
«Иерархия потребностей» для работы с ИИ

Многие компании, повинуясь велению моды, лихорадочно внедряют в свою работу алгоритмы машинного обучения, не заложив для этого надежной основы. Моника Рогати (Monica Rogati), консультант по работе с данными, объяснила в своем Medium, почему эта тактика не принесет ожидаемых результатов.
Рубрика «Инновации в корпорациях» выходит при поддержке Spinon.
Как часто бывает со стремительно развивающимися технологиями, ИИ стал причиной серьезных страхов, сомнений и конфликтов. Что-то из этого было по делу, что-то – нет, но очевидно, что внимание индустрии привлечь удалось. Все игроки – скрытные стартапы, финтех-гиганты, общественные организации – лихорадочно разрабатывают собственную стратегию относительно ИИ. Однако все сводится к одному жизненно важному вопросу: «Как использовать ИИ и машинное обучение, чтобы лучше делать нашу работу?»
Из всех компаний к приходу ИИ готово меньшинство. Возможно, для кого-то найм специалиста по данным оказался не таким уж удачным ходом или в культуре компании грамотность в этом вопросе стоит не на первом месте. Однако чаще всего в компании попросту еще нет инфраструктуры для внедрения (и извлечения выгоды из) даже базовых алгоритмов и операций науки о данных, не говоря уже о полноценном машинном обучении.
Мне как консультанту по данным и ИИ приходилось объяснять это бесчисленное количество раз, особенно в последние два года. Другие специалисты со мной солидарны. Сложно возвращать людей с небес на землю при таком оживлении в отрасли, особенно когда вы сами разделяете это оживление. И как донести до компаний то, что они не готовы к ИИ, и при этом не стать похожим на высокомерного (и самопровозглашенного) контроллера?
Вот объяснение, которое вызвало наибольший отклик:
Представьте подготовку к ИИ в виде пирамиды потребностей. Самореализация (ИИ) – это прекрасно, но сначала вам нужна пища, вода и убежище (грамотность, сбор данных и инфраструктура).
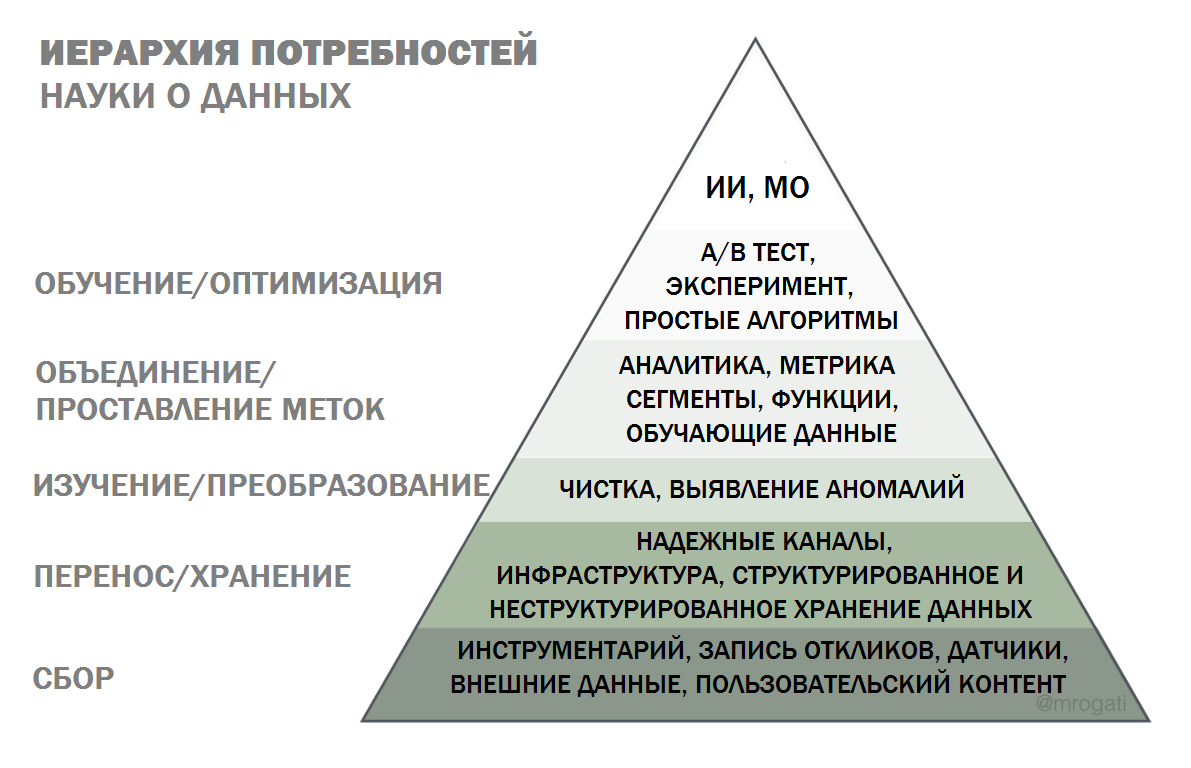
Чтобы эффективно работать с ИИ и машинным обучением, нужно заложить для этого прочное основание.
Базовые потребности: умеете ли вы считать?
В основании пирамиды лежит сбор данных. Какие данные вам нужны и что из этого доступно? Если вы создаете продукт для взаимодействия с пользователем, фиксируете ли вы всю актуальную информацию? Если это датчик, какие данные он собирает и как? Легко ли получить данные о взаимодействии, если инструментарий для этого еще не разработан? В конце концов, именно благодаря правильному набору данных стали возможны недавние успехи в области машинного обучения.
Следующий момент: как именно данные проходят через вашу систему? Надежны ли ваши каналы/ETL? Где вы храните данные, легко ли к ним обращаться и анализировать? Джей Крепс (Jay Kreps) уже давно (примерно десять лет) всем твердит, что надежная передача данных – ключ к тому, чтобы делать с ними что угодно.
Только когда доступ к данным надежен, их можно исследовать и преобразовывать. Сюда относится и пресловутая «очистка данных» – недооцененная сторона науки о данных, о которой стоит написать отдельную статью. Этот процесс имеет место, когда вы обнаруживаете, что вам не хватает данных, датчики ненадежны, при смене версии сбросились все события или флаг распознается неправильно – и вы возвращаетесь к началу, чтобы убедиться в надежности основания пирамиды.
Когда вы научитесь надежно исследовать и очищать данные, можно переходить к следующему этапу, который часто называют бизнес-аналитикой: определять интересующие вас метрики, их сезонность и восприимчивость к различным факторам.
Можно провести грубую сегментацию пользователей и посмотреть, удастся ли получить какие-то результаты. Тем не менее, если вы хотите построить ИИ, сейчас вы создаете то, что позже станет элементом модели машинного обучения. Также на этом этапе вы уже знаете, что хотите предсказать или выучить, и можете начать готовить обучающую выборку – расставлять ярлыки либо автоматически (с помощью клиентов?), либо с участием людей.
На этом же этапе обычно находятся самые интересные тенденции в данных – но и об этом стоит поговорить отдельно в другой раз.
Хорошо, я умею считать. Что дальше?
У нас появились обучающие данные, можно уже наконец внедрять машинное обучение? Можно, если вы стремитесь предсказывать текучку клиентов внутри компании, и нельзя, если вы создаете продукт для клиентов. Нужно подготовить систему A/B-тестирования или методику экспериментов, чтобы избежать проблем при запуске и хотя бы примерно оценить последствия изменений до того, как они повлияют на всех.
Также это самое подходящее время для добавления элементарных исходных данных (например, для рекомендательных систем это будет «самое популярное», затем «самое популярное для нужной группы пользователей» – очень трудоемкий, но эффективный способ «стереотипизации перед персонализацией»).
Элементарные эвристические методы на удивление надежны, и с их помощью систему можно будет отладить от начала и до конца без таинственных «черных ящиков» машинного обучения с их гиперрегулируемыми гиперпараметрами. По этой же причине мой любимый алгоритм науки о данных – деление.
На этом этапе можно разворачивать простейший алгоритм машинного обучения (вроде логической регрессии или того же деления) и думать о новых сигналах и функциях, которые могут повлиять на результаты. Здесь мои фавориты – данные о погоде и переписях населения. И нет – несмотря на все возможности глубинного обучения, алгоритм не сможет сделать это автоматически. Введение новых сигналов (создание функций, а не их доработка) – вот что поможет вывести производительность вашей системы на новый уровень.
Стоит потратить на это больше времени, даже если мы как специалисты по данным спешим перейти на следующий уровень пирамиды.
Запускайте ИИ!
Вы это сделали. Вы снарядились в путь. Линии передачи данных отлажены. Данные организованы и избавлены от лишнего. Панели инструментов настроены, ярлыки расставлены и добавлены полезные функции. Измеряются верные параметры. Эксперименты можно проводить ежедневно. У вас есть базовый алгоритм, отлаженный с начала и до конца и работающий на постоянной основе, причем вы уже отредактировали его с десяток раз. Вы готовы.
Можно использовать самые новые и известные наработки, причем делать это самостоятельно или привлекать компании, которые специализируются на машинном обучении. Возможно, вы достигнете большого прогресса, или ничего не изменится.
- В худшем случае вы научились новым методам, сформировали собственное мнение, получили опыт и с чистой совестью можете отчитаться перед инвесторами и клиентами о своих экспериментах с ИИ.
- В лучшем случае вы добились значительных улучшений для ваших пользователей, клиентов и компании, и вашу историю успеха будут приводить как пример использования машинного обучения.
Подождите, а как же MVP, agile, бережливость и все остальное?
Иерархия потребностей науки о данных – не повод строить разрозненные и слишком запутанные системы каждый год. Точно так же при создании традиционного MVP (минимально жизнеспособного продукта) вы начинаете с небольшой упрощенной версии продукта и добиваетесь того, чтобы она работала.
Вы можете построить пирамиду, а затем развиваться по горизонтали. К примеру, в Jawbone мы начали с данных о сне и строили пирамиду для них: инструментарий, каналы передачи данных, чистка и организация, чтение и расшифровка ярлыков, метрики (сколько часов люди спят в среднем за ночь? Как считывать дневной сон? как определяется дневной сон?), кросс-сегментный анализ и дата-продукты на основе машинного обучения (автоматическое определение сна). Позже мы расширили этот алгоритм на обработку шагов, питание, погоду, тренировки, общение и социальные возможности – по одному параметру за раз.
Мы не создавали инфраструктуру сразу для всех параметров, не убедившись, что она вообще будет работать.
Задавать правильные вопросы и создавать нужные продукты
Этот пункт относится скорее к вашим возможностям, а не к тому, стоит ли вообще этим заниматься (по прагматическим или этическим соображениям).
Надежда на инструменты машинного обучения
«Подождите, но что насчет Amazon API, TensorFlow или других открытых библиотек? Что насчет компаний, которые продают инструменты машинного обучения или автоматически извлекают данные?»
Все это прекрасно и очень полезно. (Некоторым компаниям в итоге приходится мучительно перестраивать всю пирамиду за вас, чтобы их продукт заработал. Настоящие герои.) Тем не менее под влиянием нынешней популярности ИИ люди пытаются обрабатывать данные, полные лишней информации и пропусков, либо за долгое время их формат и значение меняется, либо эти данные еще не распознаны, или они структурированы так, что это не имеет смысла, но люди все равно надеются, что эти магические инструменты смогут выдать нужный результат.
Возможно, когда-нибудь все и будет так просто: уже сейчас специалисты делают шаги в этом направлении, которые достойны аплодисментов. Но пока что лучше заложить надежный фундамент для вашей пирамиды потребностей ИИ.
Материалы по теме:
Битва за данные: какие войны назревают за новую нефть
Вы уверены, что правильно понимаете потенциал ИИ?
Искусственный интеллект — причина, по которой нам конец?
Искусственный интеллект стал умнее человеческого. Что дальше?
Нашли опечатку? Выделите текст и нажмите Ctrl + Enter
Популярное
Налог на прибыль организаций
Материалы по теме
-
Пройти курс «Самое важное o 115-ФЗ»

- 1 Мода на апсайклинг: зачем производители одежды занимаются ее переработкой Успешный опыт Patagonia 14 января 18:23
- 2 «Хороший бизнес — это не только прибыль»: истории 14 компаний из списка B-Corp Они создают лучший мир 15 декабря 13:37
- 3 Что такое смарт-контракты и чем они так хороши Почему в смарт-контрактах нуждается корпоративный сектор. 24 августа 16:00
- 4 «В нас поверили простые люди»: от умирающего до инновационного бизнеса одно IPO Как из умирающего бизнеса мы превратились в инновационную компанию. 06 августа 13:58