Кейс: как с помощью чат-бота создать датасет из более 10 тысяч изображений за пять недель
И для чего это нужно
Роман Куцев, основатель компании Trainingdata.ru, помогает стартапам создавать датасеты. Используя технологии краудсорсинга на базе «Яндекс.Толоки», Роман собирает датасет из фотографий людей, который в дальнейшем может быть использован для создания дейтинг-платформы.
Для чего нужны датасеты
Датасет — необходимые данные для работы нейросетей. Проще говоря — это то, что является основой так называемого искусственного интеллекта. Как правило, датасеты собираются индивидуально для какой-либо конкретной задачи. Такими задачами могут быть, например, классификация изображений или поиск объектов на фото.
Например, если нужно обучить алгоритм отличать кошек от собак, ваш датасет должен состоять из изображений животных, где для каждой фотографии сказано, кто на ней присутствует — это задача по классификации.
Если нужно научиться находить пешеходов на изображении, то это уже задача определения объекта на изображении (object detection), и в этом случае нужен датасет из изображений, на которых люди выделены прямоугольниками. Также можно обучить алгоритм находить людей по описанию.
Как собрать датасет
Есть два способа собрать или получить датасет с изображениями: простой и сложный. Простой — найти в интернете готовый датасет под конкретно вашу задачу. Для таких целей Google недавно запустил Dataset Search, который позволяет искать датасеты для разных задач.
Но довольно часто нужного датасета для вашей задачи просто не существует, либо лицензия запрещает его использование в коммерческих целях. Поэтому, если готового датасета нет, то остается вариант собрать его самому.

Раньше было много сайтов знакомств, где пользователь указывал рост, вес, возраст, цвет волос человека, с которым хотел бы познакомиться, а сайт предлагал анкеты подходящих кандидатов. Для экономии времени можно упростить механику и находить людей не по формальным критериям, а по описанию их внешности и характеристик.
Например, пользователь указывает в запросе «Хочу найти голубоглазую блондинку, лет 20-25, которая любит детей, увлекается волейболом и лыжами, имеет приятные черты лица, по вечерам ходит в театр», и сайт знакомств показывает подходящих кандидатов. Чтобы обучить такой алгоритм, нужны данные, состоящие из изображений людей и их описаний.
В моем случае готового публичного датасета не нашлось и появилась необходимость создания нового. С помощью приложения «Впечатлятор» я собираю датасет под такую задачу.
Как работает чат-бот
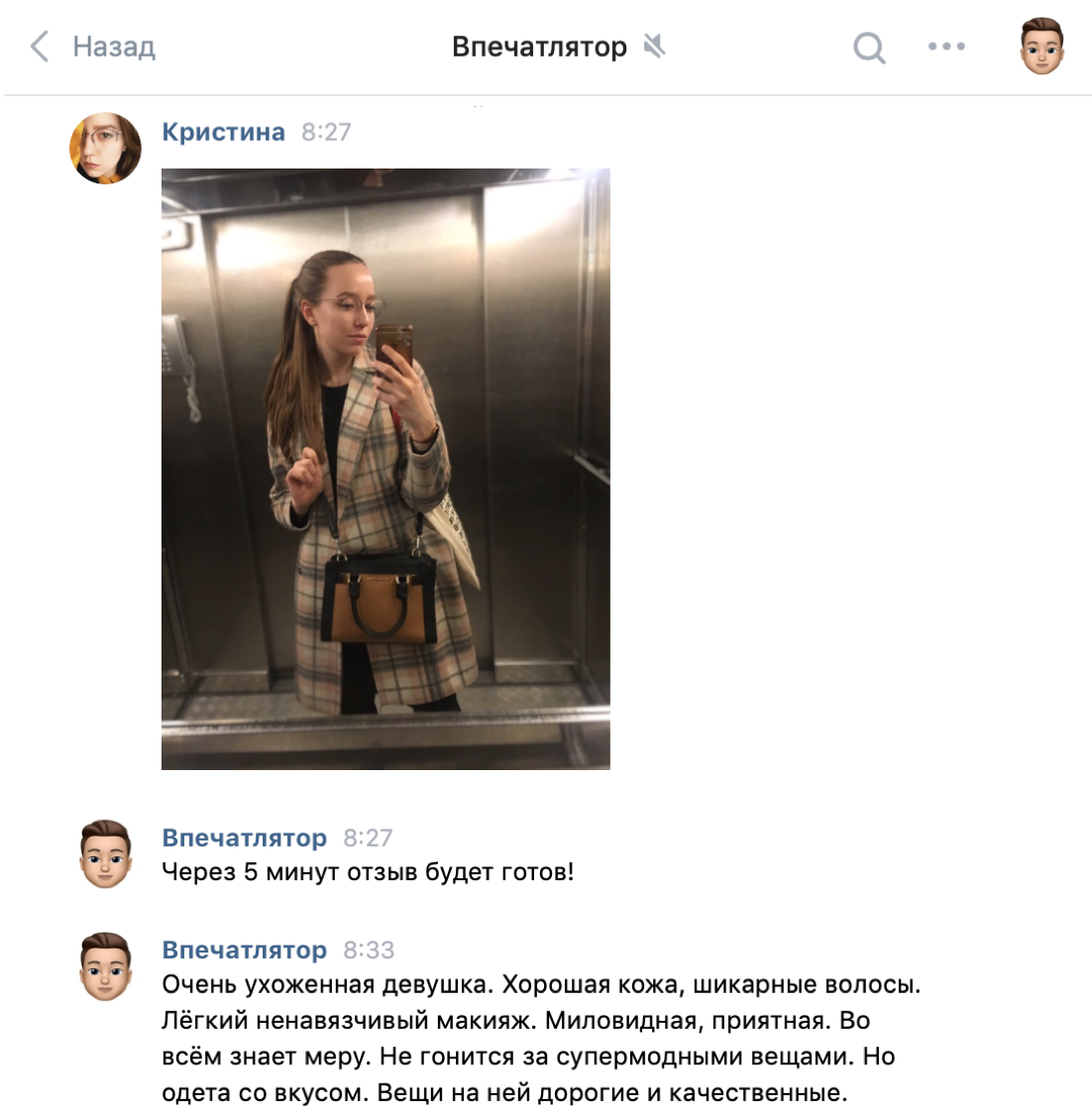
Для решения задачи был создан чат-бот, который описывает первое впечатление о человеке.
Принцип работы очень прост: человек загружает свою фотографию в бот, а через несколько минут получает развернутый отзыв о себе.
С точки зрения пользователя все просто: человек начинает диалог с чат-ботом, принимает условия использования сервиса (так как изображения могут являться персональными данными, а владельцы бота передают изображения в «Толоку», они должны иметь соответствующее право). Затем загружает свое изображение, а через 5 минут получает развернутый отзыв о себе. Первое изображение чат-бот обрабатывает бесплатно, каждое последующее изображение стоит 10 рублей.
Для организации работы бота используются технологии «Яндекса» Yandex Compute Cloud, Yandex Managed Service for PostgreSQL,Yandex Object Storage. После загрузки изображения, с помощью API оно попадает в «Яндекс.Толоку», где толокер пишет развернутый отзыв о человеке на изображении.
Работа с краудом
По мере развития проекта возникла необходимость в помощниках, которые будут обрабатывать запросы. При этом сразу возникала проблема оплаты вознаграждения этим людям. В среднем вознаграждение подобного исполнителя стартует от 300 рублей в час, при этом менеджер должен круглосуточно быть на связи.
Оптимальным решением стал краудсорсинг. Так, в «Толоке» постоянно находятся более 10 тысяч исполнителей, которые готовы круглосуточно выполнять задания и сделают это в разы быстрее, чем единственный исполнитель.
К примеру, у компании есть задача обработать несколько сотен тысяч изображений. Фрилансеры потратят на выполнение такого задания несколько месяцев, а толокеры – несколько часов. Безусловно, придется потратить время на создание задания, критериев контроля качества и ханипотов (заданий-ловушек), но это все равно будет быстрее и дешевле, чем наем исполнителей.
Задачей толокеров было написать характеристику человека на фото.

Вот так выглядит интерфейс у задания.
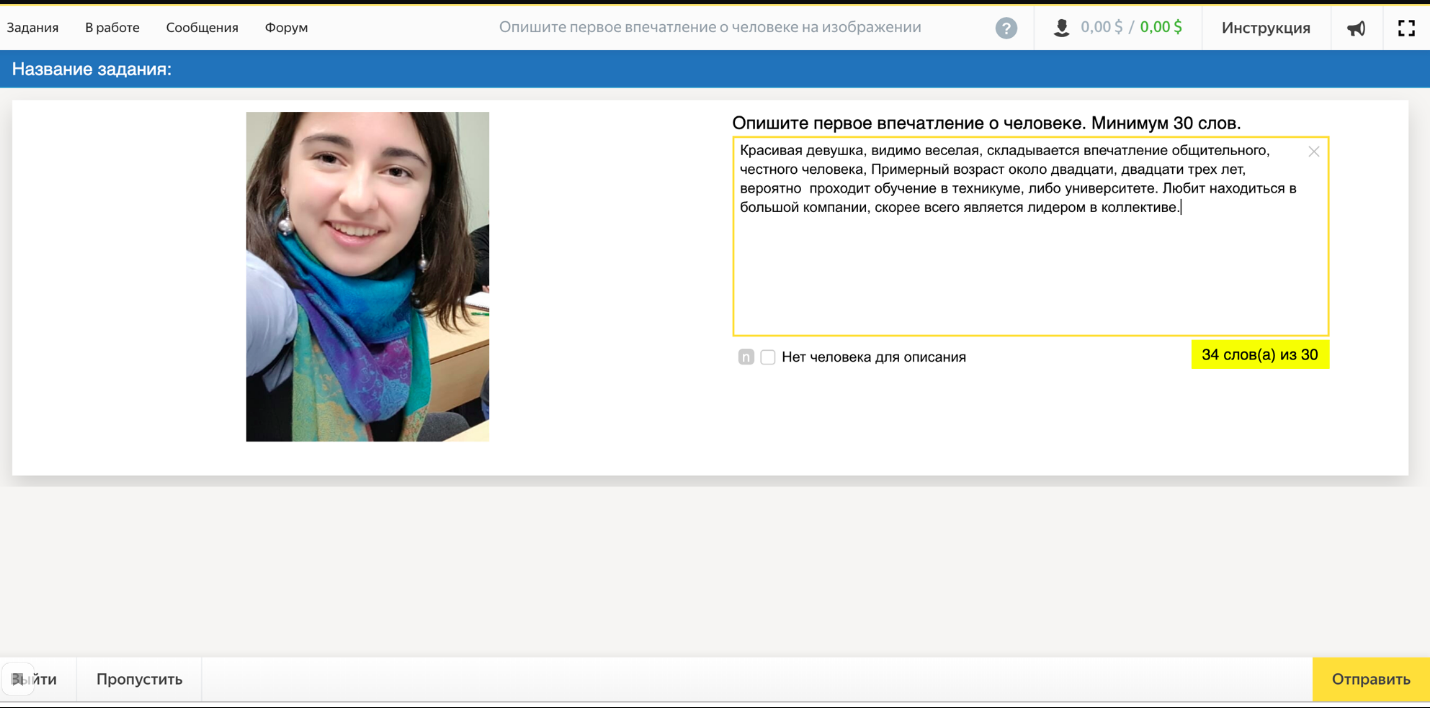
Для обучения нейронных сетей важно, чтобы датасет был размечен правильно, без ошибок. Но иногда случалось, что толокер плохо понял задание, либо ленился и на все задания давал одинаковый ответ, либо допускал грамматические ошибки. Из-за этого могло пострадать качество собираемого датасета.
Сразу после запуска «Впечатлятора» обнаружилось несколько проблем. Так, некоторые толокеры писали скудные отзывы, иногда давали неприятные характеристики, делали ошибки. У толоки есть множество инструментов, которые позволяют отсеять таких исполнителей.
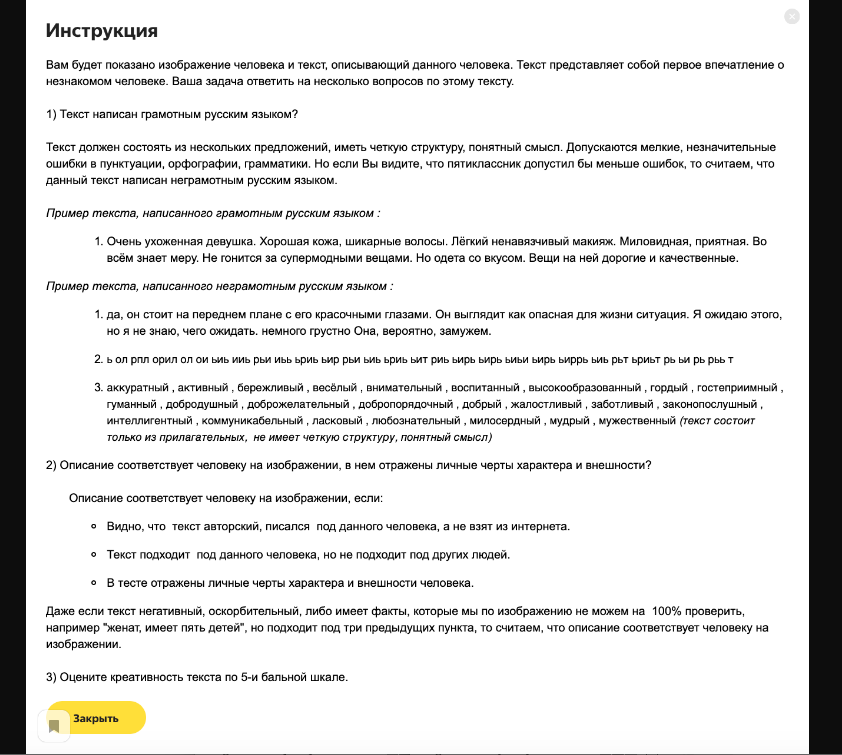
Проблемы удалось решить, когда описания стали проверяться другими толокерами. Независимо друг от друга пять человек раз в сутки оценивали каждый написанный отзыв по четырем критериям:
- отсутствие оскорбительных высказываний в адрес человека;
- грамотность;
- соответствие описания человеку на изображении, отражение в нем личных черт характера и внешности;
- креативность текста по пятибалльной шкале.
Благодаря проверке каждого отзыва, толокерам, которые пишут отзывы, присваивается рейтинг. Толокеры с низким рейтингом блокируются, а толокеры с высоким рейтингом поощряются бонусами, что мотивирует их писать еще лучше. Такой процесс приемки заданий позволяет собирать качественный и вариативный датасет.
Что дальше?
Бот «Впечатлятор» запущен в мае 2019 года, и за первый месяц обработал более 10 тысяч фотографий. В планах на ближайшие три месяца — создание и публикация датасета из 100 тысяч фотографий.
В свою очередь, готовый датасет позволит разработчикам научить алгоритм подбирать профили конкретных пользователей исходя из запроса описания.
Фото на обложке: Unsplash
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Маркетинг Как компании предсказывают желания покупателей и повышают продажи с помощью Big Data 12 ноября 2018, 18:09

-
Бизнес Как повысить продажи в три раза с помощью Big Data и машинного обучения? 17 сентября 2018, 15:34

-
Технологии Нужно остановить big data: «темная сторона» больших данных, о которой вы, возможно, не задумывались 09 августа 2018, 13:37

-
Искусственный интеллект Компании научились собирать данные. Принимать решения — нет: почему цифры не помогают сами по себе 21 июля 2026, 16:04






-
Искусственный интеллект Представляем обновлённую карту искусственного интеллекта от Rusbase 18 июля 2019, 18:21

-
Бизнес Nvidia раскрыла свою долю в Nebius Аркадия Воложа — производителю чипов принадлежит почти 10% компании 21 июля 2026, 20:30

-
Бизнес Иностранных инвесторов могут лишить права на обратный выкуп бизнеса в РФ — их опционы можно отменить через суд 21 июля 2026, 20:00

-
Автомобили Jeland вошёл в топ-10 самых продаваемых марок на авторынке России — спустя всего год после запуска бренда 21 июля 2026, 18:30

-
Банки «Экономика просит снижения, но цены не разрешают»: эксперты оценили вероятность снижения ключевой ставки 24 июля 21 июля 2026, 22:00

-
Автомобили В России начали продавать праворульный кроссовер Subaru Rex — по цене от 1,08 млн ₽ 21 июля 2026, 21:00

-
Технологии Apple готовит iPhone 20 Pro Max размером с планшет — юбилейная модель выйдет в 2027 году 21 июля 2026, 18:00







