Как искусственный интеллект помогает расшифровывать древние архивы Ватикана
Таким образом можно распознавать старинные тексты на любом языке
Исследователи использовали искусственный интеллект и распознавание изображений для расшифровки одной из самых больших коллекций рукописных текстов в мире.
Секретные архивы Ватикана представляют собой одну из величайших исторических коллекций рукописей в мире. В ней хранятся такие редкие документы, как папская булла об отлучении Мартина Лютера от церкви и просьбы о помиловании Марии Стюарт, которые она отправила Папе Римскому Сиксту V перед казнью.
Но к сожалению, большинство этих текстов бесполезны. Архивы Ватикана занимают площадь в 85,2 километра, и лишь несколько миллиметров коллекции было отсканировано и выложено в сеть. Еще меньше страниц было переведено в цифровой текстовый формат и стало доступно для поиска. Если вам нужно что-то другое, необходимо подать заявление на получение специального доступа, добраться до Рима и пролистать каждую страницу вручную.
Новый проект In Codice Ratio должен решить эту проблему. Исследователи планируют использовать искусственный интеллект и программу для оптического распознавания букв (OCR), чтобы изучить тексты архивов и перевести их в цифровой вид. Если им это удастся, ученые смогут расшифровать несметное количество исторических архивов мира.
Технология OCR уже давно используется для сканирования и распознавания текста в книгах и других печатных документах. Однако она не совсем подходит для материалов Секретных архивов. Традиционная технология разбивает слова на серии изображений отдельных букв — для этого она распознает межбуквенные интервалы. Затем она сравнивает изображение с буквами из своей памяти. Найдя лучшее соответствие, программа переводит букву в компьютерный код (ASCII) и таким образом включается функция поиска по тексту.
Подобный метод работает только для машинных, но не рукописных текстов. Большинство документов Ватикана написаны именно от руки. Вот, например, пример бумаги начала 1200 годов. Алгоритм не понимает, где заканчивается одна буква и начинается другая.
 Изображение: In Codice Ratio
Изображение: In Codice RatioНекоторые исследователи пытались научить OCR распознавать целые слова, а не буквы. Технически, такой метод должен сработать, ведь компьютерам неважно, что они обрабатывают. Но реализовать это решение оказалось очень сложно, потому что он требует гигантского запаса памяти. Системе необходимо знать не несколько десятков букв алфавита, а тысячи слов, а это значит, что для расшифровки архивов понадобится целая группа специалистов по средневековой латыни, которая будет сканировать изображения каждого слова в документах. Кроме того, все слова придется сканировать несколько раз, потому что из-за различного почерка писцов их изображения могут отличаться.
Создатели проекта In Codice Ratio решили разработать технологию OCR, которая будет разбивать слова не по буквам, а деталям начертания. Алгоритм будет изучать вертикальные и горизонтальные черточки и собирать из них возможные буквы, как головоломку.

Однако не всегда понятно, какие кусочки пазла действительно являются деталями буквы. Для этого ученые обратились к ученикам старших классов. Исследователи пригласили учащихся 24 итальянских школ, чтобы составить с их помощью банк памяти для программы. Школьники должны были зайти на сайт, где их ждал экран, поделенный на три секции:
 Фото: In Codice Ratio
Фото: In Codice RatioВ строке зеленого цвета были хорошие, четкие образцы текста на средневековой латыни (на примере показана буква g). В красной — так называемые ложные друзья, лишние пометки, не передающие на письме букву g. В нижней таблице показано ядро программы. Ученикам нужно было оценить качество попыток алгоритма распознать ту или иную буквы. Они должны сверять варианты, предлагаемые программой, с идеальным образцом в зеленой строке, и отмечать галочкой соответствия.
Таким образом учащиеся смогли обучить программу каждой из 22 букв средневекового латинского алфавита. При этом им не нужно было знать латынь, они просто искали схожие символы. Изучив их выбор, алгоритм стал экспертом в этой области. Ну, по крайней мере, частично.
Как оказалось, сбора визуальных головоломок оказалось недостаточно. В некоторых случаях написание букв и их сочетаний было слишком похожим. Например, в этом образце непонятно, что написал человек “clear” или “dear”, потому что рукописный вариант буквы “d” очень похож на “cl”.
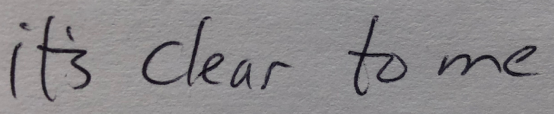 Изображение: Sam Kean
Изображение: Sam KeanА бывают и более сложные примеры, которые невозможно понять.
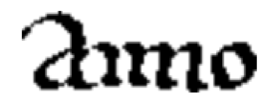
Было несколько вариантов — aimo, amio, aniio, aiino и даже aiiiio. Правильным оказался “anno”, слово, означающее на латыни «год». Программа смогла успешно распознать только буквы a и o, а четыре черточки между ними нет.
Для решения этой проблемы команда проекта решила научить программу думать. Исследователи взяли цифровую версию документа из 1,5 миллиона латинских слов и изучили в нем двух- и трехбуквенные комбинации. Затем они определили, какие комбинации случаются часто, а какие не происходят никогда. С помощью этих данных алгоритм смог рассчитать вероятность сочетания различных букв. В итоге программа поняла, что сочетание nn более вероятно, чем iiii.
Благодаря улучшениям алгоритм смог, наконец, самостоятельно распознать несколько текстов. Команда проекта дала ему на обработку несколько документов из архивов, среди которых есть письма европейским королям, приказы и прочие бумаги.
 Фото: Unsplash
Фото: UnsplashПервые результаты получились неоднозначными. Примерно треть слов в документах была распознана с ошибками. Чаще всего программа путала буквы m, n и i, а также f с архаичным удлиненным написанием s. Тем не менее 96% писем было расшифровано правильно. По словам одного из руководителей проекта, «даже неидеальная расшифровка может дать достаточно информации».
Как и любой искусственный интеллект, программа распознания древних текстов, будет совершенствоваться со временем по мере обработки большего количества материалов. И что самое прекрасное, технологии проекта In Codice Ratio можно будет легко адаптировать для расшифровки документов на разных языках.
Однако у этого метода есть ряд ограничений, утверждает Рега Вуд, историк философии и эксперт по древней письменности Индианского университета. Например, программе будет тяжело распознавать манускрипты, написанные не профессиональным писцом, а скопированные любителем, ведь почерк будет существенно отличаться. Кроме того, если речь идет о малых объемах текста, то быстрее и эффективнее будет расшифровать их вручную без применения такой технологии.
Материалы по теме:
SMM-гуру Папы Римского рассказал, как строится digital-стратегия Ватикана
Ватикан запускает «Синдер» для поиска ближайших мест для исповеди
Facebook разрабатывает технологию набора текста силой мысли
ABBYY научила смартфоны распознавать текст с предметов в реальном времени
-
Партнёрский материал Что сдерживает модернизацию ЖКХ: итоги отраслевой дискуссии на ПМЭФ 16 июня 2026, 15:52

-
Личное Дарио Амодеи. Как обыграть OpenAI и создать самый дорогой ИИ-стартап в мире 16 июня 2026, 12:05

-
Технологии Что сдерживает модернизацию ЖКХ: итоги отраслевой дискуссии на ПМЭФ 09 июня 2026, 12:14

-
Личное Из фарцовщика в создателя дизайн-завода Flacon: как Николай Матушевский дважды бросал свой бизнес и начинал с нуля 05 мая 2026, 12:09

-
Технологии Прощание с эпохой Кука и ставка на агентов: конференция Apple WWDC 2026 12 июня 2026, 15:35

-
Искусственный интеллект Как подключить Яндекс Дропс и использовать все функции Алисы AI: полный обзор первых ИИ-наушников от Яндекса 09 июня 2026, 11:00

-
Бизнес Отказ от завода и ставка на интеллект: как Катерина Карпова реанимировала PURE LOVE 02 марта 2026, 11:45

-
Технологии Уроки китайского единства 26 мая 2026, 13:27









-
Искусственный интеллект Разработчик DeepSeek увеличил свою оценку до $50 млрд — стартап стал самым дорогим ИИ-проектом в Китае 16 июня 2026, 16:00

-
Искусственный интеллект Конференция Conversations от Just AI в Петербурге: VK, Wildberries и другие расскажут, как зарабатывают на ИИ 16 июня 2026, 15:36

-
Россия 2ГИС запустил «Ленту друзей» — теперь пользователи могут увидеть отзывы и рекомендации мест от знакомых 16 июня 2026, 15:00

-
Реклама На первом месте идея: девелоперы выяснили, что рекламный бюджет — уже не главный фактор для узнаваемости бренда 16 июня 2026, 20:00

-
Маркетплейсы Ozon погасил 7,4 млн акций, выпущенных для мотивации сотрудников — компания устранила размытие капитала 16 июня 2026, 19:00

-
Деньги Состояние Илона Маска превысило $1,4 трлн — он стал самым богатым человеком на планете 16 июня 2026, 18:40

-
Деньги Минкультуры требует взыскать с «Союзмультфильма» 131 млн ₽: причина — студия не реализовала субсидию от ведомства 16 июня 2026, 17:57

-
Бизнес Альфа-Банк подвёл итоги первой программы для импортёров: шесть компаний получили гранты по 1 млн ₽ 15 июня 2026, 18:01








