Сохранить стабильность: как крупный бизнес сегодня преодолевает вызовы с помощью данных
Интервью с Данилой Наумовым, директором дата-офиса Группы М.Видео-Эльдорадо
Принято считать, что data-driven-компания — это компания, которая использует данные в своей работе. Но с этим не согласен Данила Наумов, директор дата-офиса Группы М.Видео-Эльдорадо, которая сейчас как раз находится в процессе перехода на более высокий уровень data-зрелости. Поговорили с ним о том, что такое data-driven-подход, как при нем происходит трансформация внутренних процессов и как управление данными поможет ритейлу преодолеть нынешний кризис.

Данила Наумов, директор дата-офиса Группы М.Видео-Эльдорадо
— Одна из целей М.Видео-Эльдорадо — перейти от process-driven-модели управления бизнесом к data-driven. В чем отличие этих подходов и почему первый проигрывает второму?
— Process-driven-модель предполагает, что компания автоматизирует и совершенствует внутренние процессы. Здесь в качестве наглядного примера можно привести фастфуд: процесс приготовления еды максимально отлажен, что позволяет быстро обслуживать большое количество людей. Минус в том, что в какой-то момент сотрудники покидают компанию и уносят с собой знания об организации внутренней кухни, которые потом можно использовать для создания похожего бизнеса.
А вот data-driven — это не просто компания, которая использует данные и принимает на их основе бизнес-решения. На мой взгляд, это та компания, которая извлекает из данных конкурентные преимущества, которые невозможно копировать. Вот к чему мы стремимся.
Например, в 2021 году мы сосредоточились на создании рекомендательных сервисов для клиентов на основе продвинутой аналитики. Разработанные алгоритмы анализируют взаимодействие авторизованных клиентов с каталогом, историю покупок, просмотров, поиска и брошенных корзин. Собранные данные ложатся в основу персональных товарных рекомендаций. Так мы можем определить склонность пользователей к покупке, потребность в различных категориях техники, предпочтения в ценовых сегментах и брендах.
Модели на основе машинного обучения автоматически прогнозируют различные сценарии поведения пользователей и рекомендуют для каждого из них наиболее предпочтительные предложения. Товарные рекомендации реализованы на сайте, в мобильном приложении покупателя и продавца на всех основных этапах пути к покупке: главная страница, поиск, карточка товара, корзина по нескольким сценариям: «хиты», «новинки», «в тренде», аксессуары, похожие и сопутствующие товары. На товары из «умных» подборок приходится до 20% оборота приложения и четверть покупок.
— В какой момент появилась потребность в этом переходе и каких целей компания хочет достичь с помощью data-driven-модели управления?
— Обычно ритейлеры оцифровывают клиентский опыт и используют эти данные только в онлайне, мы же нашли способ делать это и в офлайне с помощью мобильного приложения продавца. Как это работает?
Посетитель заходит в магазин, к нему подходит консультант и, прежде чем продолжить диалог о цели визита, предлагает авторизоваться по номеру телефона. Так консультант получает доступ к профильной информации о клиенте, истории покупок, корзине, доступным бонусам и персональным предложениям. Вместе с клиентом он проходит весь путь от выбора до покупки через свой смартфон, который на любом из этапов может быть синхронизирован с личным кабинетом клиента на его смартфоне или компьютере.
Этот массив информации о поведении клиентов онлайн и в рознице Группа использует во множестве различных сценариев для улучшения процессов и создания новых клиентских и бизнес-продуктов. И если раньше data-driven-подход был одной из опор стратегии роста бизнеса, то сегодня он стал основой преодоления кризиса за счет более точного планирования и управления логистикой, маркетинговой активностью, товарными запасами и ассортиментом в условиях нестабильного рынка и быстро меняющихся условий.
— Что отличает data-driven-компанию? Какие последовательные действия нужны, чтобы перестроить бизнес?
— Есть несколько методологий по оценке data-зрелости компаний. Например, Университет Карнеги — Меллона выделяет пять уровней зрелости. Первый — когда обмен данными осуществляется посредством различных файлов, отправляемых по электронной почте или через расшаренную папку. Второй — когда обмен данными происходит через хранилище. Третий — через data-каталог. Четвертый — когда проведена некая виртуализация данных. И пятый — когда внедрены все процессы по управлению данными и идет их оптимизация.
Согласно этой методологии, только две или три компании в мире достигли пятого уровня зрелости. Но компанию вполне можно считать data-driven, когда она находится на третьем уровне.
Чтобы стать data-driven, компании нужно создать стратегию по управлению данными, внедрить процессы оценки качества данных, стандартизировать операции с данными, создать архитектуру и платформу данных. Это если говорить в общем: в зависимости от уровня и стратегии для каждой компании будет свой набор шагов для перехода на следующую ступень.
Подчеркну, что перестраивать бизнес не надо — надо развивать процессы, потому что любой процесс строится вокруг данных. И важно, что data-стратегия должна быть неотрывной от стратегии самого бизнеса, а подходы к процессам — от внутренней структуры компании.
— На каком уровне зрелости сейчас находится М.Видео-Эльдорадо?
— Сейчас мы находимся где-то на втором уровне data-зрелости, а до конца первого квартала 2023 года хотим перейти на третий. Чтобы отслеживать прогресс, планируем каждый год проводить оценку. Мы опрашиваем более 50 руководителей ключевых функций и их ближайших подчиненных. Потом на основе ответов коллег формируем набор их «болей» и ожиданий, чтобы нарисовать стратегическую карту по достижению более высокого уровня.
— Эта трансформация как-то отражается на клиентах?
— Конечно, в первую очередь они получают персонализированный опыт взаимодействия с компанией благодаря сервисам, основанным на данных. Это облегчает поиск и выбор нужных товаров, комплексно решает их задачи с точки зрения выбора аксессуаров и сопутствующих товаров, привлекает внимание к релевантным коммуникациям и спецпредложениям.
Более того, компания стремится постоянно повышать качество обслуживания с помощью дата-инструментов. В клиентской поддержке мы развиваем чат-бота, который консультирует клиентов. Речевые технологии сокращают время ответа на запросы и повышают уровень удовлетворенности клиентов до 95%.На сайте, в приложении и наиболее популярных мессенджерах робот отвечает на вопросы о статусе заказа, доставки, наличии товара, правилах акций и программы лояльности, а также рекомендует товары в разных категориях.
В офлайне тоже есть место для анализа — внутри нашего дата-офиса была разработана система видеоаналитики. Нейросеть обрабатывает видеопоток с камер магазина и выявляет очередь у кассы или «одиноких покупателей». Первым рабочим сценарием стала помощь клиентам, которые некоторое время стоят или перемещаются по торговому залу в поисках консультанта. Уведомление о таких клиентах оперативно поступает в чат-бот магазина, после чего свободный консультант подходит и оказывает персонализированную помощь.
— Расскажите, как устроен data-офис в компании.
— Порядка 100 сотрудников data-офиса задействованы в работе разных команд — всего около 20 продуктов. Мы также поддерживаем большое количество бизнес-продуктов, которые уже используют алгоритмы машинного обучения для оптимизации деятельности, — это продукты коммерческой дирекции, такие как ассортиментное планирование, ценообразование, промопланирование — сервисы, которые влияют на наших клиентов, определяя, какие товары будут стоять на полках, какие попадут в промо и по какой цене.
Есть сервисы рекомендательной системы и инструменты персонализации (они подскажут, какие наушники или часы подойдут к вашему смартфону, какую стиральную машину с похожими характеристиками доставят быстрее или какой ТВ с большей диагональю и качеством картинки доступен за те же деньги), есть продукт по расчету оптимального количества посадочных мест в магазинах, чат-бот, платформа обратной связи, видеоаналитика, товарные рекомендации, которые появляются в чат-боте.
И есть ряд наших внутренних продуктов: первый — это data-платформа, которая представляет собой набор связанных компонент для закрытия потребности внутренних пользователей по работе с данными; это продукт data governance, который призван обеспечить управление данными в нашей компании как активом, и набор инструментов по автоматизации и встраиванию моделей машинного обучения в бизнес-продукты.
Сейчас мы перешли на гибридный формат взаимодействия продуктовых команд и дата-специалистов. Те домены, которым бизнес-кейс позволяет иметь фултайм сотрудников по нашей специализации, будут работать по модели sourcing. А доменам, у которых бюджет сократился, но потребности в каких-то дата-элементах все равно есть, мы будем предлагать сервисную модель, где сервис предоставляет централизованное подразделение, которое находится в нашей структуре data-офиса.
— Изменилась ли ваша стратегия работы с данными за последние несколько месяцев?
— Раньше мы фокусировались на масштабируемости бизнеса, сейчас наша ключевая цель — поддержание стабильности. И есть несколько вызовов, с которыми мы столкнулись и с которыми можно эффективно работать с помощью дата-анализа.
Например, поставки товара. Некоторые крупные поставщики приостановили работу, некоторые испытывают проблемы с логистикой, многие меняют условия работы, привычные для рынка многолетние практики.
Тем не менее, нам необходимо обеспечивать достойный ассортимент в магазинах, способный удовлетворить покупательский спрос в условиях волатильности рубля и ежедневной потребности россиян в технике. Появляется задача повышать оборачиваемость товаров, то есть предлагать покупателям именно то, что им нужно по характеристикам и цене, чтобы товар не задерживался на полках и складах.
Поэтому сейчас мы переходим на «гибкие» матрицы — инструмент, эффективный при низкой предсказуемости поставок. Если раньше мы формировали ассортиментную матрицу на уровне конкретных моделей техники, исходя из размера магазина и его премиальности — расположения, размера, окружения, то сегодня нам важнее, чтобы ассортимент закрывал как можно больше потребностей покупателя: например, чтобы в наличии обязательно был именно двухкамерный холодильник с нижней морозильной камерой определенного объема и ценового сегмента.
Эту механику мы уже использовали в периоды рыночной дестабилизации, но уже не просто вручную распределяем имеющийся сток, а опираемся на глубинный анализ и автоматические рекомендации, что делает «гибкий» формат работы более эффективным. С помощью дата-инструментов мы выявляем потребности на основе товарных характеристик, кластеризуем магазины и формируем под каждый кластер приоритетный и альтернативный ассортимент и логистические цепочки, исходя из того объема товаров, который есть в наличии или поставки которого уже подтверждены производителями.
— А как работали до этого?
— Раньше мы больше опирались на ассортимент и маркетинговое позиционирование брендов. Сеть М.Видео закрывала премиальный сегмент, поэтому там был фокус на топовые бренды, новинки. Эльдорадо фокусировалась на качественной доступной технике, отвечающей повседневному спросу.
Сейчас же мы перешли к тщательному отслеживанию продаж в штуках и ширины, то есть общего количества товаров, как максимального ограничения. Мы использовали новый подход к расчету целевой ширины ассортимента, который можем поставить в каждом конкретном магазине: сначала все магазины кластеризовали по количеству продаж в штуках, потом определили для каждой товарной группы целевую оборачиваемость.
Дальше мы рассчитали, как количество выставленных моделей, например, тех же холодильников, которые у нас в наличии, влияет на объем продаж этой категории. В итоге получили целевую оборачиваемость и зависимость продаж от ширины матрицы. Таким образом, получилось подобрать оптимальную ширину матрицы, которая позволит достигнуть целей по стабилизации бизнеса.
— Расскажите, как это работает, на конкретном примере.
— Давайте возьмем многодверные холодильники side-by-side.
Эти модели все более популярны, и нам важно, чтобы они как вид присутствовали в каждом магазине. Их представленность должна, с одной стороны, максимально задействовать то, что компания закупила и получила в рамках поставок, а с другой – быть достаточной, чтобы покупатель мог посмотреть варианты и сделать выбор, но не создавать «долгие» запасы, возможно, эти модели нужны и в других магазинах.
Метрика, которая позволяет отслеживать, насколько эффективно ритейлер работает с товарами – это оборачиваемость, т.е. сколько времени товар проводит у ритейлера с момента отгрузки на склад до продажи. У разных категорий она разная, для крупной техники – несколько недель это норма, но мы хотим улучшить этот показатель, т.е. сделать так, чтобы все наши поставки максимально быстро попадали к клиентам.
Каждая точка на графике — отдельный магазин с продажами (по Х — среднемесячные продажи этого магазина, по У — среднемесячный сток). Когда мы делим сток на продажи, мы получаем оборачиваемость — время, за которое мы оборачиваем товар.
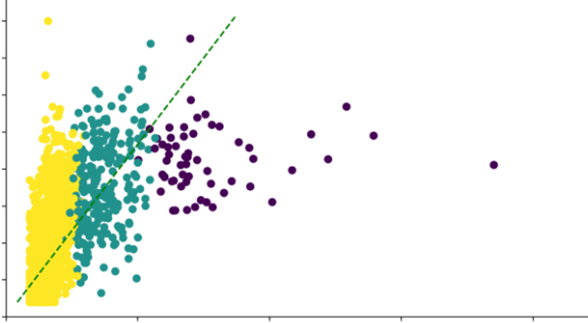
Оборачиваемость
Видно, что некоторые магазины продают быстрее, некоторые медленнее, по цветам они поделены по кластерам на основе штучных продаж.
Внутри каждого кластера мы определяем, насколько большой ассортимент предлагает магазин (по Х — отношение продаж уникальных товаров к их наличию на стоке). То есть получается, что есть магазины, которые продают больше 100 единиц холодильников в месяц и при этом задействуют все представленные в зале модели, а есть магазины, которые продают те же 100 штук и выше, но продажи приходятся только на половину выставленного ассортимента, а остальная половина лежит мертвым грузом.
_lItMWVa.png)
Отношение продаж уникальных товаров к стоку
Для каждого кластера мы построили модель машинного обучения, которая прогнозирует продажи в штуках в зависимости от ряда факторов, включая ширину матрицы. На основе этого прогноза мы понимаем, как будут расти или падать продажи при изменении ширины матрицы. Например, видно, что в подкластере 3 при хранении определённого количества моделей холодильников наступает плато, насыщение спросом, и дальнейшее расширение ассортимента не приводит к росту продаж, а товар просто оседает в магазине.
_XPcO0FE.png)
Прогноз динамики продаж в зависимости от ширины матрицы
Затем мы создали рекомендательную систему, ассортиментный оптимизатор, который говорит, как изменение количества моделей повлияет на целевую оборачиваемость, продажи в штуках и сток. То есть где-то у нас есть потенциал для расширения и мы можем расширяться, чтобы продажи увеличились, а где-то мы должны ширину снизить, чтобы улучшить оборачиваемость. Этот же инструмент определяет и наполнение этой ширины конкретными товарами. В него на входе попадает количество посадочных мест, которое может быть в этом магазине, а также данные о товарных запасах и поставках.
В результате выравнивается присутствие холодильников по магазинам, где одни должны были быть, и растёт оборачиваемость. Если смотреть глазами покупателя – то тысячи клиентов получают нужный им холодильник в нужной ценовой категории.
На основе этих данных оптимизатор ежедневно формирует рекомендацию из 100 тысяч наименований, показывает, что надо поставить на полку, а также предлагает приоритетные альтернативы.
— Сейчас data-driven-подход в основном внедряют крупные компании — у них есть для этого возможности. Как быть небольшому бизнесу? Оправдан ли для него переход?
— Конечно. Просто уровень data-зрелости в крупных и маленьких компаниях будет разным, и здесь нужно быстро сформировать набор приоритетных шагов, которые дадут максимальный выхлоп за минимальную стоимость.
— Что посоветуете компаниям, которые стремятся стать data-driven?
— Я бы советовал меньше думать и больше делать, больше экспериментировать и изучать опыт других компаний — благо сейчас информации в открытых источниках очень много. И конечно, не бояться совершать ошибки.
Фото на обложке: Yurchanka Siarhei /
-
Партнёрский материал Онлайн-инкассация: как превратить наличную выручку в рабочий капитал 01 июня 2026, 10:00

-
Личное Лэй Цзюнь. Как создатель Xiaomi заработал 30,4 млрд $ на дешёвых смартфонах 13 июля 2026, 20:56

-
Личное Фёдор Овчинников: «Пять месяцев в тундре — путешествие в другое измерение» 14 мая 2026, 13:18

-
Бизнес Екатерина Лапшина: «У меня всегда был чуть больший аппетит к риску» 07 мая 2026, 16:10

-
Бизнес Не из гаража, а почти из холодильника: история Geely 01 июля 2026, 14:58

-
Бизнес «Русские шрифты скачать». Как зарабатывают шрифтовые студии в России 03 июля 2026, 12:00

-
Технологии Александр Пьянов, «Яндекс Драйв»: «Мы готовы стать агрегатором для всего рынка каршеринга» 08 апреля 2026, 12:26

-
Автомобили От гоночной трассы до «Матрицы»: история Ducati 10 июля 2026, 23:39









-
Кибербезопасность Число DDoS-атак выросло на 45% в 2026 году — впервые на одного клиента приходится свыше 10 тыс. инцидентов в месяц 15 июля 2026, 21:00

-
Маркетплейсы Минэк предложил разрешить продавцам переносить карточки товаров между маркетплейсами — Wildberries и Ozon против 15 июля 2026, 20:30

-
Технологии Samsung вновь стала лидером на мировом рынке смартфонов — благодаря новому флагману Galaxy S26 Ultra 15 июля 2026, 18:50

-
Россия Билеты на музыкальные фестивали за год подорожали на 21% — при этом число мероприятий сократилось почти на треть 15 июля 2026, 18:25

-
IT За 2026 год домашний интернет в России подорожал на 10–20% — операторы объясняют это ростом расходов 15 июля 2026, 17:40

-
Искусственный интеллект OpenAI может представить свою первую умную колонку уже в 2026 году — устройство будет использовать ChatGPT 15 июля 2026, 17:20

-
Карьера Зумеры и бумеры по-разному смотрят на карьерный успех: молодому поколению важнее доход, старшему — стабильность 15 июля 2026, 19:10

-
Бизнес Виртуальный оператор Сбера может перейти на сеть «Вымпелкома» — тогда Билайн станет основным партнером компании 15 июля 2026, 15:40








