших данных.
О некоторых стартапах, работающих с big data в России, мы подробно рассказали здесь: Кто делает big data в России?
Старейшие отечественные IT-холдинги анализируют большие данные собственными силами. Так они совершенствуют собственные сервисы, таргетируют рекламу и персонализируют контент.
Mail.Ru Group
Задолго до появления термина big data холдинг вовсю использовал технологии обработки больших данных. Первым таким проектом была система веб-аналитики «Рейтинг Mail.Ru». Сейчас анализ больших данных задействован практически во всех продуктах компании — «Таргет.Mail.Ru», «Почта Mail.Ru», «Одноклассники», «Мой Мир», «Поиск Mail.Ru» и других. С помощью обработки big data Mail.Ru фильтрует спам, таргетирует рекламу, оптимизирует поиск, ускоряет работу техподдержки, анализирует поведение пользователей, предлагает им контакты и подписки. Для офлайновой обработки данных компания использует платформу Hadoop, для онлайна — собственную разработку NoSQL СУБД Tarantool.
«Рамблер»
Изначально медиахолдинг работал с большими данными в части поиска. В последние пару лет компания активизировала направление датамайнинга. Технологии big data «Рамблер» применяет для таргетинга рекламы, персонализации контента, блокировки спама и ботов, обработке естественного языка. Технологическая сторона этой работы — платформы для обработки больших данных Hadoop/Spark/Mahout и Python Scipy/Scikit-learn. В дальнейшем компания собирается оттачивать рекламные технологии и персонализацию контента.
Также «Рамблер» ставит на развитие сервисов контентной аналитики для PR. В июле он купил 51% компании RCO, которая выпускает приложения для интеллектуальной обработки текстов на разных языках. Продуктами RCO пользуются «Газпром», Минюст, Центробанк, ФСБ, «Роснано», «МегаФон», «Сбербанк» и другие организации.
Крупные внедрения
А теперь самое время посмотреть на успешные примеры внедрения технологий обработки данных. Особенно показательны телеком-операторы: освоив датамайнинг, они не только повысили качество своих услуг, но и превратили собранные данные в ликвидный актив, востребованный банкирами и чиновниками.
«Мегафон»
Оператор начал осваивать технологии обработки big data два года назад. Основная цель компании — оптимизация затрат и улучшение обслуживания абонентов. В прошлом году «Мегафон» договорился с правительством Москвы предоставлять информацию о структуре столичного населения.
В 2013 году «Мегафон» занялся геоаналитикой — изначально для прогнозирования нагрузок на собственную сеть. Сегодня это направление выросло в отдельный сервис анализа пассажироперевозок для транспортных компаний. Приложение показывает объем пассажиропотока, популярные маршруты и раскладку по видам транспорта. В июле оператор начал переговоры с РЖД, предложив ей свое решение для прогнозирования популярных маршрутов. Совместный проект запустится не ранее 2016 года.
Ну а пока направление big data приносит «Мегафону» около 1% выручки. Для работы с массивами больших данных телеком-оператор использует решения на базе платформы Hadoop. Приоритетом в этой работе компания считает конфиденциальность информации о клиентах, поэтому не привлекает к анализу сторонние разработки.
«Билайн»
Телекоммуникационный холдинг «Вымпелком» использует анализ больших данных для мониторинга качества обслуживания клиентов, подбора сервисов и тарифов, борьбы с мошенничеством и спамом, оптимизации работы колл-центра за счет прогнозирования причины обращения и других задач. Разработкой и внедрением решений в сфере big data занимается специальное подразделение. Массивы данных анализируют с помощью Hadoop, IBM SPSS, Apache Spark и Vowpal Wabbit.
В мае прошлого года «Вымпелком» представила пилотный проект «Умное оповещение». Технология позволяет предупреждать людей, находящихся в зоне чрезвычайной ситуации, а также тех, кто туда может попасть.
В конце мая 2015 года оператор запустил пилотный проект по оценке кредитоспособности своих абонентов. К эксперименту подключились около 20 банков. Они получают от «Вымпелкома» обезличенные скоринговые баллы, рассчитанные по платежам за мобильную связь, оплате услуг со счета мобильного оператора и даже данным геолокации.
В части больших данных компания сотрудничала с Генпланом Москвы, Дептрансом Санкт-Петербурга, а на днях выиграла тендер Департамента информационных технологий Москвы на SMS-информирование москвичей (сумма контракта 78 млн рублей).
МТС
Решения для анализа больших данных корпорация внедряет с 2011 года. Информация о профиле потребления интернет-трафика, типах используемых устройств, круге общения и покупках абонента позволяет МТС делать абонентам персональные предложения. Статистику передвижений абонентов компания давно использует для прогнозирования нагрузки на сети. Эти же данные сотовый оператор предоставляет правительству Москвы в рамках совместного проекта по развитию городской инфраструктуры. Как ожидается, мобильная геоаналитика поможет властям определиться с размещением новых магистралей и станций метро. С банками МТС провела пилотный проект по скорингу абонентов. Продукт будет готов до конца года, после завершения технического решения по оценке рисков заемщика.
Также с помощью big data компания намерена прогнозировать поведение абонентов, бороться с мошенничеством, разрабатывать предложения на основе таргетинга, улучшать качество покрытия сети, повышать эффективность управления собственной розничной сетью и развивать радиосеть на основе абонентских данных. Для хранения и обработки данных оператор использует Apache Hadoop, Apache Spark, Cloudera Impala, БД Teradata и решения SAS.
«Сбербанк»
В стратегии банка на 2014-2018 гг. говорится о важности анализа супермассивов данных для качественного обслуживания клиентов, управления рисками и оптимизации затрат. Сейчас банк использует big data для управления рисками, борьбы с мошенничеством, сегментации и оценки кредитоспособности клиентов, управления персоналом, прогнозирования очередей в отделениях, расчета бонусов для сотрудников и других задач.
По данным CNews, Сбербанк применяет Teradata, Cloudera Hadoop, Impala, Zettaset, стек продуктов Apache (Hadoop, HBase, Hive, Mahout, Oozie, Zookeeper, Flume, Solr, Spark и пр.), специализированные базы данных (Neo4j, MongoDB и т.д.) и собственные решения в области data mining, predictive/prescriptive-аналитики, обработки естественного языка.
В организации работает лаборатория по big data. Банк намерен подключить к анализу больше типов своих внутренних данных и задействовать внешние источники (например, данные из соцсетей). В марте Сбербанк купил рекламную платформу Segmento, чтобы использовать ее данные для персонализации предложений своих клиентам и привлечения новых. В июле банк привлек «Яндекс» в качестве консультанта по анализу больших данных.
ВТБ24
Банк пользуется большими данными для сегментации и управления оттоком клиентов, формирования финансовой отчетности, анализа отзывов в соцсетях и на форумах. Для этого он применяет решения Teradata, SAS Visual Analytics и SAS Marketing Optimizer.
«Альфа-банк»
За большие данные банк взялся в 2013 году. Он использует эти технологии для анализа соцсетей и поведения пользователей сайта, оценки кредитоспособности, прогнозирования оттока клиентов, персонализации контента и вторичных продаж. Для этого он работает с платформами хранения и обработки Oracle Exadata, Oracle Big Data Appliance и фреймворком Hadoop.
Возможности дополнительной монетизации своих массивов данных «Альфа-банк» видит в рекомендательных системах, анализе линейки продуктов и предиктивном анализе поведения клиентов.
«Тинькофф-банк»
С помощью EMC Greenplum, SAS Visual Analytics и Hadoop банк управляет рисками, анализирует потребности потенциальных и существующих клиентов. Большие данные задействованы также в скоринге, маркетинге и продажах.
«Газпромбанк»
Банк применяет big data для скоринга, противодействия мошенникам, оперативного получения отчетности, персонализации предложений, доскоринговой проверки репутации потенциальных заемщиков, предоставления информации регуляторам и других задач.
Если вы вспомнили другие продукты для работы с большими данными или какие-нибудь интересные кейсы — рассказывайте в комментариях.
Фото на обложке предоставлено сайтом Shutterstock.
-
Партнёрский материал Альфа-Банк подвёл итоги первой программы для импортёров: шесть компаний получили гранты по 1 млн ₽ 26 июня 2026, 09:44

-
Личное Дарио Амодеи. Как обыграть OpenAI и создать самый дорогой ИИ-стартап в мире 16 июня 2026, 12:05

-
Бизнес «Русские шрифты скачать». Как зарабатывают шрифтовые студии в России 03 июля 2026, 12:00

-
Личное Ли Шуфу. Как мальчик из китайской деревни основал Geely и купил Volvo 01 июля 2026, 20:17

-
Бизнес Не из гаража, а почти из холодильника: история Geely 01 июля 2026, 14:58

-
Технологии От гранта до контракта: как формируется симбиоз бизнеса и науки 03 июля 2026, 13:37

-
Тренды Главные мемы 2026 года и их значение 26 июня 2026, 21:10

-
Искусственный интеллект «Мы знаем 50 миллионов книг через их описания, а не содержание»: зачем Ленинке искусственный интеллект 26 июня 2026, 11:00









-
Бизнес Ozon осенью 2026 года запустит собственный брокерский сервис — сначала он появится в приложении Озон Банка 03 июля 2026, 18:45

-
Бизнес Альфа-Банк поддержал новый бизнес-фестиваль «Атланты Сити»: мероприятие собрало в Сочи более 1700 участников 03 июля 2026, 18:00

-
Банки Ozon Банк установил более 1000 банкоматов по всей России — получить дебетовые карты теперь можно прямо в них 03 июля 2026, 16:30

-
Бизнес «Вкусно — и точка» запускает новую линейку томатных бургеров — в блюда добавят сладко-острый соус из помидоров 03 июля 2026, 14:13

-
Банки На рынке облигаций впервые фиксируют разгон цен — ЦБ может ввести ограничения для торгов бумагами 03 июля 2026, 19:00

-
Россия Россияне в возрасте 35–44 лет арендуют самокаты чаще молодежи: 70% пользователей сервисов кикшеринга — мужчины 03 июля 2026, 17:00

-
Россия На российский рынок выходит электрический кроссовер GAC Hyptec HT — со встроенной платформой «Яндекс Авто» 03 июля 2026, 15:30

-
Искусственный интеллект МТС Линк запустил маркетплейс ИИ-агентов — пользователи уже могут приобрести цифрового помощника для HR и SMM 03 июля 2026, 12:15








